想让机器人替你聊天?1小时手把手训练一个克隆版的你

聊天机器人到底是什么呢?说白了,就是计算机程序通过听觉或文本方法进行对话。
当今最流行的四个对话机器人是:苹果的Siri、微软Cortana、谷歌助理、亚马逊的Alexa。他们能够帮你查比分、打电话,当然,偶尔他们也会出错。
本文,我们主要会详细介绍聊天机器人在文本方面的运作。
在这篇文章中,我们将看到如何使用深度学习模型训练聊天机器人用我们所希望的方式在社交媒体上进行对话。
意图&深度学习
如何训练一个高水平的聊天机器人呢?
高水平的工作聊天机器人是应当对任何给定的消息给予最佳反馈。这种“最好”的反应应该满足以下要求:
回答对方问题
反馈相关信息
问后续问题或用现实方法继续对话
这三个方面是机器人表现出来的内容,而隐含其中没有表现出来的则是一系列流程:理解发送者的意图,确定反馈信息的类型(问一个后续问题,或者直接反应等),并遵循正确的语法和词法规则。
请注意,“意图”二字至关重要。只有明确意图,才能保证在后续流程的顺利进行。对于“意图”,读者通过本篇文章,将会看到,深度学习是最有效的解决“意图”问题的方法之一。
深度学习的方法
聊天机器人使用的深度学习模型几乎都是 Seq2Seq。2014年,Ilya Sutskever, Oriol Vinyals, and Quoc Le 发表了《Sequence to Sequence Learning with Neural Networks》一文。摘要显示,尽管机器翻译已经做的很好,但Seq2Seq却模型能更好的完成各种各样的NLP的任务。

Seq2Seq模型由两个主要部件组成,一个是编码器RNN,另一个是解码器RNN。从高层次上来说,编码器的工作是将输入文本信息生成固定的表示。解码器则是接收这个表示,并生成一个可变长度的文本,以响应它。
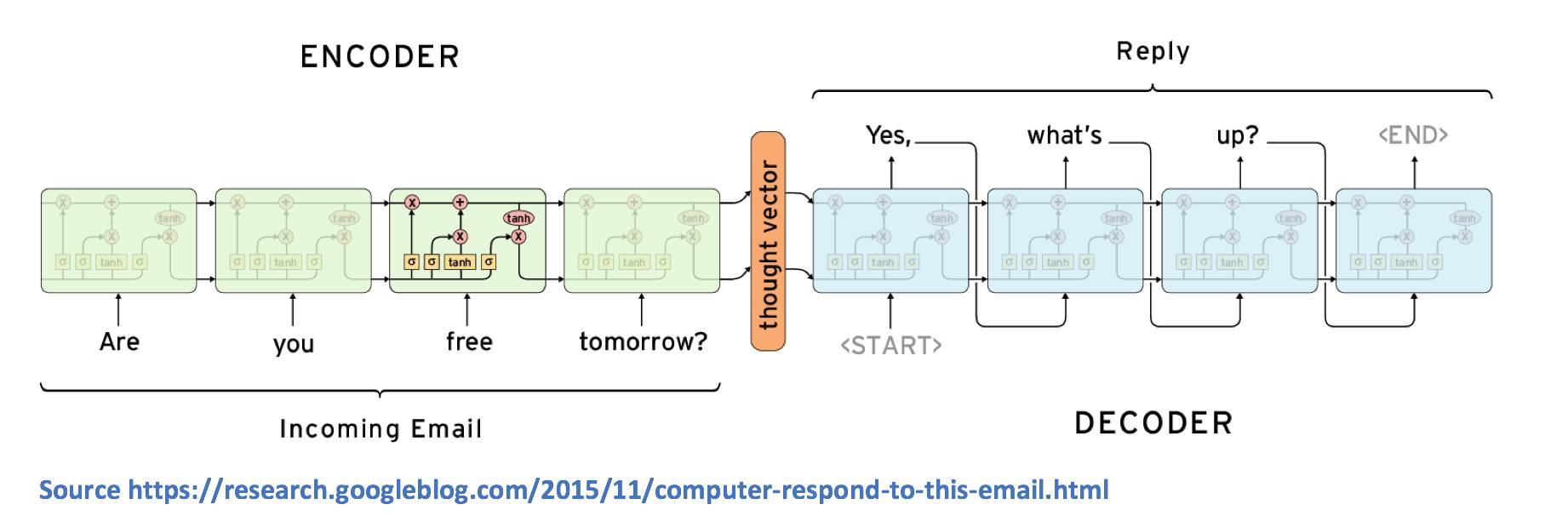
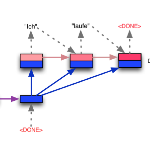
让我们来看看它是如何在更详细的层次上工作的。
正如我们所熟知的,编码器RNN包含了许多隐藏的状态向量,它们每个都表示从上一次时间步骤中获取的信息。例如,在第3步序中的隐藏状态向量是前三个单词的函数。通过这个逻辑,编码器RNN的最终隐藏状态向量可以被认为是对整个输入文本的一种相当精确的表示。
而解码器RNN负责接收编码器的最后隐藏状态向量,并使用它来预测输出应答的单词。让我们看看第一个单元。该单元的工作是使用向量表示v,并决定其词汇表中哪个单词是最适合输出响应的。从数学上讲,这就意味着我们计算词汇中的每一个单词的概率,并选择值的极大似然。
第二单元是向量表示v的函数,也是先前单元的输出。LSTM的目标是估计以下条件概率。
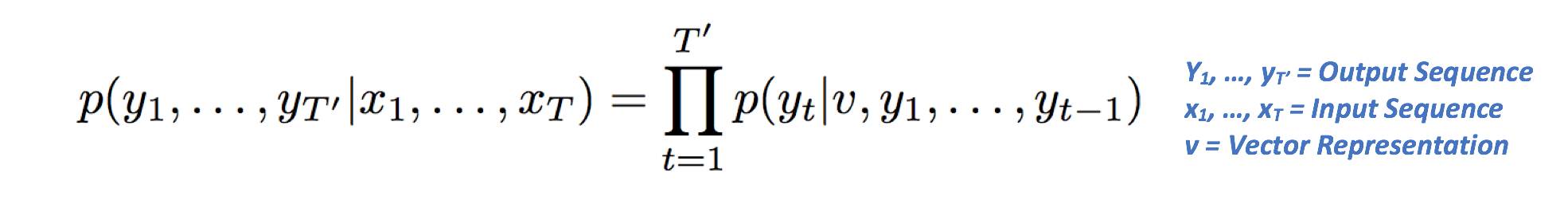
让我们来解构这个方程式意味着什么。
左侧指的是输出序列的概率,这取决于给定输入序列。
右侧包含p(yt | v,y1,…,yt),它是所有单词的概率向量,条件是在前一步的向量表示和输出的情况下。其中pi等价于西格玛(或累计求和)的乘法。则右侧可降为p(Y1 | V)*p(y2 | v,y1)*p(Y3 | v,y1,y2)
在继续之前,让我们先做一个简单的例子。
让我们在第一张图片中输入文本:“你明天有空吗?”
大多数人都会怎么回答呢?一般都会用“yes”、“yeah”、“no”开始。
在我们完成了网络训练之后,概率p(Y1 | V)将是一个类似于下面的分布。

再来看我们需要计算的第二个概率,p(y2 | v,y1)表是一个函数,词的分布y1以及向量的表示结果v,而pi将产生最终结果并作为我们的最终反应。
Seq2Seq模型的最重要特性之一是它提供的多功能性。当你想到传统的ML方法(线性回归,支持向量机)和深等深学习方法时,这些模型需要一个固定的大小输入,并产生固定大小的输出。但是输入的长度必须事先知道。这是对诸如机器翻译、语音识别和问答等任务的一个很大的限制。这些任务我们都不知道输入短语的大小,我们也希望能够生成可变长度响应,而不仅仅局限于一个特定的输出表示。而Seq2Seq模型允许这样的灵活性!
自2014以来,Seq2Seq模型已经有了很多改进,你可以在这篇文章结尾“相关论文”部分中阅读更多关于Seq2Seq的文章。
数据集的选择
在考虑将机器学习应用于任何类型的任务时,我们需要做的第一件事都是选择数据集,并对我们需要的模型进行训练。对于序列模型,我们需要大量的会话日志。从高层次上讲,这个编码器-解码器网络需要能够正确理解每个查询(编码器输入)所期望的响应类型(解码器输出)。
一些常见的数据集包括:康奈尔电影对话语料库、ubuntu语料库和微软的社交媒体对话语料库。
虽然大多数人都在训练聊天机器人来回答具体信息或提供某种服务,但我更感兴趣的是更多的有趣的应用程序。有了这篇文章,我想看看我是否可以用我自己的生活中的对话日志来训练一个Seq2Seq的模型来学习对信息的反应。
获取数据

我们需要创建一个大量的对话数据,在我的社交媒体上,我使用了Facebook、Google Hangouts、SMS、Linkedin、Twitter、Tinder和Slack 等着与人们保持联系。
Facebook:这是大部分培训数据的来源。facebook有一个很酷的功能,让你可以下载你所有的Facebook数据。包含所有的信息、照片、历史信息。
Hangouts:您可以根据这个文章的指示来提取聊天数据
https://blog.jay2k1.com/2014/11/10/how-to-export-and-backup-your-google-hangouts-chat-history/
SMS:可以快速获得所有之前的聊天记录(sms备份+是一个不错的应用程序),但我很少使用短信。
Linkedin:Linkedin确实提供了一种工具,可以在这里获取数据的归档。
https://www.linkedin.com/start/join?session_redirect=https%3A%2F%2Fwww.linkedin.com%2Fpsettings%2Fmember-data
Twitter:这其中没有足够的私人信息。
Tinder:这其中的对话不是数据集。
Slack:我的Slack刚刚开始使用,只有几个私有消息,计划手动复制。
创建数据集
数据集的创建是机器学习的一个重要组成部分,它涉及到数据集预处理。这些源数据存档格式不同,并且包含我们不需要的部分(例如,fb数据的图片部分)。
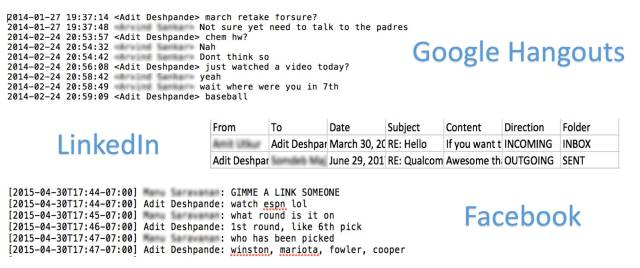
正如您所看到的,Hangouts数据的格式与facebook数据有一点不同,而linkedin的消息以csv格式进行。我们的目标是使用所有这些数据集来创建一个统一的文件,命名为(FRIENDS_MESSAGE,YOUR_RESPONSE)
为了做到这一点,我编写了一个python脚本,可以在这里查看
https://github.com/adeshpande3/Facebook-Messenger-Bot/blob/master/createDataset.py
此脚本将创建两个不同的文件。其中一个是Numpy对象(conversationDictionary.npy)包含所有输入输出对。另一个是一个大的txt文件(conversationData.txt)包含这些输入输出对的句子形式,一个对应一个。通常,我喜欢共享数据集,但是对于这个特定的数据集,我会保持私有,因为它有大量的私人对话。这是最后一个数据集的快照。

词向量
LOL,WTF,这些都是在我们的会话数据文件中经常出现的所有单词。虽然它们在社交媒体领域很常见,但它们并不是在很多传统的数据集中。通常情况下,我在接近NLP任务时的第一个直觉是简单地使用预先训练的向量,因为它们能在大型主体上进行大量迭代的训练。
为了生成单词向量,我们使用了word2vec模型的经典方法。其基本思想是,通过观察句子中单词出现的上下文,该模型会创建单词向量。在向量空间中,具有相似上下文的单词将被置于紧密的位置。关于如何创建和训练word2vec模型的更详细的概述,请查看我的一个好友Varma罗汉的博客。
https://github.com/adeshpande3/Facebook-Messenger-Bot/blob/master/Word2Vec.py
*更新:我后来了解到TensorFlow Seq2Seq函数从零开始对单词embeddings进行训练,因此我不会使用这些单词向量,尽管它们仍然是很好的实践*
用TensorFlow创建Seq2Seq模型
现在我们创建了数据集并生成了我们的单词向量,我们就可以继续编码Seq2Seq模型了。我在python脚本中创建和训练了模型
https://github.com/adeshpande3/Facebook-Messenger-Bot/blob/master/Seq2Seq.py
我试着对代码进行评论,希望你能跟着一起。该模型的关键在于TensorFlow的嵌入_RNN_seq2seq()函数。你可以在这里找到文档。
https://www.tensorflow.org/tutorials/seq2seq
跟踪培训进展
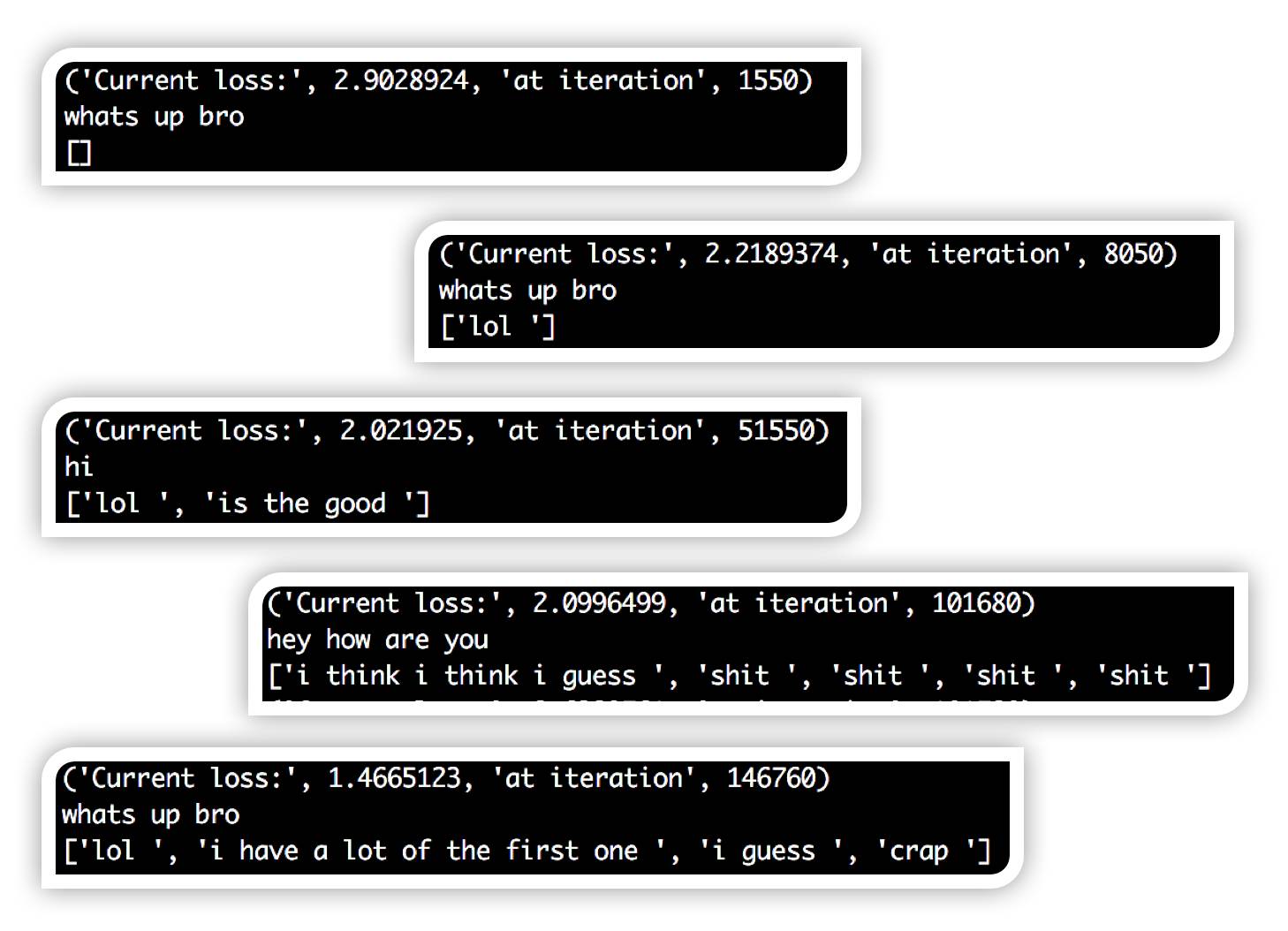
这个项目的一个有趣的地方是,能看到网络训练时,响应是如何发生变化的。训练回路中,我在输入字符串上测试了网络,并输出了所有非pad和非eos口令。
首先,您可以看到,响应主要是空白,因为网络重复输出填充和eos口令。这是正常的,因为填充口令是整个数据集中最常见的口令。
然后,您可以看到,网络开始输出“哈哈”的每一个输入字符串。
这在直觉上是有道理的,因为“哈哈”经常被使用,它是对任何事情都可以接受的反应。慢慢地,你开始看到更完整的思想和语法结构在反应中出现。现在,如果我们有一个经过适当训练的Seq2Seq模型,那么就可以建立facebook messenger 聊天机器人
建立一个fb messenger Chatbot
这个过程并不是太难,因为我花了不到30分钟的时间来完成所有步骤。基本的想法是,我们使用简单的express应用程序建立了一个服务器,在Heroku上安装它,然后设置一个facebook页面连接。但最终,你应该有一个类似这样的 Facebook 聊天应用程序。
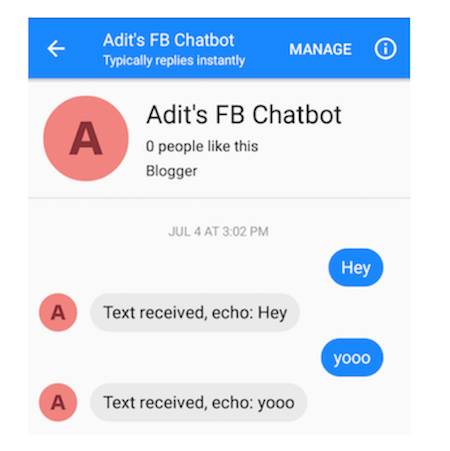
您可以向您的聊天机器人发送消息(这种初始行为只是响应它所发送的所有内容)。
部署训练有素的TensorFlow模型
现在是时候把一切都放在一起了。由于tensorflow和node之间还没有找到一个很好的接口(不知道是否有一个官方支持的包装器),所以我决定使用slack服务器部署我的模型,并让聊天机器人的表达与它进行交互。您可以在这里查看slack服务器代码
https://github.com/adeshpande3/Chatbot-Flask-Server
以及聊天机器人的index.js文件
https://github.com/adeshpande3/Facebook-Messenger-Bot/blob/master/index.js
测试它!
如果你想和这个机器人聊天,那就继续点击这个链接
https://www.messenger.com/
或者点击facebook页面,发送消息
https://www.facebook.com/Adits-FB-Chatbot-822517037906771/
第一次响应可能需要一段时间,因为服务器需要启动。
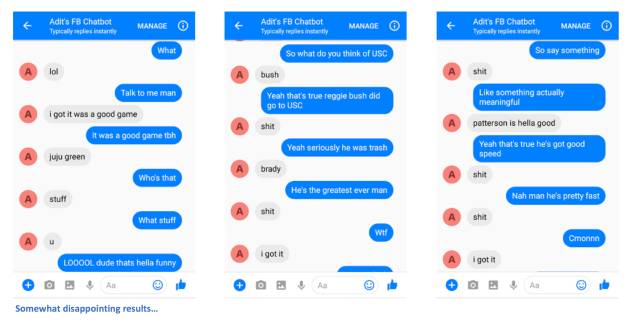
也许很难判断机器人是否真的像我那样说话(因为没有很多人在网上和我聊天),但是它做的很好!考虑到社会媒体标准,语法是可以通过的。你可以选择一些好的结果,但大多数都是相当荒谬的。这能帮助我在晚上睡得更好的,毕竟不能在任何时间用skynet。
改进方法
从与chatbot的交互中可以看到的改进方法,有很大的改进空间。经过几条信息后,很快就会明白,不仅仅是进行持续的对话就行了。chabtot不能够把思想联系在一起,而一些反应似乎是随机的、不连贯的。下面是一些可以提高我们聊天机器人性能的方法。
合并其他数据集,以帮助网络从更大的会话语料库中学习。这将消除聊天机器人的“个人特性”,因为它现在已经被严格训练了。然而,我相信这将有助于产生更现实的对话。
处理编码器消息与解码器消息无关的场景。例如,当一个对话结束时,你第二天就开始一个新的对话。谈话的话题可能完全无关。这可能会影响模型的训练。
使用双向LSTMs,注意机制和套接。
优化超参数,如LSTM单元的数量、LSTM层的数量、优化器的选择、训练迭代次数等。
建立像你一样的Chatbot
如果你一直在跟进,你应该对创建一个聊天机器人所需要的东西已经有了一个大致的概念。让我们再看一遍最后的步骤。在GitHub repo 中有详细的说明。
https://github.com/adeshpande3/Facebook-Messenger-Bot/blob/master/README.md
找到所有你与某人交谈过的社交媒体网站,并下载你的数据副本。
从CreateDataset中提取所有(消息、响应)对py或您自己的脚本。
(可选)通过Word2Vec.py为每一个在我们的对话中出现的单词 生成单词向量。
在Seq2Seq.py中创建、训练和保存序列模型。
创建Facebook聊天机器人。
创建一个Flask服务器,在其中部署保存的Seq2Seq模型。
编辑索引文件,并与Flask服务器通信。
最后给大家贡献一些可供查阅的资源:
相关论文
Sequence to Sequence Learning
https://arxiv.org/pdf/1409.3215.pdf
Seq2Seq with Attention
https://arxiv.org/pdf/1409.0473.pdf
Neural Conversational Model
https://arxiv.org/pdf/1506.05869.pdf
Generative Hierarchical Models
https://arxiv.org/pdf/1507.04808.pdf
Persona Based Model
https://arxiv.org/pdf/1603.06155.pdf
Deep RL for Dialogue Generation
https://arxiv.org/pdf/1606.01541.pdf
Attention with Intention
https://arxiv.org/pdf/1510.08565.pdf
Diversity Promoting Objective Functions
https://arxiv.org/pdf/1510.03055.pdf
Copying Mechanisms in Seq2Seq
https://arxiv.org/pdf/1603.06393.pdf
其他有用的文章
Seq2Seq的优秀博文
http://suriyadeepan.github.io/2016-06-28-easy-seq2seq/
斯坦福大课程PPT
http://web.stanford.edu/class/cs20si/lectures/slides_13.pdf
Tensorflow Seq2Seq
https://www.tensorflow.org/tutorials/seq2seq
使用Tensorflow Seq2Seq函数的视频教程
https://www.youtube.com/watch?v=ElmBrKyMXxs

CSDN AI热衷分享 欢迎扫码关注