AI从业者必须了解的决策树指南

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
决策树是一种功能非常强大的机器学习模型,能够在许多任务中实现高精度,同时具有高可解释性。决策树在机器学习模型领域的特殊之处,在于其信息表示的清晰度。决策树通过训练获得的 “知识”,直接形成层次结构。这种结构以这样的方式保存和展示知识,即使是非专家也可以很容易地理解。
你很可能在自己的生活中,使用过决策树来做出决定。比如说,你决定这个周末应该做什么活动。这可能取决于你是想和朋友一起出去玩儿还是独自过周末;在这两种情况下,你的决定还取决于天气。如果天气晴朗,并且朋友也有空,你可能想踢足球。如果最后下雨的话,你就去看电影。如果你朋友根本不来,那么,无论天气如何,你都会喜欢去打电竞游戏。
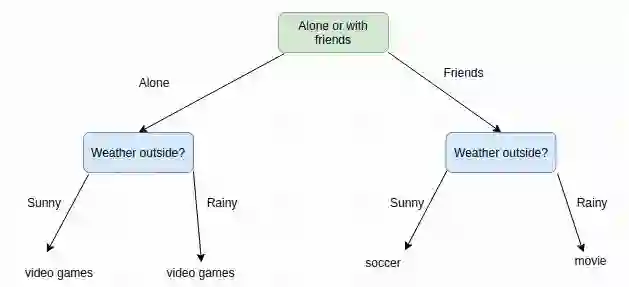
这就是一则真实的决策树的例子。我们构建了一棵树来模拟一组顺序的、层次化的决策,这些决策最终会导致一些最终结果。请注意,为了保持树的较小规模,我们还选择了相当 “高级” 的决策。例如,如果我们为天气设置了许多可能的选项,如:25 度的晴天、25 度的雨天、26 度的晴天、26 度的雨天、27 度的晴天…… 等等,这样我们的树很快就会变得很大!确切 的温度真的不太重要,我们只是想知道是否可以外出。
在机器学习中,决策树的概念也是一样的。我们想要构建一棵树,这棵树有一组层次化的决策,这些决策最终会给我们一个最终的结果,即分类或回归预测。在选择决策时,尽可能让树的规模较小,同时以实现高分类 / 回归准确性为目标。
决策树模型的创建,使用了两个步骤:归纳和修剪。归纳是我们实际构建树的方法,即根据我们的数据设置所有的层次决策边界。由于训练决策树的性质,它们很容易出现严重的过拟合。而修剪是从决策树中删除不必要的结构的过程,有效地降低了克服过拟合的复杂性,并使其更容易解释。
从更高的层次来看,决策树归纳需要经过 4 个主要步骤来构建树:
从训练数据集开始,它应该具有一些特征变量和分类或回归输出。
确定数据集中的 “最佳特征”,以便对数据进行分割;稍后我们将详细介绍如何定义 “最佳特征”。
将数据拆分包含此最佳特征的可能值的子集。这种拆分基本上定义了树上的节点,即每个节点都是基于我们数据中某个特征的拆分点。
通过使用从步骤 3 创建的数据子集递归地生成新的树节点。我们不断地拆分,直到我们在某种程度上,优化了最大的准确率,同时最小化拆分 / 节点的数量。
步骤 1 很简单,只需获取你自己的数据集即可!
对于步骤 2,通常使用贪心法(greedy algorithm)来选择要使用的特征和具体的拆分,以便对成本函数进行最小化。如果我们仔细想一想,在构建决策树时执行拆分相当于划分特征空间。我们将反复尝试不同的拆分点,然后在最后选择成本最低的拆分点。当然,我们可以采取一些聪明的做法,比如,只在数据集的值范围内进行拆分。这样我们就可以避免将算力浪费在测试那些很槽糕的拆分点上。
对于回归树,我们可以用一个简单的平方误差作为成本函数:
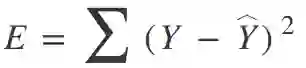
其中,Y 是真相,Y-hat 是预测值;我们对数据集中的所有样本求和来获得总误差。对于分类,我们使用基尼指数函数:

其中,pk 是特定决策节点中 k 类训练实例的比例。理想情况下,节点的错误值应为零,这意味着,每次拆分都会 100% 输出一个类。这正是我们想要的,因为这样我们就可以知道,一旦我们到达那个特定的决策节点,我们的输出到底是什么,而无论我们在决策边界的哪一边。
在我们的数据集中,每次拆分一个类的概念成为信息增益。看看下面的例子。
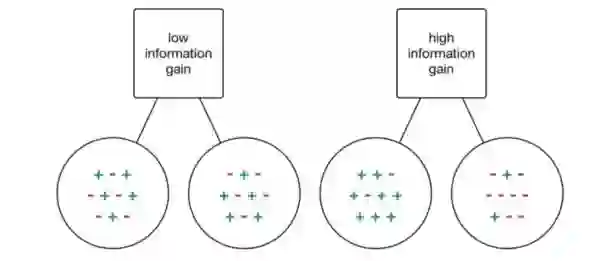
如果我们要选择一个拆分,其中每个输出都有一个依赖于数据的类组合,那么,我们实际上根本没有获得任何信息;我们不知道是否存在这样的一个特定节点(即特征),对我们的数据分类有任何影响!另一方面,如果我们的拆分对于每个输出的每个类都有很高的百分比,那么我们就会得到这样的信息,即在特定的特征变量上以特定的方式对信息进行拆分,会得到一个特定的输出!
现在,我们当然可以继续拆分、拆分、拆分…… 直到我们的树有了成千上万的分支,但这并不是一个好主意。我们的决策树将会变得巨大,缓慢,并对我们的训练数据集过拟合。因此,我们将设置一些预定义的停止标准来停止树的构造。
最常见的停止方法是对分配给每个叶节点的训练样本的数量进行最小计数。如果计数小于某个最小值,则不接受拆分,并将该节点视为最终叶节点。如果所有的叶节点都成为最终叶节点,训练就会停止。最小计数越小,拆分效果就越好,潜在的信息也越多,但是也更容易对训练数据出现过拟合。如果最小值太大,你可能会过早停止。因此,最小值通常是基于数据集设置的,这取决于每个类中预期有多少个样本。
由于训练决策树的性质,它们很容易出现过拟合。为每个节点的最小实例数设置正确的值可能很困难。大多数时候,我们可能会选择一个安全的方法,把最小值设置得非常小,这样就会产生很多拆分,最终生成一个非常庞大且复杂的树。关键是,这些拆分中有许多最终会变得多余,没有必要提高模型的准确性。
树修剪是一种利用这种拆分冗余来移除的技术,即修剪树中不必要的拆分。从高层次来讲,修剪会将树的一部分从严格的、僵化的决策边界压缩成更平滑、更通用的树,从而有效地降低树的复杂性。决策树的复杂性被定义为树中的拆分次数。
一种简单而高效的修剪方法是遍历树中的每个节点,评估删除节点对成本函数的影响。如果变化不大,那就修剪掉!
分类和回归的决策树在 Scikit Learn 中使用内置类非常容易使用!我们将首先加载数据集并初始化决策树以进行分类。运行训练就是一段简单的几行代码!

Scikit Learnin 还允许我们使用 graphviz 库对我们的树进行可视化。它提供了一些选项,这些选项有助于将决策节点进行可视化,并将模型学到的决策节点拆分开来,这对于理解决策节点的工作方式非常有用!下面我们将根据特征名称对节点进行着色,并显示每个节点的类和特征信息。
你还可以在 Scikit Learn 中为决策树模型设置几个参数。这里有一些有趣的方法可以尝试,以得到更好的结果:
max_depth: 我们将停止拆分节点的树的最大深度。这类似于控制深度神经网络中的最大层数。降低层数会使模型更快,但不那么准确;调高层数可以得到较高的准确性,但存在过拟合的风险,而且还可能会变得缓慢。
min_samples_split: 拆分节点所需的最小样本数量。我们讨论了上述决策树的这个方面,以及如何将其设置为更高的值来帮助缓解过拟合。
max_features: 寻找最佳拆分时要考虑的特征数量。更高的水平意味着可能会有更好的结果,但同时也意味着需要付出更长的训练时间。
min_impurity_split: 树生长中的早期停止的阈值。如果节点的杂质高于阈值,节点就会拆分。这可以用来权衡过拟合(高值、小树)和高准确度(低值、大树)。
presort: 是否对数据进行预排序,以加快你何种最佳拆分的发现。如果我们事先对每个特征的数据进行排序,我们的训练算法将更容易找到合适的值进行拆分。
下面是一些决策树的优点和缺点,可以帮助你确定你的问题是否适合应用决策树,以及有关如何有效应用它们的一些提示:
易于理解和解释。 在每个节点上,我们能够确切地看到模型正在做什么决策。在实践中,我们将能够完全理解准确度和误差来自何处,模型可以很好地处理哪种类型的数据,以及输出如何受到特征值的影响。Scikit Learn 的可视化工具是可视化和理解决策树的最佳选择。
只需很少的数据准备。 许多机器学习模型可能需要大量的数据预处理,例如归一化,并且可能需要复杂的正则化方案。另一方面,在调整一些参数后,决策树在开箱即用时可以工作得非常好。
使用树进行推理的成本是用于训练树的数据点数量的对数。 这是一个巨大的优势,因为它意味着拥有更多的数据,不一定会对我们的推理速度产生巨大影响。
过拟合在决策树中很常见,这仅仅是因为训练的性质。通常建议执行某种类型的降维,比如主成分分析(Principal component analysis,PCA,参阅《Principal Component Analysis: Your Tutorial and Code》 https://towardsdatascience.com/principal-component-analysis-your-tutorial-and-code-9719d3d3f376),这样树不必学习这么多的特征上的拆分。
由于与过拟合类似的原因,决策树也容易偏向数据集中战队书的类。做一些类的平衡总是一个好主意,比如类的权重、抽样或专门的损失函数等。(类平衡参阅《Handling Imbalanced Datasets in Deep Learning》https://towardsdatascience.com/handling-imbalanced-datasets-in-deep-learning-f48407a0e758)
原文链接:
https://www.kdnuggets.com/2018/12/guide-decision-trees-machine-learning-data-science.html

喜欢这篇文章吗?记得点一下「好看」再走👇





