裤子换裙子,就问你GAN的这波操作秀不秀
选自 arXiv
作者:Sangwoo Mo , Minsu Cho , Jinwoo Shin
机器之心编译
把照片里的绵羊换成长颈鹿、牛仔长裤换成短裙。听起来有点不可思议,但韩国科学技术院和浦项科技大学的研究人员目前已实现了这一骚操作。他们开发的一种机器学习算法可在多个图像数据集上实现这种操作。其论文《InstaGAN: Instance-Aware Image-to-Image Translation》已被 ICLR2019 接收。

长裤变短裙
图像到图像的转换系统——即学会把输入图像映射到输出图像的系统——并非什么新鲜事。去年 12 月,Google AI 研究人员开发了一种模型,该模型通过预测对象的大小、遮挡、姿势、形状等,可以逼真地将其插入照片中的合理位置。但正如 InstaGAN 的创建者在论文中所说的一样,即使当前最先进的方法仍是不够完美的。
本文要介绍的这项新研究基于 CycleGAN 实现了实例级别的图像转换。
图源:Context-Aware Synthesis and Placement of Object Instances
CycleGAN 克服了 pix2pix 在图像转换中必须一一配对的限制,给定两个无序图像集 X 和 Y,CycleGAN 可以自动对它们进行互相「翻译」。

但它无法编码图像中的实例信息,因此在涉及目标类别特征的图像转换时,效果不太理想。
「由于其近期基于生成对抗网络取得的进步令人印象深刻,无监督的图像到图像转换已受到大量关注。然而,以前的方法在面对具有挑战性的任务时常常失败,尤其是当图像具有多个目标实例并且任务涉及形状的大幅变化时。」研究人员表示。
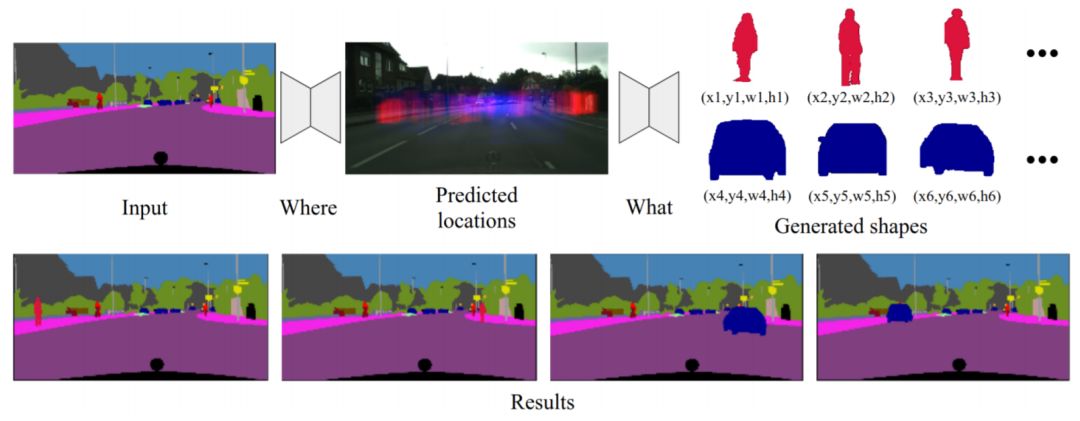
他们的解决方案是 InstaGAN 系统,该系统结合了多个任务目标的实例信息。InstaGAN 会生成图像的实例分割掩码(属于同一实例的像素组),它会结合目标的边界并同时忽略颜色等细节。
新奇的是,InstaGAN 转换了一幅图像和一组相应的实例属性,并同时力求保留背景语境。当与一种创新的技术(该技术允许其在传统硬件上处理大量实例属性)结合时,它可以推广到具有许多实例的图像。如下图所示,把两个人的牛仔裤换成裙子,把四只绵羊换成长颈鹿都不是问题。


「据我们所知,在我们之前,还没有人实现过图像到图像转换中的多实例转换任务。和以前在简单设置中的结果不同,我们的重点是和谐,让实例与背景自然地渲染。」
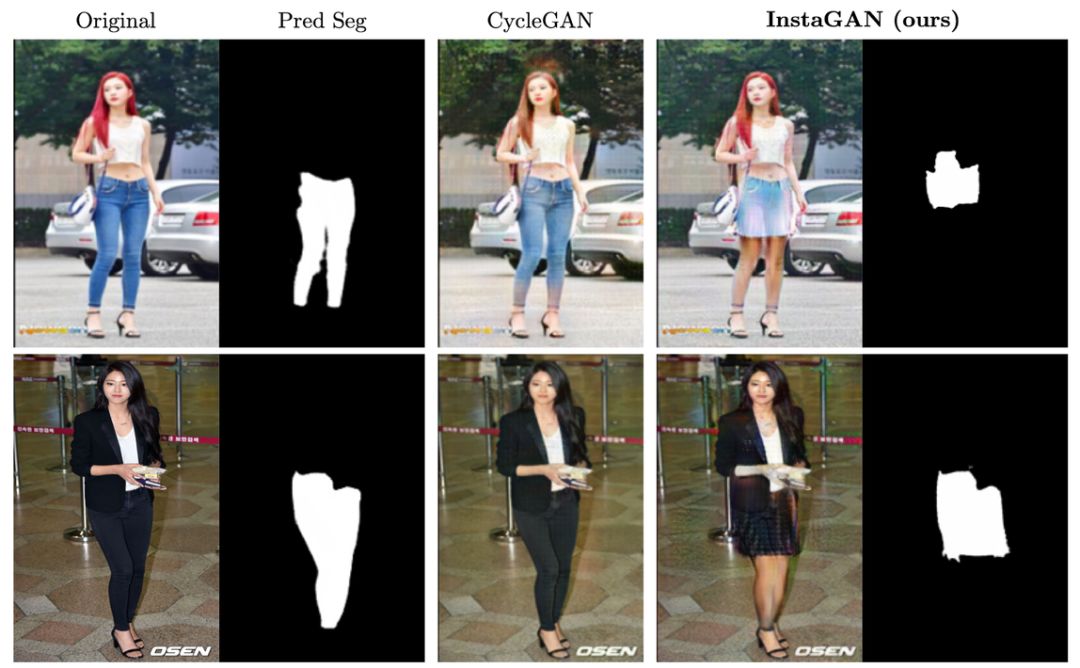
研究人员为 InstaGAN 系统提供了来自不同数据集(包括 multi-human parsing(MHP)数据集、MS COCO 数据集和 clothing co-parsing(CCP)数据集)的两类图像。与图像到图像转换的公认基线 CycleGAN 相比,InstaGAN 能够更成功地在保留原始语境的同时生成目标实例的「合理形状」。
「在不同数据集上的实验成功实现了图像至图像转换中的挑战性任务——多实例转换,包括把时尚图像中的牛仔裤换成短裙等新任务。探索新任务和新信息将是未来有趣的研究方向。」研究人员写道。
这篇论文已被 ICLR2019 接收为 Poster 论文,获得了 7、8、7 的高分,其中一位评审在评审意见中写道:
本文作者对多图像实例进行非成对的跨域转换,他们提出了一种方法——InstaGAN。该方法基于 CycleGAN,考虑了以每个实例分割掩码形式存在的实例信息。
本文文笔较好,容易理解。该方法很新颖,解决了一类之前方法无法解决的信息问题。该模型及训练目标每个部分的动机在该问题的语境中都得到了清晰的解释。结果看起来相当不错,明显优于 CycleGAN 和其它基线。
论文:INSTAGAN: INSTANCE-AWARE IMAGE-TO-IMAGE TRANSLATION

论文链接:https://arxiv.org/pdf/1812.10889.pdf
项目地址:https://github.com/sangwoomo/instagan
ICLR 链接:https://openreview.net/forum?id=ryxwJhC9YX
摘要:由于生成对抗网络的快速发展,无监督图像到图像的转换吸引了大量研究者的目光。然而,之前的方法通常不适用于较难的任务,尤其是在图像拥有多个目标实例或转换任务涉及极具挑战性的形状问题时,如将时尚图片中的裤子转换成短裙。为了解决这一问题,本文提出了一种新的方法——instance-aware GAN(InstaGAN),这种 GAN 结合了实例信息(如目标分割掩码),提高了多实例转换的能力。在保持实例置换不变性的同时,该 GAN 对图像和相应的实例属性集进行转换。为此,研究人员引入了一个语境保留损失函数,鼓励网络学习目标实例之外的恒等函数。此外,他们还提出了一种序列 mini-batch 推理/训练技术,这种技术借助有限的 GPU 内存处理多个实例,增强了该网络在多实例任务中的泛化能力。对比评估证明了该方法在不同图像数据集上的有效性,尤其是在上述具有挑战性的情况下。

图 1:先前方法(CycleGAN, Zhu et al. (2017))的转换结果 vs InstaGAN。后者在多实例转换问题中得到的结果更好。
在谷歌搜索图片上的结果(裤子→短裙)

在 YouTube 视频上的结果(裤子→短裙)
研究者还在 GitHub 给出了两个预训练模型,感兴趣的读者可以下载试试。点击以下链接下载预训练模型(裤子→短裙及/或绵羊→长颈鹿):
地址:https://drive.google.com/drive/folders/10TfnuqZ4tIVAQP23cgHxJQKuVeJusu85
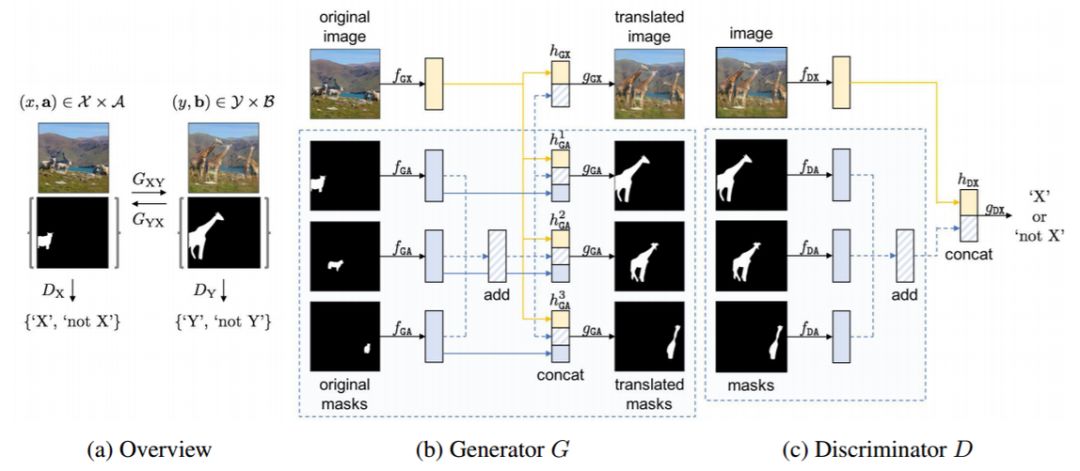
图 2:(a)InstaGAN 架构概览,其中的生成器 G_XY、G_YX 和判别器 D_X、D_Y 分别遵循(b)和(c)中的架构。每个网络都同时编码一幅图像及相应的一套实例掩码。
InstaGAN 成功地把牛仔裤和短裙互换,把短裤和长裤互换。

图 4:在 clothing co-parsing(CCP)(Yang et al., 2014)数据集上的转换结果。
绵羊和长颈鹿互换,杯子和瓶子互换都不是问题。

图 6:在 COCO(Lin et al., 2014)数据集上的转换结果。
我们可以只给第一位小姐姐换短裙,也可以只给第二位小姐姐换,当然一起换也 OK。

图 7:输入掩码不同,InstaGAN 得到的结果也不同。
具体的玩法自然不限于此,作者可没说需要限制性别。

图 13:在 MHP 数据集上的更多转换结果(裤子→短裙)。
从展示的案例中也可以发现,CycleGAN 的转换效果总是受到源图像的形状偏差影响,所以其转换偏向于目标的纹理层面。比如,在下图中,CycleGAN 就把短脖子的绵羊变成了短颈鹿。

图 15:在 COCO 数据集上的更多转换结果(绵羊→长颈鹿)。
给予赞赏的同时,同一位评审也指出了该论文的一些不足,并给出了相应的建议:
就测试领域的数量(三类图像对——长颈鹿/绵羊,长裤/短裙,杯子/瓶子)来看,结果有一定的局限性。从某种意义上来说,这也是可以理解的。谁也不会没事用它来转换从未在相同语境出现过或者大小不同的目标(如杯子和长颈鹿)。但如果示例对更多会更好,也会使该系统更具说服力。
此外,如果单个模型可以在多个类别对上训练并从它们之间共享的信息中受益,那将很有趣。
评估主要是定性的。我希望看更多该模型的控制变量实验。

图 9:关于本文所述方法每个组成部分效果的控制变量研究。这些部分包括:InstaGAN 架构、语境保留损失函数、序列 mini-batch 推理/训练算法,分别表示为 InstaGAN、L_ctx 及 Sequential。

图 10:关于序列 mini-batch 推理/训练技术效果的控制变量研究。「One」和「Seq」分别表示「one-step」推理和序列推理。
参考链接:https://venturebeat.com/2019/01/01/this-neural-network-can-swap-sheep-for-giraffe-jeans-for-skirts/
机器之心CES 2019专题报道即将到来,欢迎大家积极关注。