纵观对话预训练技术演变史:化繁为简的背后,什么在消亡?

文 | 橙橙子
最近,百度发布了对话生成预训练模型PLATO-XL,110亿的参数规模,也让它成为了对话领域目前最大的预训练模型。不到两年的时间,PLATO系列已走过三代。作为国内对话预训练技术的头部玩家,它的每一次升级,也拨动着对话技术爱好者的好奇心。
今天,我们将秉承客观公正的态度,对三代技术进行系统的对比,试图从它的演化历程中深入挖掘出开放域对话效果提升的秘密。文末最后,将会抛出灵魂拷问:化繁为简是否意味着“算法”走向了尽头,对话预训练技术之路将走向何方?
论文标题:
PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable
PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
论文链接:
https://arxiv.org/pdf/1910.07931.pdf
https://arxiv.org/pdf/2006.16779.pdf
https://arxiv.org/pdf/2109.09519.pdf
PLATO-1代:基于离散隐变量的对话预训练
PLATO-1代主要为了解决开放域对话系统中存在的两个问题,一是多轮对话数据匮乏问题,二是一个对话的上文(Context)可以对应多个合理回复(Response)的“一对多(One-to-many)”问题,从而增加回复的多样性和吸引力。
为了解决第一个问题,PLATO在通用预训练模型BERT的基础上进行了较大规模对话领域数据(Twitter & Reddit ~8.3M)的二次预训练,并且在下游特定种类的对话数据上进行了微调。其中,领域二次预训练起到了关键作用。
为了解决第二个问题,PLATO在预训练中引入了隐变量识别任务。给定训练数据上下文和目标回复(Context,Response),首先让模型以识别隐变量种类的方式学习到隐含的意图是什么,意图的候选是一个有限的大小为K的隐变量集合。即根据上下文和回复估计出离散隐变量分布的后验概率,并从中采样 。接着,才会依据估计得到的隐变量和上下文进行拼接,进行序列化的回复生成任务 。
在模型结构上,PLATO借鉴了UniLM[1]:对上文进行了双向编码,充分利用和理解上文信息;对回复进行单向解码,适应回复生成的自回归特性。
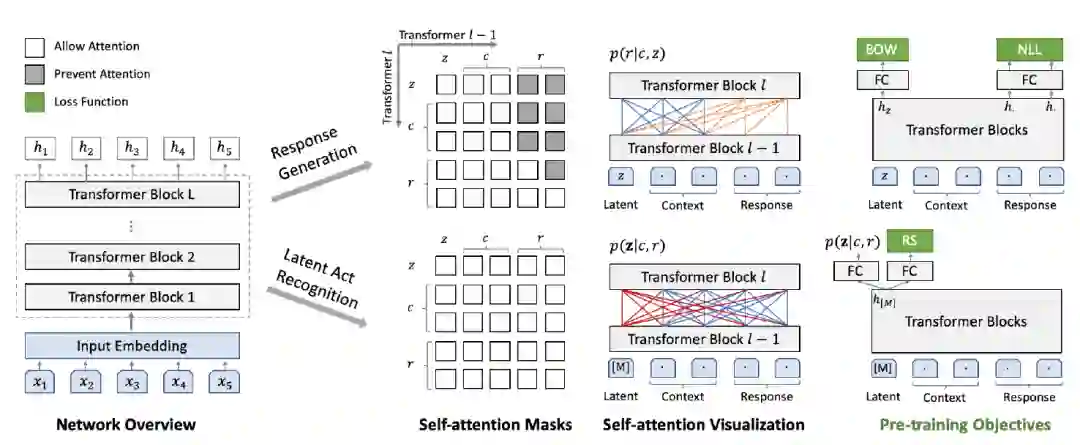
PLATO训练使用了三个目标函数 。负对数似然(negative log-likelihood, NLL loss)是典型的文本生成目标。为了帮助隐变量的学习,增加了词袋损失(bag-of-words, BOW loss),即忽略回复词的顺序,让离散隐变量能捕捉到目标回复的全局信息。回复选择损失(response selection, RS loss)则是通过采样负例进行分类的方式判断回复和上下文的相关性。
整体上,PLATO的二次领域数据预训练手法和离散隐变量解决回复多样性的问题在当时是比较先进的,在闲聊、对话式问答等多个数据集上达到了当时的领先水平,并且很好的展示了解决对话多样性的能力。
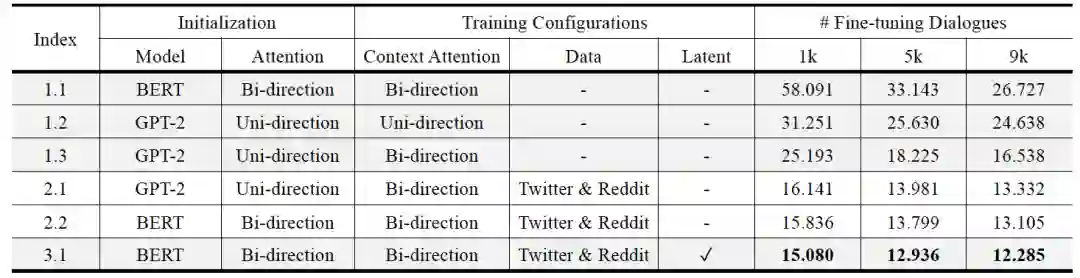
值得指出的是,第一代的PLATO瞄准的是解决对话预训练中的某种特定问题。8.3M的对话数据,12层的Transformer,1.3亿参数,单机8卡,表明它并没有在参数规模和大规模训练手法上花太多功夫。
PLATO-2代:基于课程学习的对话预训练
PLATO-2代是PLATO-1代的技术延伸,即如何让PLATO-1代的技术在更大规模数据和更大规模参数下的高效训练。PLATO-2代的初心仍然想坚持PLATO-1代的思路,认为相对于Meena[2], Blender[3]等“One-to-one”的模型,基于隐变量的“One-to-many”设计具有更好的深度畅聊能力。
遗憾的是,从头开始直接放大PLATO-1代使得训练很困难。原文中并没有直接做量化的实验告诉我们有多困难或者效果损失有多严重,仅有文字表明会遇到训练不稳定和效率的问题。因此,二代采用了课程学习的思路,第一阶段,走“One-to-one”的粗粒度路线,走的是上下文双向编码,回复单向生成的经典结构。试图捕捉到典型的规律、通用的概念,结果上更倾向于得到安全的回复。第二阶段,正式引入了离散隐变量网络,走“One-to-many”的细粒度路线,目标多样回复生成。第三阶段,训练评估模型,用来学习回复的一致性从而选择最合适的回复,评估部分独立出来是为了免除多种任务的干扰。
在二代所处的历史时刻,Facebook的Blender[3]已经出生,通用预料预训练(BookWiki like Corpus)+ 社交对话数据二次预训练(Twitter+Reddit)+ 人工标注数据(BST)再次调优的思路已经成为了最佳数据利用路线,也被PLATO-2代所采用。
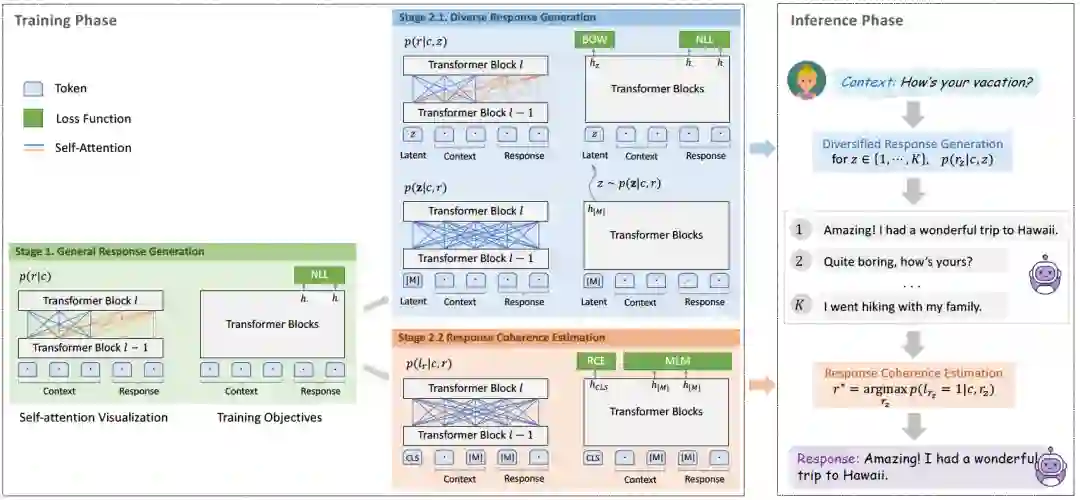
总体上,PLATO-2代的方法个人感觉是无奈之举,一代充满诚意的精心设计在更大数据和更大算力面前反而显得没有优势了,只能用最简单的一对一模型打头阵,“训练困难”四个字写满心酸、充满不甘。
其实从三阶段课程学习中每个阶段的参数细节上我们也可以看出,第二阶段离散隐变量的引入导致batch size骤减,学习率精调,可能是对显存占用、超参等有严格的要求。

另外有两个细节,关于深度学习框架和深度数据清洗,没有这两个环节,可能无法支撑起模型的效果。以框架为例,PLATO-2代是有着32层Transformer,16亿参数,耗费64卡,3周时间,在7亿样本训练(英文部分)的中等规模模型。已经对深度学习框架的非常规特性有一定的依赖,除了采用了混合精度等常规操作外,特别加入了gradient checkpointing/Recompute[4,5] 的能力,这是一项用时间换空间的技术,在网络前向时只保存部分中间节点,在反向时重新计算没保存的部分,能够极大的减小显存占用,提大batch size。
PLATO-3代:百亿参数极简对话预训练
其实看到3代叫PLATO-XL这个名字,当时就有一种预感,离散隐变量和课程学习都要被抛弃了。理由也是有理由的,2代已经告诉我们为了不同而不同有多么耗费心神。在巨大算力的绝对硬实力面前,貌似任何设计都显得过分雕琢而显得性价比太低了。从模型结构图就可以看出来PLATO-3代有多么朴实无华。
这是一种纯简Transform结构,对话上下文双向编码,回复单向生成,只保留了负对数似然作为文本生成的预训练目标。Token编码+位置编码+类型编码+多轮对话角色编码组成输入也是经典搭配。
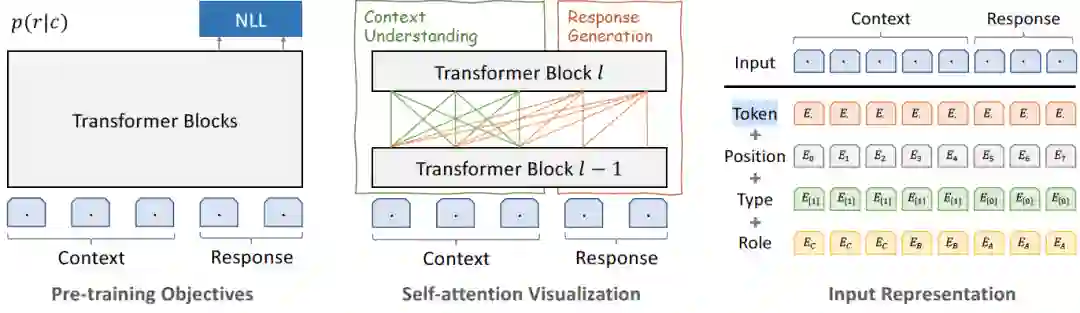
就是这样一个被PLATO1代和2代作为baseline被踩的对象,如今华丽蜕变,这样的故事我们可能在其他领域也有所耳闻。表明经典结构在参数规模没有跃进之前,不好妄自批判,否则会打脸很严重。
但是朴实无华真的意味着技术简单么,显然不是!只是发生了单点技术贡献的转换。PLATO-3代的参数量在对话领域规模惊人,达到了110亿。这是一个有着72层Transformer,32个注意力头,词向量维度和前向隐层维度都相对大,在256块 V100-32G GPU上训练的单体大模型。PLATO-2代表明,如果单卡要把所有参数装进去,最多可以装入16亿参数。所以除了gradient checkpointing/Recompute[4,5],最新的3代也充分加入了PaddlePaddle新的功能特性:分片数据并行(sharded data parallelism)[6],通过在多个设备上划分优化器状态、梯度和参数来保持低通信量和高计算效率。PLATO3代的batch size达到了惊人的200万token,可以说是提分杀手锏了。从某种角度来说,特定领域模型大而强效果的背后,背书的是一个公司综合能力和一个团队的综合整合资源能力。
效果上看,PLATO-3代在开放域对话连贯性、信息丰富度、吸引人的程度上有不俗的表现,同时在知识性对话和任务型对话上达到了新的高度。


发散一下:如果说单体模型参数量可以做的更大,对加速训练的基础设施、软硬件堆栈设计、分布式训练技术优化算法的要求会更苛刻。拥有5300亿的威震天-图灵(Megatron-Turing)[7] 大家是不是很耳熟?拿它在PLATO的对话数据上二次预训练效果会怎么样呢?:)
路在何方
为了对PLATO三代版本的演变细节进行更直观的对比,这里整理了表格(以英文模型为例)。
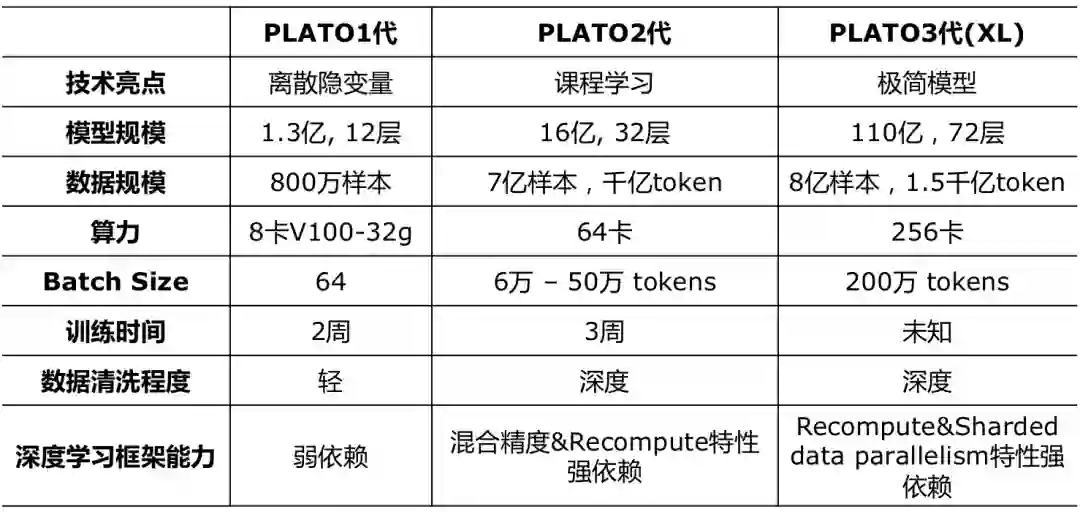
亲自体验过PLATO的效果,十分惊艳,这里要给一个大大的赞。但是又有些不安。不管我们承不承认,以预训练技术为代表的大模型已经开启了大规模工程化模式。这就意味着,目前最有效的途径里,单点模型算法的差异占比越来越小,一系列单点技术整合的壁垒占比越来越高。
但是另外一方面,工程化和资金投入(简称烧钱)又有极其相关的联系,容易导致巨头们你方唱罢我登场PK参数级别的内卷局面。如果简单优雅的方法能够把问题解决的非常好,应该值得更多的赞誉和推崇。但是能够拼手速和资源攻占的问题,不一定是关键问题。并且这似乎离我们想象的,依靠人类的灵感天赋创造力,十年磨一剑,扫地僧似的算法科学家,在白板上思维纵横,数学符号串联出突破人工智能本质问题的途径差别巨大。
工程化技术的红利会见底么?毕竟开放域对话要解决的技术问题如此复杂,要达到人类的知识水平、情感能力、多模交互水准极其困难。
雪崩的时候 没有一片雪花是无辜的。
萌屋作者:橙橙子
拿过Kaggle金,水过ACM银,发过顶会Paper,捧得过多个竞赛冠军。梦想是和欣欣子存钱开店,沉迷于美食追剧和炼丹,游走于前端后端与算法,竟还有一颗想做PM的心!
作品推荐
 萌屋作者:橙橙子
萌屋作者:橙橙子
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Unified Language Model Pre-training for Natural Language Understanding and Generation https://arxiv.org/pdf/1905.03197.pdf
[2] Towards a Human-like Open-Domain Chatbot https://arxiv.org/pdf/2001.09977.pdf
[3] Recipes for building an open-domain chatbot https://arxiv.org/pdf/2004.13637.pdf
[4] Training Deep Nets with Sublinear Memory Cost https://arxiv.org/pdf/1604.06174.pdf
[5] BERT重计算:用22.5%的训练时间节省5倍的显存开销 https://mp.weixin.qq.com/s/CmIVwGFqrSD0wcSN_hgH1A
[6] Zero: Memory optimizations toward training trillion parameter models https://arxiv.org/pdf/1910.02054.pdf
[7] Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
 后台回复关键词【
后台回复关键词【