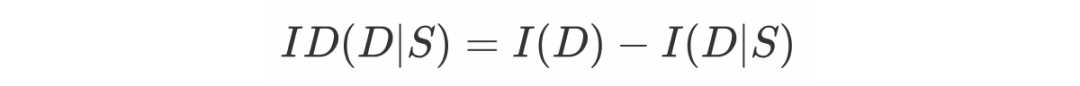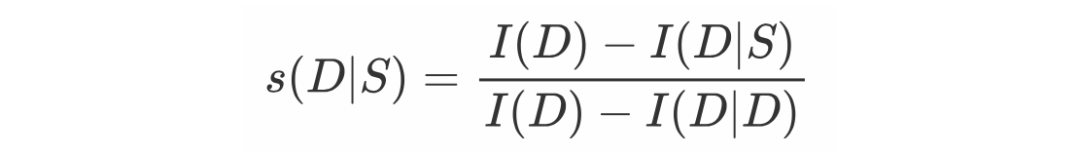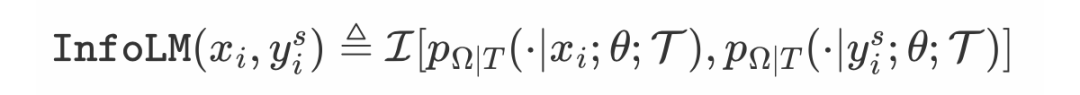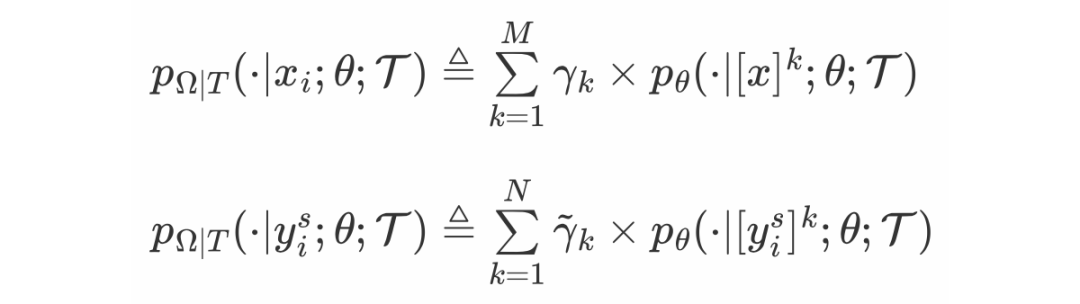©PaperWeekly 原创 · 作者 | 王馨月
单位 | 四川大学
研究方向 | 自然语言处理
新任务
论文标题:
NAREOR: The Narrative Reordering Problem
https://arxiv.org/abs/2104.06669
文本的结构(顺序)隐含了许多信息,重新排列叙事会影响读者从中得出的时间、因果、事件等推论,进而对其解释和趣味性产生影响。本文作者提出了一个新的任务——叙事重新排序(Narrative Reordering, NAREOR),即以不同的叙事顺序重写给定的故事,同时保留其情节。作者通过人类以非线性顺序重写 ROCStories 中的故事,并对其进行详细分析,提供了一个数据集 NAREORC。此外,作者提出了具有合适评估指标的训练方法。
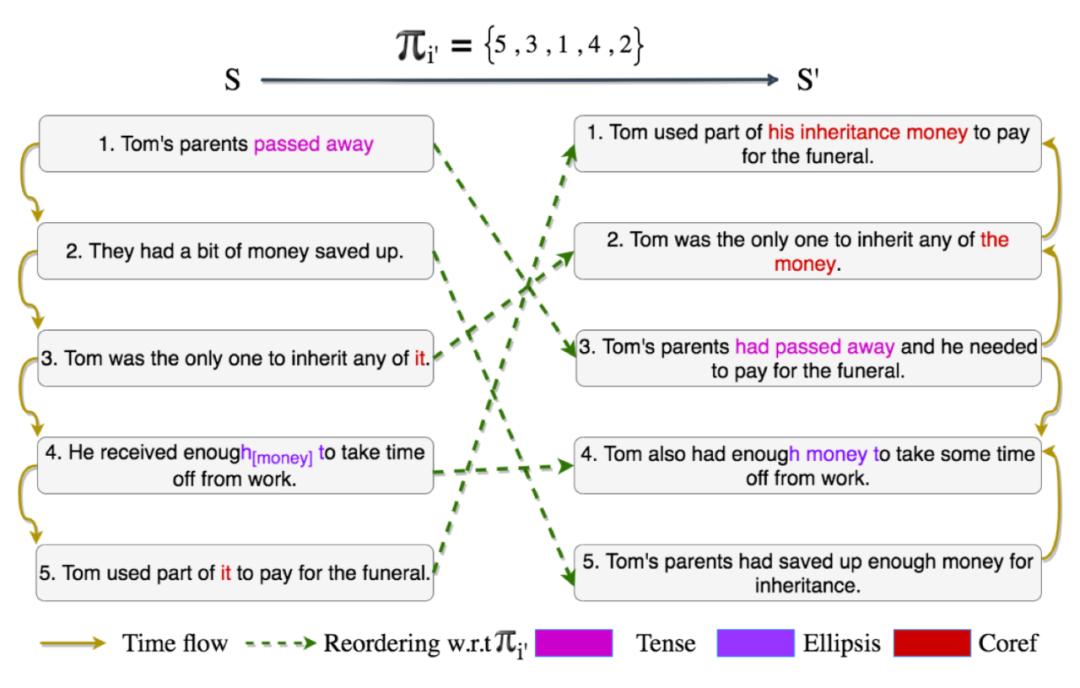
上图是本文任务和数据集的示例。左侧是原始输入故事
,上方是叙事顺序
,右侧是人类重写的故事
。挑战在于,简单地重新排序句子是远远不够的,因为必须调整重写的文本以处理共指、时态和其他语篇依赖才能形成正确且有效的故事,一次遗漏或不正确的编辑可能导致完全不同或无效的故事。
训练过程涉及两种特殊的训练方法:
叙事去噪(NAR-denoise, NAR-d):NAR-d 试图模仿人类的重写方式,学习从朴素的排序(简单地交换位置)转换为高质量的文本。它涉及模型训练的两个阶段。第一阶段是故事级去噪的无监督训练,第二个阶段是在上一阶段基础上的监督训练。
叙事重排(NAR-reorder, NAR-r):NAR-r 模型处理给定目标顺序的重新排序,而不是事先进行朴素的重新排序。将输入
,
编码为用于训练的标记序列,在逆方向
方向进行训练,再进一步进行微调,在
方向进行训练。
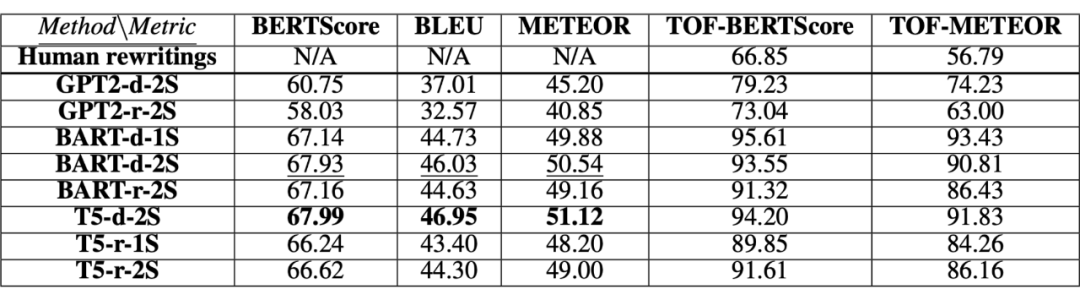
作者选择 GPT-2、BART 和 T5 模型进行实验,结果如上图。
这篇文章提出的任务对于一些对文本顺序敏感的任务都有一些帮助,比如论文写作的论证以及临床叙述生成患者病史等。
2.1 Play the Shannon Game With Language Models
Play the Shannon Game With Language Models: A Human-Free Approach to Summary Evaluation
论文链接:
https://arxiv.org/abs/2103.10918
项目地址:
https://github.com/primerai/blanc/tree/master/shannon
这篇文章作者引入了一种新的无参考摘要评估指标——香农分数(Shannon Score),思路来自 Hovy 和 Lin(1998)提出的香农游戏(Shannon Game):分配给 3 个人一个字母一个字母地猜测文档的任务,其中第一个人可以看文档,第二个人可以看文档摘要,第三个人什么也看不到。通过测量第二个人与其他人相比猜测文档的尝试次数,可以评估摘要中传达了多少有关文档的信息,从而衡量摘要的质量。作者还提出了一个称之为信息差异的变体(Information Difference)。
假设我们有一个条件语言模型
,表示对应于给定摘要
的文档概率分布。使用这个条件语言模型,如果我们已经获得了摘要
的信息,我们可以计算条件信息内容
作为从文档
中获得的信息量。
如 果
是
的令人满意的摘要,则
<
,进一步将信息差异定义如下式,表示使用摘要和不使用摘要之间文档信息的变化,它相当于文档和给定摘要的文档之间的对数似然比:
考虑到最能保存文档信息的摘要是文档本身,可以将
视为
的下界。进一步可以计算香农分数指标为:
香农分数为我们提供了摘要的有用程度与文档本身的有用程度之间的比率。
上图是本文方法的一个图例,作者挑选了一个文档摘录,并将其与编写的两个抽象摘要配对。虽然这两个摘要在语法上都是正确的,并且主要由文档中的单词组成,但其中一个摘要质量高,另一个质量低。图中较暗的背景颜色表示较高的信息量。
可以看出,低质量的摘要可能有助于模型预测诸如“CNN”之类的词,但对于摘要中混淆使用的诸如“哺乳动物”和“网站”之类的词则无济于事。除了每个句子的第一个或两个标记外,阅读已经阅读过的文档获得的信息很少。这是作者自回归语言建模设置的产物,因此测量
对规范香农分数很有用。
作者在文中还进一步验证了本文提出的指标的有效性,指标还可能对于例如释义或以查询为中心的摘要任务有一定作用。
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
论文链接:
https://arxiv.org/abs/2112.01589
这篇文章作者引入了 InfoLM —— 一种新的评估文本摘要和 data2text 生成的指标。InfoLM 与现有的基于 BERT 的指标(如 BERTSCORE、MOVERSCORE)不同,它直接依赖于输出离散概率分布的预训练掩码语言模型(pre-trained masked language model, PMLM)。由于 InfoLM 依赖于 token 的统计数据,因此也可以将其视为基于字符串的度量标准。并且,因为 PMLM 还允许为释义分配高权重并捕获长程依赖关系,InfoLM 不会产生基于字符串的度量的常见缺陷。
InfoLM 包含以下几个组件:(1)一个 PMLM,用于计算词汇表在给定候选句子和参考句子的情况下观察词汇的每个 token 的概率的离散分布。(2)对比函数 ,用于测量上述概率分布之间的差异(即文本相似程度)。
上式为 InfoLM的 计算公式,其中
和
是两个离散分布,分别表示在给定候选句子
和参考句子
的情况下观察词汇的每个 token 的概率,
和
分别衡量候选文本和参考文本中第 k 个 token 的重要性。计算公式如下:
作者对文本摘要任务和 data2text 任务进行实验,在原文和附录中有非常详细的数据记录,得出结果证明了本文方法的有效性。作者还得出结论:在可用的对比度量中,Fisher-Rao 距离是无参数的,因此在实践中很容易使用,而 AB-Divergence 有更好的结果,但需要选择 α 和 β。
The King is Naked: on the Notion of Robustness for Natural Language Processing
论文链接:
https://arxiv.org/abs/2112.07605
项目地址:
https://github.com/EmanueleLM/the-king-is-naked
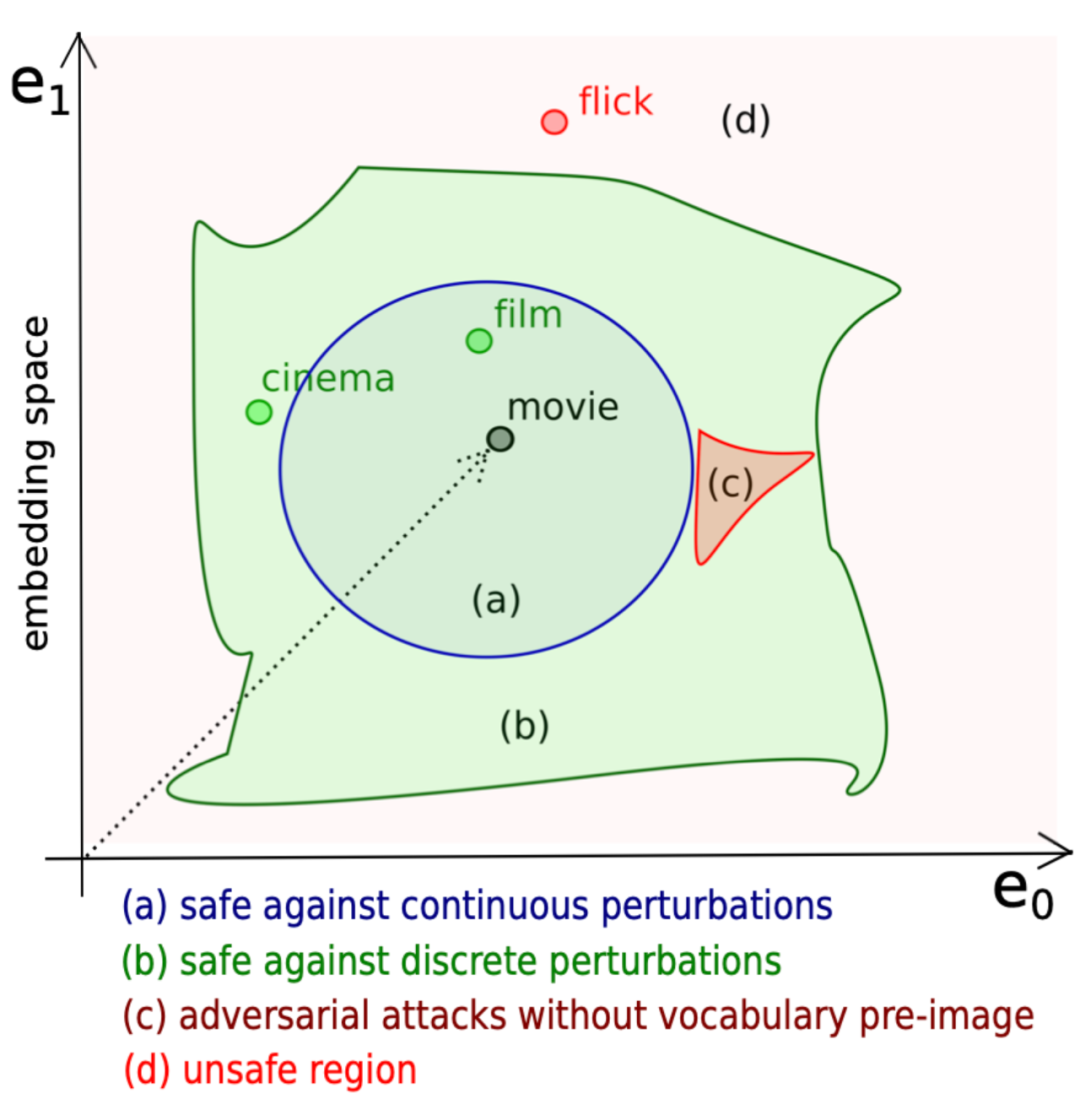
这篇文章的作者认为,最初为图像引入的鲁棒性标准并不适用于 NLP。因此,作者提出了(局部)语义鲁棒性——根据预测在模型中引起的偏差来表征,通过测量语言规则的鲁棒性而不是单词替换或删除。作者使用基于模板的生成测试研究了一系列原版和经过稳健训练的架构的语义鲁棒性。作者得出结论:语义鲁棒性可以提高模型对于复杂语言现象的性能,尽管相对于对抗性鲁棒性更难计算。
连续鲁棒性:广泛用于图像,是基于嵌入向量进行操作的。但由于自然语言是离散的,在连续鲁棒性的定义中,
有界鲁棒性意味着这个
有界区域中的任何向量都是安全的。这种假设与语言本身特性是不一致的,因为网络可能会呈现一个决策边界,其中不是正确单词的对抗性攻击会限制验证或严重减少安全区域。如下图所示:
这两种鲁棒性公式都只允许对符号替换或删除进行鲁棒性测试。而将一个词局部替换为其他词很难对释义测试鲁棒性。从语言学的角度来看,这个问题的出现是因为自然语言中单词的频率遵循 Zipf 定律 ,其中罕见的术语和结构——因此是边缘情况——比其他自然现象更频繁地出现。且我们不能保证离散和连续设置中的扰动不会违反所考虑的任务。由于实现离散和连续鲁棒性的方法允许在选择替代品时进行弱监督,因此扰动可能会偏离正在考虑的任务。
作者因此提出语义鲁棒性:对于语义分析任务
,输入
,
为接受的方案,
为拒绝的方案。则在语言规 则
,和评估标准
,当
成立且
时,我们说
对于
和
是
语义鲁棒的(
-semantically robust)。
作者进一步定义了语义鲁棒性的有界不变条件并证明局部语义鲁棒性可以推广到全局语义鲁棒性。
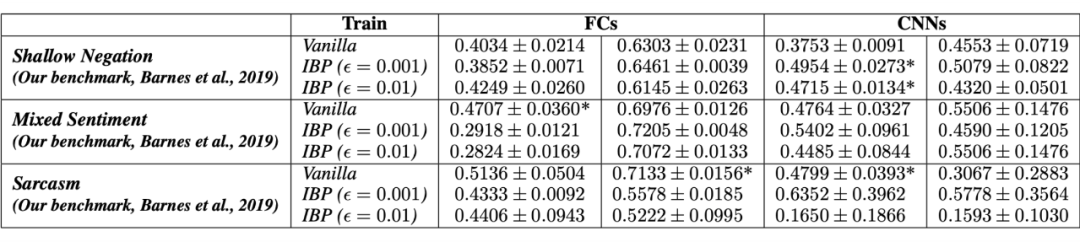
作者进行了针对以下问题进行了实验:(i)经典意义上的鲁棒模型是否在语义上也是鲁棒的;(ii)对特定语言现象的鲁棒性是否是训练准确的 NLP 分类器的副产品;(iii)对于不同的架构,增强监督训练(使用包含特定语言现象的文本)是否会在包含相同现象的未见测试样本上诱导泛化;(iv)是否有可能训练出既准确又具有语义鲁棒性的模型,以及(v)无监督学习在多大程度上有助于语义鲁棒性。
作者在斯坦福情感树库数据集(SST-2)和 Barnes 收集的数据集上使用充分训练并微调过的模型进行实验。结果如下图:
本文提出的语义鲁棒性虽然很难实现,但对传统鲁棒性难以解决的复杂问题具有更好的效果,这对于解决其他 NLP 任务可能有帮助。
GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
论文链接:
https://arxiv.org/abs/2111.14592
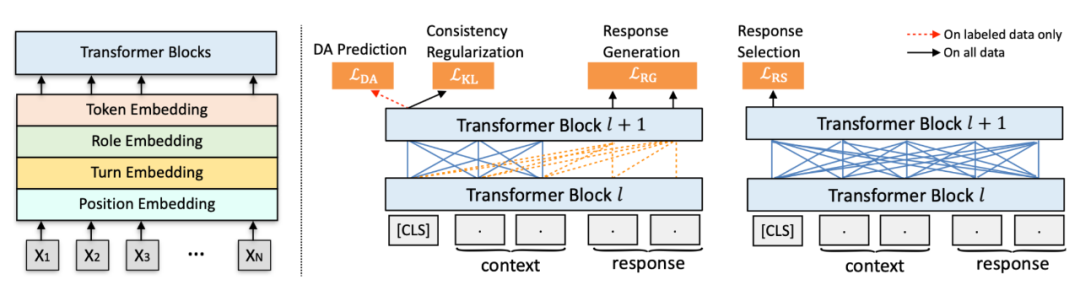
这篇文章作者提出了一种名为 GALAXY 的用于面向任务对话系统的生成式半监督预训练模型,旨在以低成本将对话策略的知识明确地注入到预训练中,同时保持其强大的对话理解和生成能力。作者为面向任务的对话(Task-oriented dialog, TOD)构建了一个统一的对话行为(Dialog act, DA)分类法,并开发了一个名为 UniDA 的新标记数据集。作者还收集和处理了一个名为 UnDial 的大规模未标记对话语料库,其中包含 3500 万个语料,场景包含从在线论坛到客户服务。
上图为本文的预训练对话模型架构,左侧是输入表示,右侧是预训练组件。预训练组件包含四个部分:响应选择(Response Selection);响应生成(Response Generation);对话行为预测(DA Prediction);一致性正则化(Consistency Regularization)。
作者还提出了一种半监督预训练范式,对所有数据应用一致性正则化,能够最小化对丢失扰动样本进行的模型预测之间的双向 KL 散度,这有助于更好地从未标记的对话语料库中学习表示。作者还在未标记数据的 KL(Kullback-Leibler)损失上添加了一个可学习的控制门,这样只有好的样本才被允许进行一致的正则化。
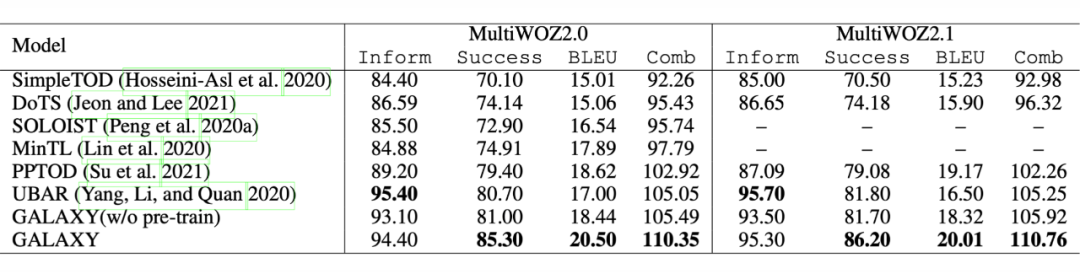
如上图所示,实验表明,GALAXY 显着改进了 TOD 系统,并在 In-Car、MultiWOZ2.0 和 MultiWOZ2.1 上取得了SOTA,将端到端综合得分推高至 107.45、110.35 和分别为 110.76。作者还观察到,GALAXY 在各种低资源设置下都具有很强的 few-shot 能力。
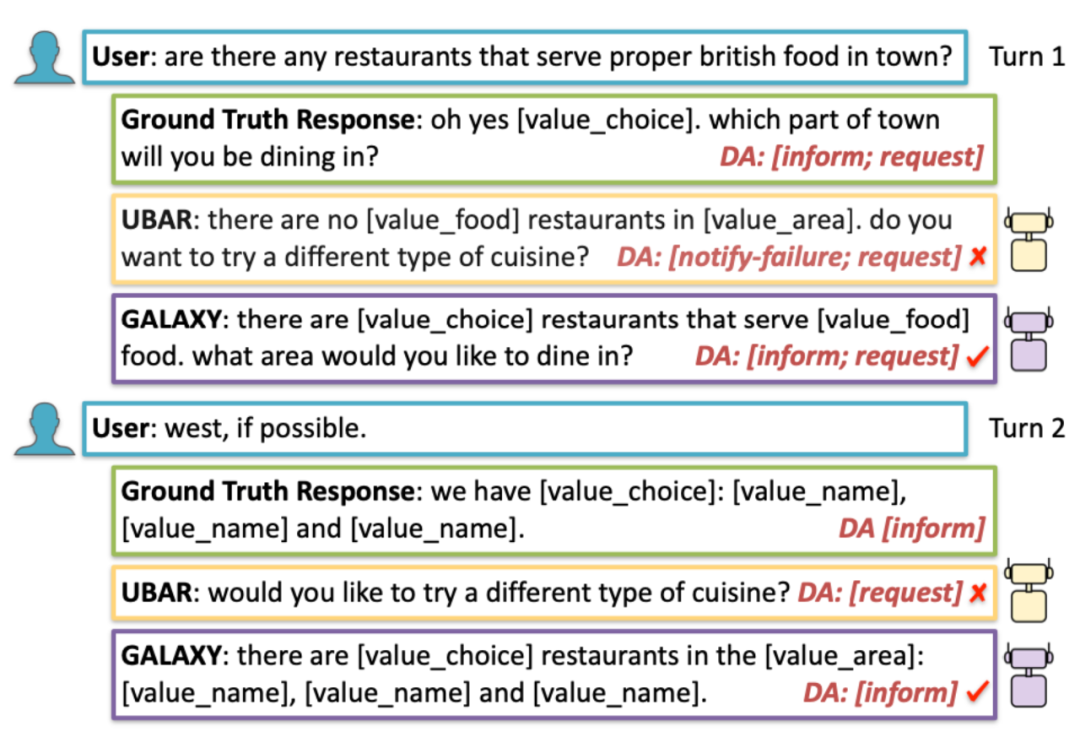
上图是一个响应生成的示例,GALAXY 在前两个回合中选择了正确的对话行为,以便整个对话可以引导成功完成任务。相反,UBAR 在开始回合接受了错误的 DA notify-failure,在第二回合接受了冗余的 DA 请求,从而导致交互失败。
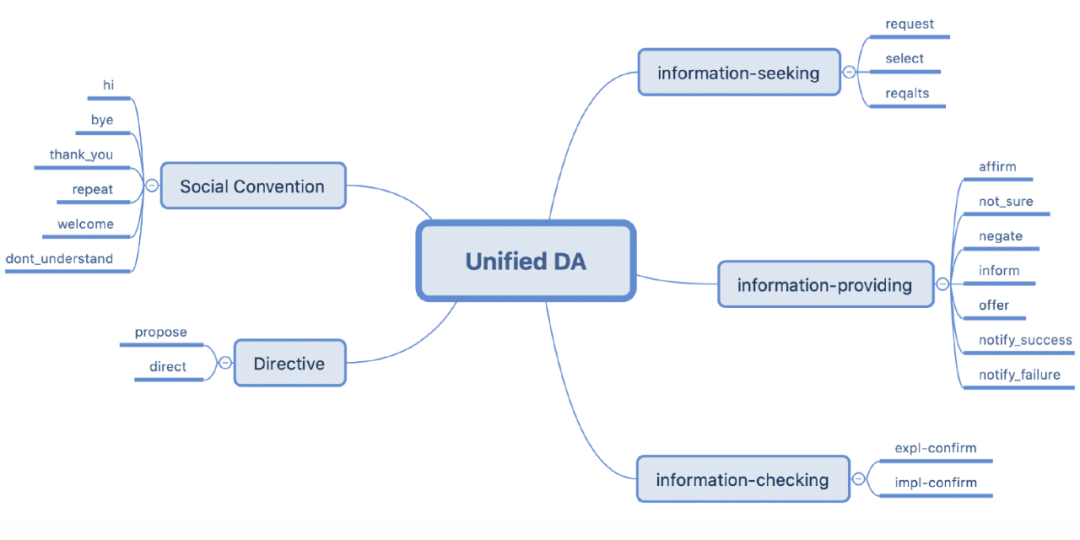
作者在附录中还给出了一种 DA 的分类方法,如下图所示,可能对进一步的工作有帮助。
3.2 Hybrid Curriculum Learning
Hybrid Curriculum Learning for Emotion Recognition in Conversation
论文链接:
https://arxiv.org/abs/2112.11718
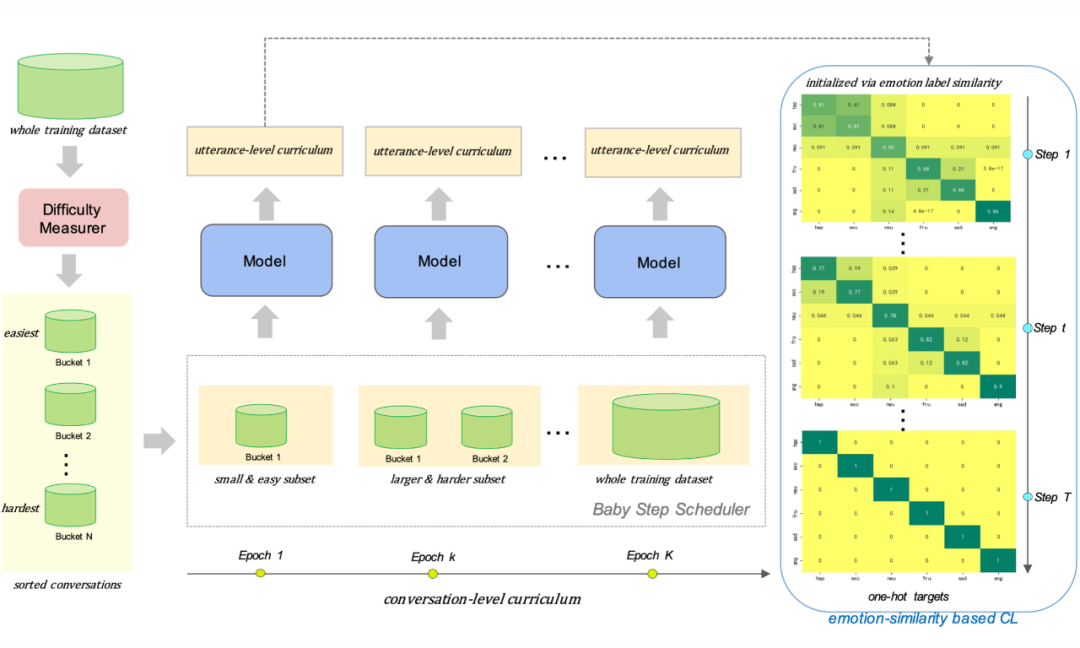
对话情绪识别(Emotion recognition in conversation, ERC)旨在检测每个话语的情绪标签。近期研究证明,以有意义的顺序提供训练示例而不是随机排序可以提高模型的性能。这篇文章的作者提出了一个面向 ERC 的混合课程学习框架。框架由两个课程组成:(1)会话级课程(conversation-level curriculum, CC);(2)话语级课程(utterance-level curriculum, UC)。
在 CC 中,作者基于对话中的“情绪转换”频率构建了一个难度测量器,然后根据难度测量器返回的难度分数将对话安排在“从易到难”的模式中。UC 是从情感相似性的角度实施的,它逐渐增强了模型识别混乱情绪的能力。通过提出的与模型无关的混合课程学习策略,作者实验发现各种现有 ERC 模型的性能显著提升,并且能够在四个公共 ERC 数据集上实现 SOTA。
在课程学习(curriculum learning, CL)中,典型的课程设计包含两个核心组件:难度测量器(difficulty measurer)和训练调度器(training scheduler)。难度测量器用于量化每个数据示例的相对“容易程度”。训练调度器根据难度测量器的判断,在整个训练过程中安排数据子集的顺序。
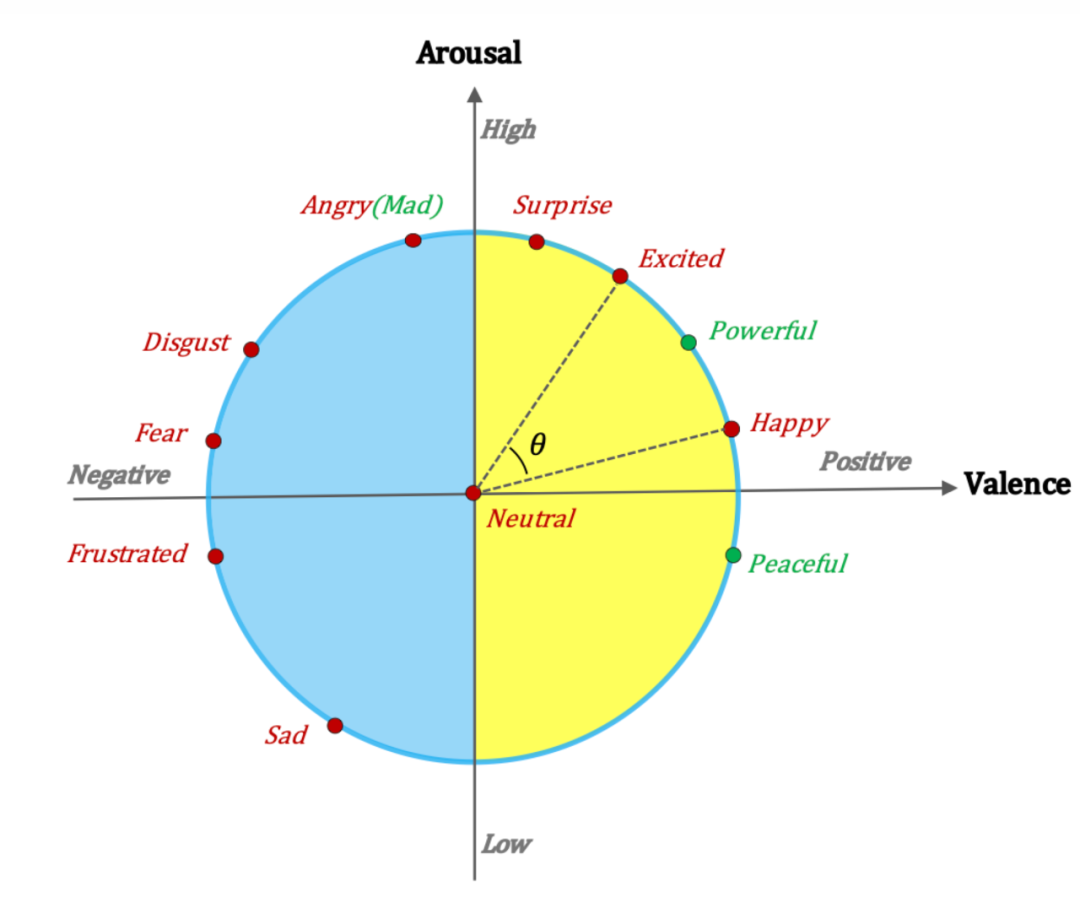
上图是本文提出的混合课程学习(hybrid curriculum learning, HCL)框架示意图。对于 CC,作者设计了一个基于情绪转换的难度测量器。一种广泛使用的 CL 策略称为 baby step,被用作训练调度程序。对于 UC,在训练过程中,同一会话中的话语必须同时输入到一个批次中。因此,采用传统的训练调度器(如 baby step)来安排话语的训练顺序是不可行的。作者提出了基于情感相似性的课程学习来解决这个问题。下图是作者基于之前工作提出的情绪唤醒-效价(arousal-valence)坐标,其中包含标准 ERC 数据集中的所有情绪。每个情绪标签都可以映射到单位圆上的一个点,可以借此计算情感标签之间的相似度。
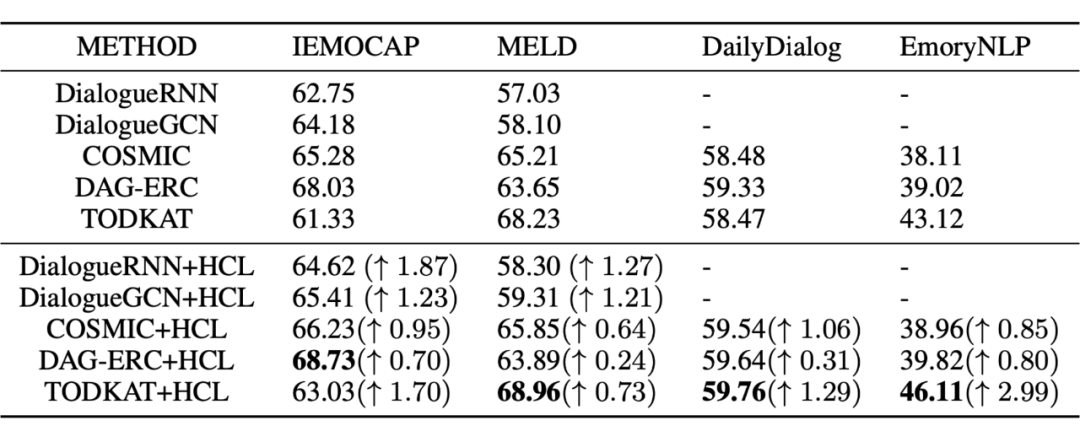
下图是一些 baseline 模型使用 HCL 的对比结果,可以看出 HCL 能使现有模型性能显著提高。
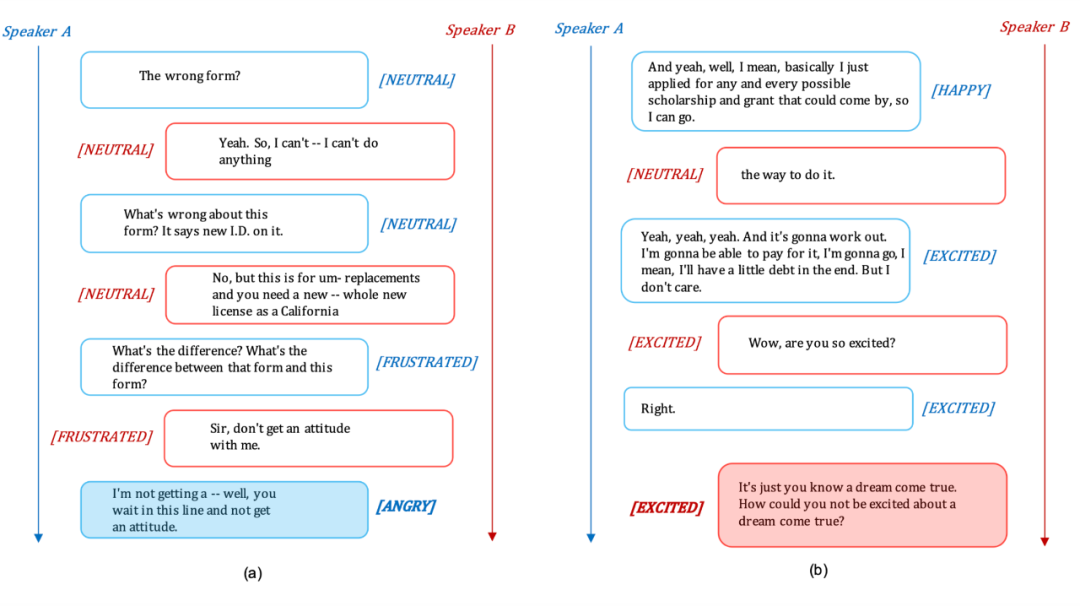
下图是使用 HCL 的示例。目标是预测蓝色框中最后一句话的情感标签。由于情绪转换的发生,实验中的所有 baseline 方法都容易错误地将情绪识别为沮丧。而大多数“X+HCL”方法都能够正确识别该话语的情绪,这表明 HCL 在一定程度上缓解了这个问题。右边描述了一个带有混淆标签的案例。红框中最后一句话的情感标签是激动。DialogueGCN 和 DAG-ERC 等一些 baseline 模型将情绪误认为是快乐的。在使用 HCL 框架后,DialogueGCN+HCL 和 DAG-ERC+HCL 成功地将情绪识别为正确的标签兴奋。
Contrast and Generation Make BART a Good Dialogue Emotion Recognizer
论文链接:
https://arxiv.org/abs/2112.11202
项目地址:
https://github.com/whatissimondoing/CoG-BART
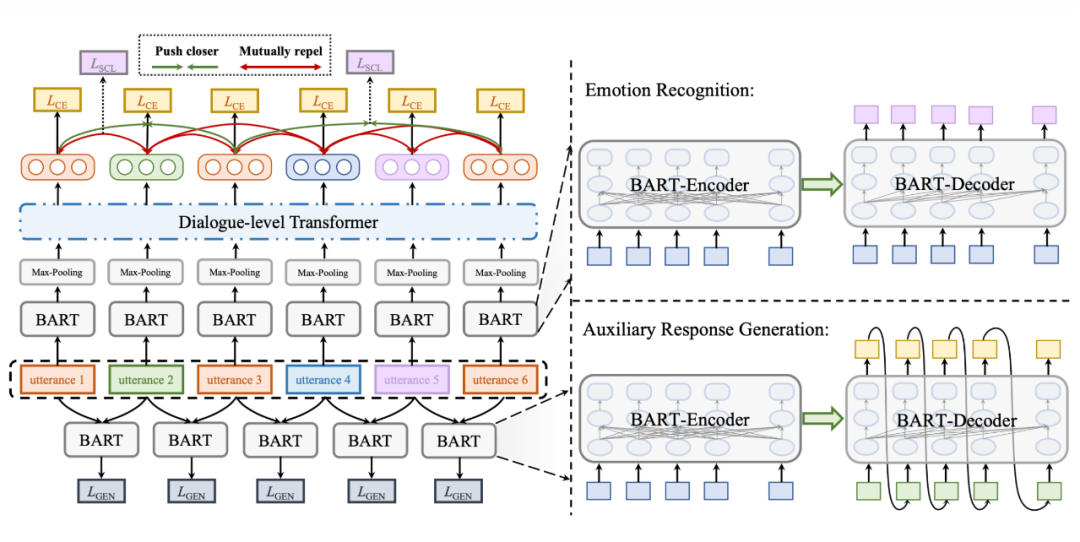
这篇文章是邱锡鹏老师等人关于对话情绪识别(Emotion recognition in conversation, ERC)的一篇文章。作者引入了对话级 Transformer 层来模拟话语之间的长期上下文依赖关系。采用监督对比学习(supervised contrastive learning, SCL)来缓解对相似情绪进行分类的困难。还引入了一个辅助响应生成任务,以增强 ERC 捕获上下文信息的能力。
最后,作者利用 BART,作为主干模型,并通过对比和生成损失来增强它。与 baseline 模型相比,本文提出的对比生成增强 BART(COnstrastive-and-Generation-enhanced BART, CoG-BART) 在四个 ERC 数据集上获得了 SOTA。此外,消融实验和案例研究证明了 ERC 任务中对比和生成损失的有效性。
上图是本文提出的 CoG-BART 框架的示意图。
在 ERC 的监督对比学习过程中,首先将说话者拼接在话语前,再灌入 BART 的共享 Embedding 层,实现话语 encoding。再将输出结果进行 Max-pooling,得到话语的聚合表示。为了对对话的历史上下文信息进行建模,我们利用对话级 Transformer 层作为上下文编码器。Multi-head 注意力机制可以捕捉多轮对话中不同对话之间的交互,并聚合不同的特征以获得最终的隐式表示,从而充分建模不同话语和上下文之间的复杂依赖关系关系,就此得到了话语的上下文依赖表示。
监督对比学习通过充分利用标签信息,将批次中具有相同标签的所有示例都视为正例,对预训练模型进行微调时使得小样本学习更加稳定。对于 ERC,某些数据集中每个类别的样本数量是高度不平衡的,而有监督的对比学习在计算损失时会掩盖自己。如果批次中某个类别只有一个样本,则不能直接用于计算损失。因此,对话语的隐藏状态进行复制,并对其梯度进行分离,使得参数优化保持稳定。
为了便于模型在确定话语情感时考虑更丰富的上下文信息,模型需要在给定当前话语的情况下生成其后续话语。后续话语中每个 token 的输出隐藏状态由 BART 解码器顺序生成。
模型训练的损失由三部分组成:上下文建模后得到的隐藏状态通过多层感知器获得计算交叉熵损失的 logits、监督对比损失和响应生成损失。损失是三个分量的加权和,它们的权重之和等于 1。
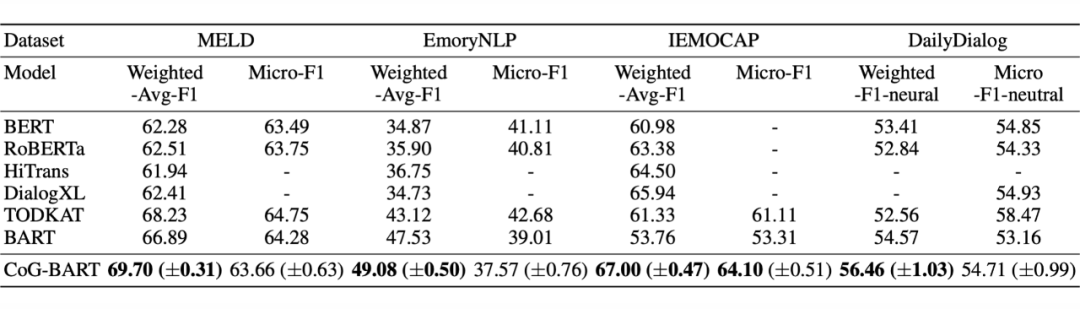
实验结果如上图所示,可以看出 CoG-BART 取得了很好的结果。作者还对 SCL 进行了定性和定量分析以及消融实验,表明有监督的对比学习可以有效地提高模型识别情绪的效率,从而提高整体性能。此外,作为辅助任务的响应生成有助于模型充分考虑上下文,以识别不同上下文中语义相似话语的情绪。
Knowledge Bridging for Empathetic Dialogue Generation
论文链接:
https://arxiv.org/abs/2009.09708
项目地址:
http://github.com/qtli/KEMP
缺乏外部知识使得移情(empathetic)对话系统难以感知内隐情绪并从有限的对话历史中学习情感交互。为了解决上述问题,作者提出了一种知识感知的移情对话生成方法(Knowledge-aware EMPathetic dialogue generation method, KEMP)。它由三个组件组成:情绪上下文图、情绪上下文编码器和情绪依赖解码器。情感上下文图是通过将对话历史与外部知识相结合来构建的。
情感上下文编码器使用图形感知转换器来学习图形嵌入,并提出一个情感信号感知程序来感知导致响应生成的上下文情感。以知识丰富的上下文图为条件,作者提出了一种情绪交叉注意机制来从情绪上下文图中学习情绪依赖关系。作者在基准数据集上进行的大量实验验证了所提出方法的有效性。此外,作者发现本文的方法的性能可以通过与正交工作的预训练模型集成来进一步提高。
上图显示了移情对话的真实示例。如果我们使用说话者输入的非停用词作为查询,通过外部知识获取知识,我们可以获得各种与情绪相关的概念及其情绪强度值,这有助于理解情绪。作者定量研究了外部知识在理解情感方面对移情对话语料库的影响,发现响应与对话历史几乎没有非停用词重叠。这种现象意味着人类需要推断出更多的外部知识来进行移情对话。
相比之下,如果我们将外部知识(即与情感相关的概念)纳入系统,我们观察到,对于大多数对话样本,聊天机器人可以直接从由对话历史中的非停用词的知识路径中获得线索。因此,外部知识对于获取有用的情感知识和提高移情对话生成的性能至关重要。
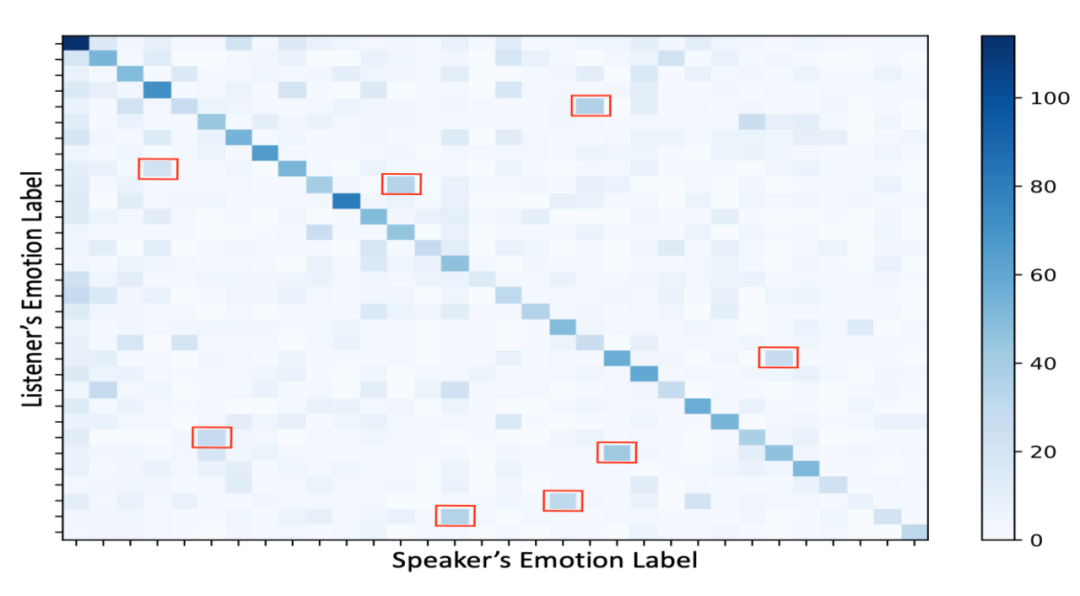
在调查过程中,作者观察到另一种现象,即情感依赖和情感惯性在移情对话中通常与外部知识一起出现。作者使用基于 CNN 的情绪分类器标记话语,并可视化从说话者到听众的情绪转换。如上图所示,较暗的对角线网格表明听众倾向于反映他们的对话者以建立融洽的关系。此外,除了对角线方向(红框内)外,还有一些复杂的情感过渡模式。因此,对对话者之间的情感依赖进行建模至关重要。
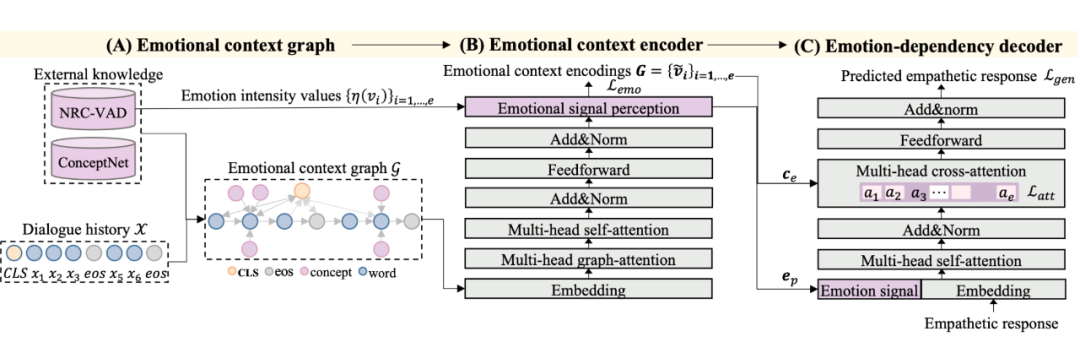
上图是本文提出的 KEMP 框架的示意图。KEMP 包含三部分:
情绪上下文图:将对话历史转化为长的词序列并插入 [CLS],对每一个停用词
从 ConceptNet 中选择备选集合
。接着采用三个步骤来提炼与情感相关的知识:(1)通过过滤具有相关关系的元组来提取
的子集
,以获得移情响应和足够的置信度分数。(2) 根据检索到的概念的情绪强度值对元组进行排序。对于
,选择前
元组作为情感知识子图。(3)应用 3 种类型的有向边来连接顶点:(i)两个连续单词之间的临时边;(ii)词
与其情感概念
之间的情感边;(iii)[CLS] 和其他顶点之间的全局边。最长得到情感上下文图
。
情绪上下文编码器:首先使用词嵌入层和位置嵌入层将每个顶点
转换为向量
和
。再将顶点状态(对话历史或外部知识)嵌入
。顶点
的向量表示是三种嵌入的组合。接着应用 Multi-head 关注邻居节点获得上下文表示。接着使用全局上下文信息更新顶点以模拟全局交互。模型从情绪上下文图中学习情绪信号
来指导移情反应的产生,使用 softmax 操作的线性层将向量投影到情绪标签上的情绪类别分布中,以识别移情反应的情绪信号
。与情感上下文编码
一起,情感向量
和
将作为关键情感信号输入解码器,以引导移情响应的生成。
情绪依赖解码器:decoder 是基于 transformer 层构建的。作者设计了两种策略以改善上下文和情绪响应间的情绪依赖关系:(1)结合情绪特征(2)增强情绪注意力损失。
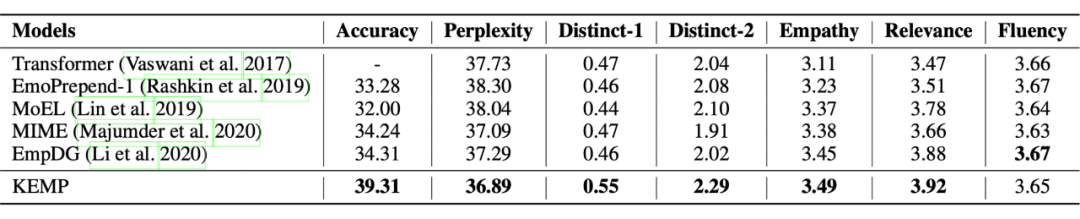
上图是作者在 EMPATHETICDIALOGUES 数据集上进行实验的结果。结果显示,如果没有情感建模,Transformer 只能基于语义映射生成流畅的响应,但无法表达多样化的响应。
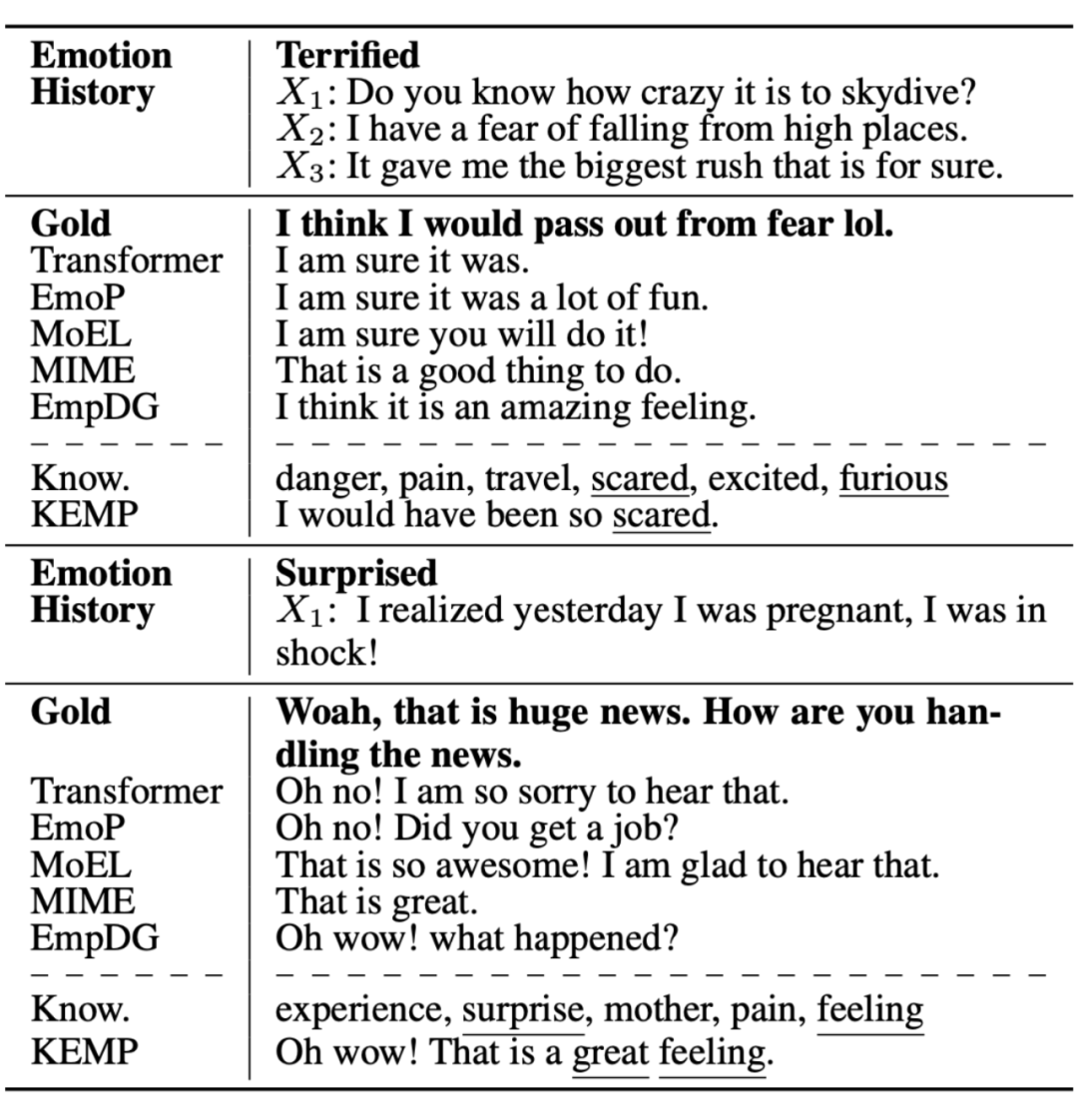
上图是 KEMP 和基线模型在说话者两种不同的情绪状态下生成的响应。下划线表示与知识相关的词。可以看出 KEMP 对于外部知识的利用对于响应生成有很大提升。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧