ECCV 2018 | DeepMind新研究连接听与看,实现「听声辨位」的多模态学习
选自DeepMind
作者:Relja Arandjelović、Andrew Zisserman
机器之心编译
参与:路、张倩
今日,DeepMind 发表博客介绍其新研究。该研究利用视频中有价值的信息源,即视觉、音频流之间的对应关系,进行视觉-音频的交叉模态检索和发声对象定位。该方法在两个音频分类基准上取得了新的当前最优性能。
视觉和听觉事件往往同时发生:音乐家拨动琴弦流出旋律;酒杯摔碎发出破裂声;摩托车加速时发出轰鸣声。这些视觉和听觉刺激同时发生,因为它们的起因相同。理解视觉事件与其相关声音之间的关系是探索我们周围世界的一条重要途径。
在《Look, Listen and Learn》和《Objects that Sound》(都是 ECCV 2018 论文)两篇论文中,DeepMind 通过几个问题进行探索:看、听大量无标注视频能学到什么?通过构建一个视听对应学习任务,从零开始联合训练视觉和音频网络,DeepMind 证明了:
视觉-音频网络可以学习有用的语义概念;
视觉、音频这两种模态可以互相探索(例如回答「哪个声音最适合这张图片?」);
可以定位发声对象;
之前的交叉模态学习方法的局限。
从多个模态中学习并不是新鲜事;之前的研究者主要致力于图像-文本或音频-视觉配对研究。然而,一种常见的方法是在一种模态中使用另一种模态中的「教师」网络提供的自动监督来训练「学生」模型(「教师学生监督」),其中「教师」使用大量人类注释进行训练。
例如,在 ImageNet 上训练的一个视觉网络可用于将 YouTube 视频的帧标注为「原声吉他」,为「学生」音频网络提供训练数据,以便其学习「原声吉他」的声音。作为对比,DeepMind 研究人员从零开始训练视觉和音频网络,在这一过程中,「原声吉他」的概念自然而然地出现在两种模态中。出人意料的是,与「教师学生监督」方法相比,这种方法在音频分类方面做得更好。如下所述,这一方法还可以定位发声对象,这是之前的方法无法做到的。
从交叉模态自监督中学习
该方法的核心理念是使用视频中有价值的信息源,即视觉、音频流之间的对应关系,因为它们同时出现在同一视频中。通过看、听人拉小提琴的大量例子以及狗吠的大量例子,几乎不在看人拉小提琴的同时听狗吠,或者反过来(听人拉小提琴,看狗吠),应该有可能推断出小提琴和狗的声音及外观。这种方法部分是受婴儿的启发,他们随着视觉和听觉能力的发展逐渐了解这个世界。
研究人员应用视听对应(AVC)进行学习,这是一项简单的二分类任务:给定一个示例视频帧和一个简短的音频片段,判断它们是否对应。
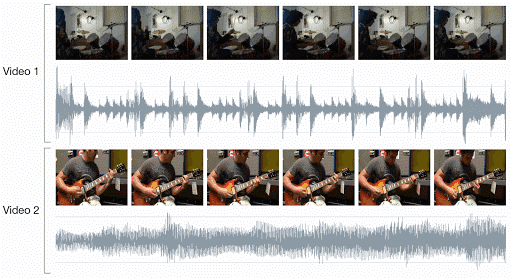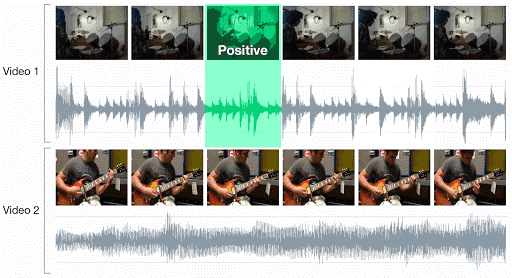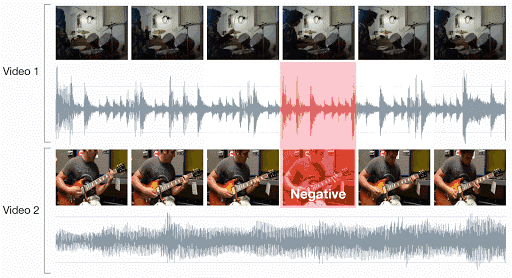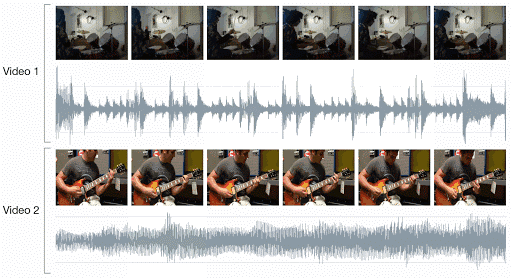
对于一个系统来说,完成这一任务的唯一方法就是学习如何在视觉、音频两个域中检测多种语义概念。为解决 AVC 任务,DeepMind 研究人员提出了以下网络架构。
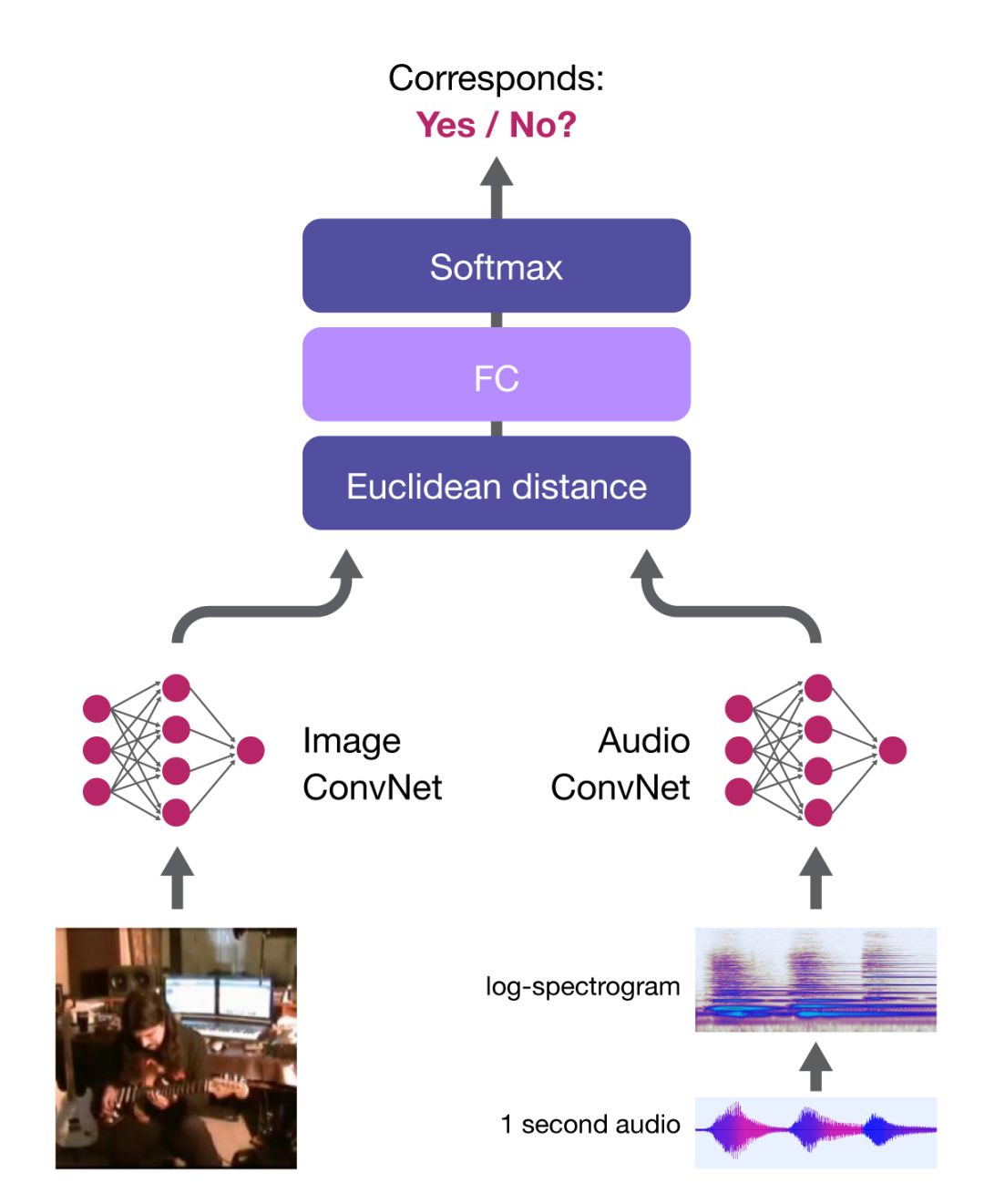
音频-视觉嵌入网络(AVE-Net)
图像和音频子网络提取视觉和音频嵌入,对应分(correspondence score)作为两个嵌入之间距离的函数来计算。如果嵌入相似,则该(图像,音频)被认为是对应的。
研究人员证明,这一网络可以学习有用的语义表征。例如,音频网络在两个音频分类基准上获得新的当前最优水平。由于对应分仅基于距离算出,两个嵌入被强制对齐(即向量在同一空间中,这样才能做有意义的对比),以便促进交叉模态检索:
定位发声对象
AVE-Net 可以识别语音和视觉域中的语义概念,但是它无法辨明「发声对象的位置」。DeepMind 研究人员再次使用 AVC 任务,展示了学习定位发声对象是可能的,且无需使用任何标签。
要想在图像中定位发声对象,研究人员需要计算音频嵌入和区域级图像描述子网格之间的对应得分。该网络使用多实例学习来训练——算出图像级对应分数,作为对应分数图的最大值:
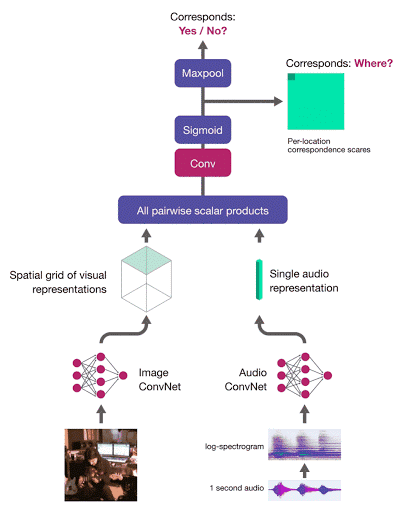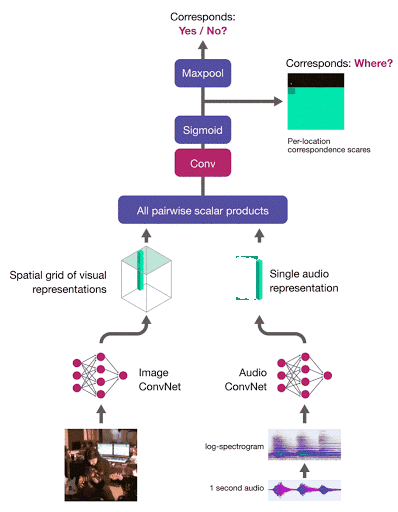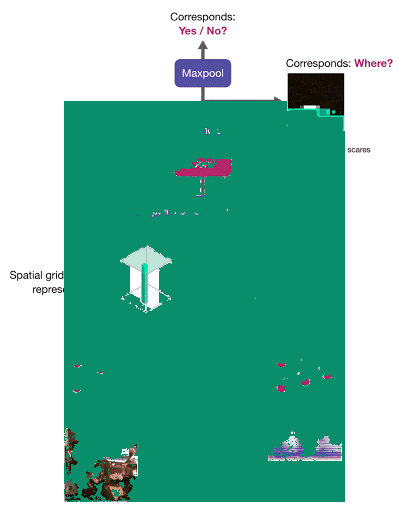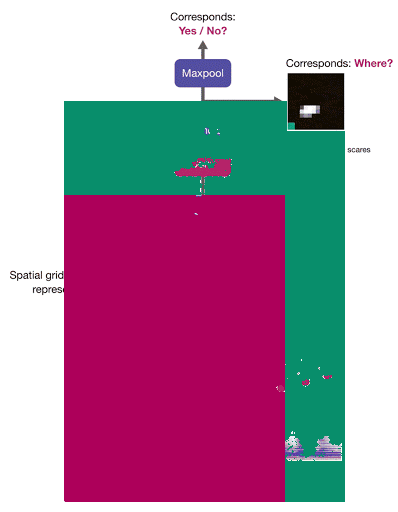
音频-视觉目标定位网络(AVOL-Net)
对于对应的图像-音频对,该方法能够鼓励至少一个高度对应发声对象的区域,从而实现目标定位。下面的视频中(左-输入帧,右-定位输出,中-overlay),所有帧都是完全独立地被处理:未使用运动信息,也没有时间平滑:
对于不匹配的图像-音频对,最大对应分值比较低,因此整个得分图颜色较暗,这表明图像中没有制造输入声音的对象:
在恰当的网络设计下,无监督音频-视觉对应任务可学习两个全新的功能:交叉模态检索和基于语义的发声对象定位。此外,它还帮助学习强大的特征,在两个音频分类基准上获得了新的当前最优性能。
这些技术在强化学习中也可能有用,帮助智能体利用大量无标注感官信息。未来该研究可能还会对音频-视觉任务以外的其他多模态问题产生影响。
相关论文:
1. Look, Listen and Learn

论文链接:https://arxiv.org/pdf/1705.08168.pdf
摘要:我们考虑了这样一个问题:通过「看」和「听」大量无标注视频可以学到什么?视频中包含宝贵的信息源——视觉和音频流之间的对应,但目前它们并未得到利用。我们介绍了一种可以利用该信息的新型「音频-视觉对应」学习任务。不使用任何监督,基于原始视频从零开始训练视觉-音频网络已被证明可以完成该任务,而且更有趣的是,这带来了良好的视觉和音频表征。这些特征在两个语音分类基准上获得了新的当前最优性能,其表现与 ImageNet 分类任务中的当前最优自监督方法不相上下。我们还证明了该网络能够在视觉、音频两种模态中定位发声对象,同时执行细粒度识别任务。
2. Objects that Sound

论文链接:https://arxiv.org/pdf/1712.06651.pdf
摘要:本文的目标是:1. 一个能将音频和视觉输入嵌入到公共空间且适合交叉模态检索的网络;2. 基于给出的音频信号,在图像中定位发声对象的网络。我们仅使用音频-视觉对应(audio-visual correspondence,AVC)作为目标函数对无标注视频进行训练,并达到了这两个目标。这是一种对视频的交叉模态自监督。
最终我们设计出了一个新的网络架构。通过 AVC 任务,该网络可用于交叉模态检索和定位图像中的发声对象。我们的贡献如下:(i) 证明了该网络可以学到能实现单一模态内部(如音频-音频)和模态之间检索的音频和视觉嵌入;(ii) 探索 AVC 任务的不同架构,包括适应包含单个图像、多个图像,或单个图像和多帧光流的视频流的架构;(iii) 展示了图像中的发声语义对象可以被定位(仅使用声音,而不利用运动或流信息);(iv) 在数据准备阶段,如何避免不合适的捷径。

原文链接:https://deepmind.com/blog/objects-that-sound/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



