用Numpy搭建神经网络第二期:梯度下降法的实现

大数据文摘出品
作者:蒋宝尚
小伙伴们大家好呀~~用Numpy搭建神经网络,我们已经来到第二期了。第一期文摘菌教大家如何用Numpy搭建一个简单的神经网络,完成了前馈部分。
这一期,为大家带来梯度下降相关的知识点,和上一期一样,依然用Numpy实现梯度下降。在代码开始之前,先来普及一下梯度下降的知识点吧。
梯度下降:迭代求解模型参数值
第一期文章中提到过,最简单的神经网络包含三个要素,输入层,隐藏层以及输出层。关于其工作机理其完全可以类比成一个元函数:Y=W*X+b。即输入数据X,得到输出Y。
如何评估一个函数的好坏,专业一点就是拟合度怎么样?最简单的方法是衡量真实值和输出值之间的差距,两者的差距约小代表函数的表达能力越强。
这个差距的衡量也叫损失函数。显然,损失函数取值越小,原函数表达能力越强。
那么参数取何值时函数有最小值?一般求导能够得到局部最小值(在极值点处取)。而梯度下降就是求函数有最小值的参数的一种方法。
梯度下降数学表达式
比如对于线性回归,假设函数表示为hθ(x1,x2…xn)=θ0+θ1x1+..+θnxn,其中wi(i=0,1,2...n)为模型参数,xi(i=0,1,2...n)为每个样本的n个特征值。这个表示可以简化,我们增加一个特征x0=1,这样h(xo,x1,.…xn)=θ0x0+θ1x1+..+θnxn。同样是线性回归,对应于上面的假设函数,损失函数为(此处在损失函数之前加上1/2m,主要是为了修正SSE让计算公式结果更加美观,实际上损失函数取MSE或SSE均可,二者对于一个给定样本而言只相差一个固定数值):
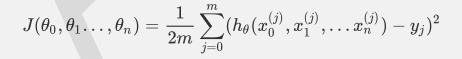
算法相关参数初始化:主要是初始化θ0,θ1..,θn,我们比较倾向于将所有的初始化为0,将步长初始化为1。在调优的时候再进行优化。
对θi的梯度表达公式如下:
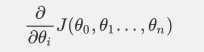
用步长(学习率)乘以损失函数的梯度,得到当前位置下降的距离,即:
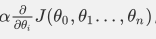
梯度下降法的矩阵方式描述
对应上面的线性函数,其矩阵表达式为:
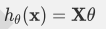
损失函数表达式为:
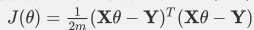
其中Y为样本的输出向量。
梯度表达公式为:
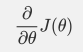
还是用线性回归的例子来描述具体的算法过程。损失函数对于向量的偏导数计算如下:
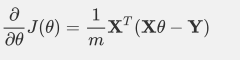
迭代:
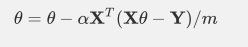
两个矩阵求导公式为:
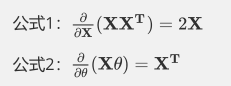
用Python实现梯度下降
import pandas as pdimport numpy as np
导入两个必要的包。
def regularize(xMat):inMat=xMat. copy()inMeans=np. mean(inMat, axis=0)invar=np. std(inMat, axis=0)inMat=(inMat-inMeans)/invarreturn inMat
定义标准化函数,不让过大或者过小的数值影响求解。
定义梯度下降函数:
def BGD_LR(data alpha=0.001, maxcycles=500):=np. mat(dataset)=np. mat(dataset).T=regularize(xMat)=xMat.shape=np. zeros((n,1)):=xMat.T*(xMat * weights-yMat)/m=weights -alpha* gradreturn weights
其中,dataset代表输入的数据,alpha是学习率,maxcycles是最大的迭代次数。
即返回的权重就是说求值。np.zeros 是初始化函数。grad的求取是根据梯度下降的矩阵求解公式。
本文参考B站博主菊安酱的机器学习。感兴趣的同学可以打开链接观看视频哟~
https://www.bilibili.com/video/av35390140
好了,梯度下降这个小知识点就讲解完了,下一期,我们将第一期与第二期的知识点结合,用手写数字的数据完成一次神经网络的训练。
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn





