博客 | 玩转「马里奥」的算法能搞定「口袋妖怪」吗?

雷锋网 AI 科技评论:现在机器人玩游戏的水平甚至已经超过了人类,然而对于不同的游戏,一个算法是否全部搞定呢?软件开发者 Shayaan Jagtap 就以「马里奥」这款游戏的算法无法适用于另一款游戏「口袋妖怪」为例,来说明这一问题并分析其中的原因。雷锋网 AI 科技评论全文编译如下。
现在,你很可能已经听说过机器人玩游戏的水平超过人类了吧。这些机器人的一种设计方法是给它们明确地编程,设定一组输入和一组输出之间的对应关系;或者也可以让它们自主学习、进化,它们就可以对同样的输入做出不同的反应,以期找到最优的对策。
一些闻名遐迩的机器人有:
AlphaZero:它是一个象棋机器人,经过 24 个小时的训练成为了世界最佳棋手。
AlphaGo:它是一个围棋机器人,因打败世界级棋手李世石和柯洁而闻名世界。
MarI/O:它是一个超级马里奥机器人,可以自学快速通过任意马里奥关卡。
这些游戏是复杂的,想要训练会玩这些游戏的机器就需要聪明地组合复杂的算法、反复的模拟,以及大量的时间。这里我重点谈谈 MarI/O,谈一下为什么我们不能采用相似的方法去玩转「口袋妖怪」这款游戏。(如果你不熟悉这款游戏的玩法,点击这里 https://www.youtube.com/watch?v=qv6UVOQ0F44 去观看视频。)
「马里奥」和「口袋妖怪」之间存在的三个关键差异点,可用来解释其原因:
第一,目标的数量
第二,分支乘数
第三,局部优化 VS 全局优化
下面,让我们就这三个因素来比较这两款游戏吧。
目标的数量
机器学习的方式是通过优化某种目标函数。无论是将(增强学习和遗传算法中的)反馈函数或者适应度函数最大化,还是将(监督学习中的)价值函数最小化,它的目标都是相似的:尽可能获得最佳成绩。
「马里奥」有一个目标:到达最后的关卡。简单来说,就是你在死之前到达的地方越远,你就玩得越棒。这是你唯一的目标函数,并且你的模型能力可以直接用这一数值来评估。
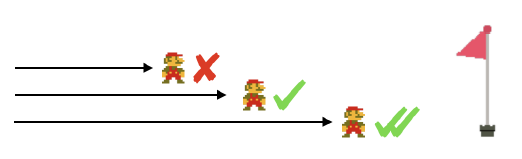
然而,「口袋妖怪」却有很多个目标。让我们尝试着去确定我们的目标。它是要打败「四大金刚」?抓住所有的口袋妖怪?训练一只最强大的队伍?我们的目标是刚才提到的所有这些,还是一切别的完全不同的东西?仅仅问到这个问题就很奇怪,因为答案可能是它们的个人主观性组合。
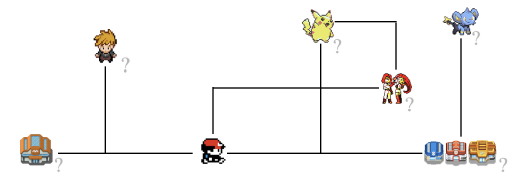
我们不仅仅需要去明确最终的目标,还要明确游戏的进程是什么样的,因此每一个动作带来的到底是奖励还是损失,都要对应到那一刻的许许多多中可能的选择中的某一种才知道。
这就引导我们进入到下一个论题。
分支乘数
简单来说,这个分支因子就是你在任意一步,能够做多少个选择。在象棋中,平均的分支乘数是 35;在围棋中,分支乘数是 250。对于之后每增加的一步,你有(分支乘数^步数)个选择来进行评估。
在「马里奥」中,你或者向左走、向右走、跳跃,或者啥也不做。机器需要评估的选择数量少,而且这个分支乘数越小,机器人通过计算能够预测到的未来就越远。
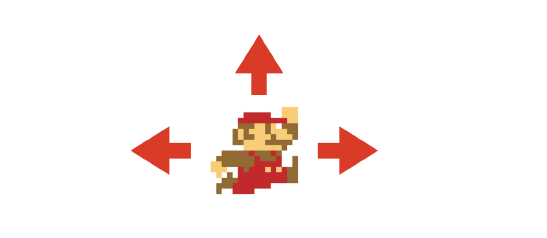
「口袋妖怪」是一个具有开放性世界的游戏,这意味着你在任一时间,都有大量的选择。简单地向上、下、左、右移动,对于计算分支乘数并不是一个有用的衡量标准。相反地,我们看重下一个有意义的动作。下一个动作是打仗,跟一个非玩家角色(NPC)交谈,又或者前往左、右、上下的下一个局部区域?当你在游戏中前进时,可能面临的选择数量会从多变到非常多。
一个能计算出最佳选择的机器,要求它考虑到它的短期和长期目标,这又带我们进入到最后一个论题。
局部优化 VS 全局优化
局部优化和全局优化可被看作兼有空间和时间上的意义。短期的目标和当前的地理区域被视为局部的,而长期目标和相对较大的区域例如城市甚至整个地图,被视为全局的。
将每一次移动分解成它的构成部分,会是将口袋妖怪问题分解成一个个小问题的方法。优化局部以实现从一个区域的点 A 到点 B 是简单的,但是决定哪个目的地是最佳的点 B,是一个更难得多的问题。在这里,贪婪算法就失效了,因为局部优化的决策步骤并不一定带来全局最优。
「马里奥」的地图小,并且是线性的,而「口袋妖怪」的地图却是大的、错综复杂的以及非线性的。当你追求更高阶的目标时,你的优先级在变化,并且将全局目标转变为优先的局部优化问题也不是一个简单的任务。这不是仅仅依靠我们当前配备的模型就能够应对的事情。
最后一件事
从机器人角度,「口袋妖怪」不仅仅是一个游戏。机器人都是单一任务的专家,而当遇到一个想要对战的 NPC 时,一个帮助你在地图中到处移动的机器人将无能为力。对它们而言,这是两个完全不一样的任务。

在对战时,每个回合都有很多个选择。选择使用哪个动作,换入哪个口袋妖怪以及什么时候使用不同的道具,都是它要独立处理的复杂的优化问题。经过查找,我找到了这篇文章 Gotta Code'em all! Machine Learning in Pokemon(文章地址:https://realworldcoding.io/machine-learning-in-pokemon-db32dcd96f33),文中作者阐述了其建立一个对战模拟器的过程。它是经过深思熟虑的,并且有着难以置信的复杂度,甚至不考虑道具的使用——而这是决定对战结果的一个关键因素。
目前为止,对于打造了在游戏中比我们的表现更好的机器人这一现实,我们应该感到欣慰。现在,这些游戏虽然涉及到了复杂的数学,但是其目标是简单的。随着 AI 的发展进步,我们将创造出这样的机器:它们能完全通过自己对复杂优化问题的学习,解决影响力日益增强的现实世界问题。请放心,还有一些事情是机器尚未打败人类的,其中就包括我们的童年游戏——至少现在是这样。
via:Shayaan Jagtap(Why Can a Machine Beat Mario but not Pokemon? ),雷锋网 AI 科技评论编译
全球AI+智适应教育峰会
免费门票开放申请!
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,于11月15日在北京嘉里中心举办全球AI+智适应教育峰会。美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell已确认出席,带你揭秘AI智适应教育的现在和未来。
扫码免费注册