一小时说服发那科合作,这家日本顶尖AI创业公司迈向“日本三强”产业链顶端|独家专访

撰文 | 微胖
认识 Preferred Network(以下简称 PFN),就像玩拼图。
很多人知道智能上色应用 PaintsChainer,但未必知道它只是这家公司的「副业」;
码农们都知道 PyTorch,但未必知道它的理念源自这家公司,他们研发出了全球最早动态图框架 Chainer;
工业界的人都知道发那科正在试水人工智能,但未必知道合作的这家创业公司还要做家用机器人;
当你将这些散落在不同人群目光下的板块拼在一起后,公司全貌才浮现在眼前:
全栈,并且还要全能。
PFN 研发的不仅仅是深度学习算法,还有简单好用的 Chainer(TM),一个开源深度学习框架。构建了日本最大的 GPU 集群,甚至自研了专用芯片。
业务跨度之大,更让这家创业公司显得与众不同。
不到 200 名成员的公司已经将深度学习应用到了汽车,制造和生物医疗等行业(日本实力最强的三个领域),而且还有个人机器人的计划。每个领域都充满挑战,一般创业公司通常只会专注某个领域。
2012 年,深度学习取得重要突破后,冈原大辅和西川彻注意到了深度学习的两个独特之处,可以将它应用到更加广泛领域中。
一方面,可以很容易处理非常高维的数据。高维数据的一个重要例子就是时间序列数据,这在工业设备的传感器数据中很常见;
另一方面,深度学习是无模型,不需要假设概率分布的先验知识,任何一个概率分布可以用足够复杂的神经网络来逼近。
2014 年,他们成立了 PFN。如果说公司设立之初,创始人曾犹豫业务支柱是否放在深度学习上,那么,2015 年春天对富士山脚下巨头公司的拜访,让他们确信制造将是应用深度学习专业知识的核心领域。
当谷歌、亚马逊等互联网巨头竞相训练系统理解语言时,能造出世界上最先进设备的日本制造业尚未得到开垦。

经历最初的怀疑之后,公司创始人冈原大辅 (左) 和西川彻 (Toru Nishikawa) 确信,他们应该把整个业务建立在深度学习的基础上。
如今,PFN 将图像识别技术用于制造过程中的视觉检测、仓库货架上的取物、机器故障预测,还扩展到了自动驾驶、生物医疗、智慧城市,公共安全等领域。公司估值超过 10 亿美元,成为日本最大、最有前途的人工智能公司,合作伙伴包括发那科、丰田、三井、松下、瑞惠金融、京都大学等。打开 innovation Japan 网页,第八个创新案例就是他们。
巨头们也开始攻城略地。
谷歌的 14 个机器人手臂可以分享知识并加快行动速度,他们也希望进入日本市场。亚马逊、微软、英伟达也虎视眈眈。
借用深度学习技术让机器人操作更加简单,也正在成为一个创业热点。一份对机器人报告网站全球数据库中 752 家机器人创业公司的分析显示,超过一半的创业公司都是以软件起家。
不过,他们担心的不是竞争对手,而是人才的引进与留存。
他们相信,与世界顶级机器人公司和其他制造商的密切关系,可以帮助他们深入了解客户的实际需求和所面临的挑战。
「与再造索尼相比,建立第二家索尼的速度更快。」两年前,接受《金融时报》采访的公司首席商务官(chief business officer)长谷川在谈及为何离开索尼加入这家创业公司时,曾这样说。
最近,PFN 首席研究官、研发 VP Shohei Hido 接受了机器之心的独家专访。以下是这次专访的主要内容。我们做了不更改原意的编辑。

Preffered Network 首席研究官、研发 VP Shohei Hido
与发那科合作
发那科在世界制造业的地位,一句话就可以表明,「如果富士山喷发,整个世界都会停止运转。」公司有三大块业务:FA(工厂自动化);Robot 以及 Robo-Machine(小型数控机床)。2015 年 8 月,发那科获得 PFN6% 的股权,计划将运行深度学习的机器人纳入不久的未来。2017 年 12 月,发那科再获得 PFN 额外股权。
目前,PNF 已经将 DL 应用到发那科三大块业务中,并取得了优于传统方法的效果,已商用。比如在 FA 中,将机器学习用于伺服器调整;在 Robot 中,将 DL 模型用于提升机器人抓取任务的学习效率与准确性;在 Robo-machine 中,利用机器学习技术预测和补偿由温度波动引起的热位移,与现有功能相比,加工精度提高了约 40%。
在谈及与发那科合作面临的主要挑战时,PFN 认为专业背景差异导致相互理解很难。计算机科学背景的码农没办法理解机械或控制理论术语。相应地,机器人工程师也没办法理解机器学习术语。为此,两家公司会定期面对面和视频会议,FANUC 也一视同仁地将 PFN 纳入公司的强制性培训课程。
机器之心:深度学习应用场景有很多,比如金融、零售,为什么最终选择制造业?
日本有大型银行、零售商和电子设备制造商,但大多比较保守,我们没有找到足够大的 AI 应用市场,也没有很好的成功机会。和发那科 CEO 稻叶善治交谈后,我们发现在机器人应用方面有很大潜力,他们也在寻找人工智能方面的合作伙伴。他们认为,将自己产品与市场上其他机器人产品(比如 ABB)区别开来的关键差异化因素,接下来会是基于 AI 技术的软件。
机器之心:彭博社报道你们谈了一个小时就成功说服发那科投资 900 万美金,还获得了数千台机器人的巨大数据流,怎么做到的?
我们是日本最有前途的创业公司。其实在会面之前,发那科就做了一些调查,也知道有我们这样一家公司,见面也是为了确认一下真假。在会面的当天早上(会面之前),稻叶先生已经知道 Tensorflow 发布的消息。这是一个很好的信号,他们很了解最新技术趋势。当然,我们的 CEO 也很善于谈判。
机器之心:发那科的 AI 战略是怎么样的?
一开始,也就是四到五年前,他们对 AI 并不如今天这样积极。当我们展示了一些应用成果后,比如机器人一夜之间就学会了 bin picking,了解到深度学习应用到机器人和其他机器上的机会,现在变得积极多了。一开始,我们只是和机器人业务合作,取得了一些进展后,也与其他业务板块(Robo-machine 和 FA) 合作。
合作后,发那科也成立了自己的人工智能实验室,研究人工智能技术。现在已经可以将新技术应用到程序中去,而不是完全依赖我们。在人工智能战略方面,发那科是领先市场竞争对手的。
机器之心:Bin picking 是机器人应用中最需要解决的问题之一,在深度学习的帮助下,发那科机器人抓取能力得到了哪些具体提升?
在这段最初的概念验证实验视频结尾处可以看到,抓取精度在 8 小时内就可以达到专家水平,这意味着如果花更多时间,它可以超过人类。

来自公司 Youtube 视频截图
机器之心:去年发那科推出了新功能 AI bin picking 是否采用了深度强化学习技术?
一开始,我们使用的有监督学习,而不是深度强化学习。因为强化学习很难控制获得很好的结果,用监督学习的方法解决问题更好一些。对于 bin picking 机器人来说,我们通过使用真实的机器人收集了监督学习训练数据集,不同情况下,很多时候会失败,偶尔也有成功,我们搜集有关拾取点的图像,进行监督学习,训练神经网络预测下一次抓取哪个点更容易成功。
机器之心:你们也正尝试将深度强化学习用到诸如 bulk Bin Picking 等更加广阔场景中,有商用案例吗?
目前还没有。
机器之心:这种技术落地最大的难点是什么?
深度强化学习很有前景,但是,很难控制获得好的结果,训练样本也不够,这个训练方法需要大量的数据样本训练模型。所以,就目前来说,深度强化学习的方法比监督学习的办法难很多。如果你有好的机器人模拟器,就能在虚拟环境中训练好的模型,如果没有合适的机器人模拟器,就很难通过使用深度强化学习训练好模型,因为你在真实世界的环境中并没有那样的 machine(机器)。模拟器是个关键因素。
机器之心:2018 年亚马逊机器人挑战赛(Amazon Picking Challenge)取消,有人认为这表明自主学习机器人发展远远低于预期,你们怎么看?
深度学习在解决感知问题上很发达,计算机可以看见世界。但是,对于机器人来说,抓取(grasp) 仍然很难,即便你使用 CV 和最先进抓取技术,仍然很难做好控制、优化(optimize),我认为这是当前机器人抓取任务最难的地方。
但是,我认为亚马逊去年取消挑战赛的原因,并非你说的那个。三年前,我们也参加过这个比赛。我们相信,亚马逊之所以这么做是因为最先进的深度学习对机器人技术的改变,并非一两年内的事情,所以没必要一年举办一次。
机器之心:深度学习在工业上的一个重要应用就是预测机械故障,尽可能早地检测传感器数据中的异常。现在许多工业机器已经变得可靠,以至于我们无法获得很多正 (即异常) 数据的样本,大大降低了预测准确性。你如何处理这个问题?
我们有一个针对时间序列传感器数据的异常检测算法(anomaly detection algorithm),可以训练出处理任何正常情况数据的检测模型,对目标系统正常状态下数据 normalness 建模,然后根据测试数据与正常状态差异程度,估计测试数据的异常值。如果一个新的输入数据在统计上是非常不可能的,我们确定输入数据是一个异常,标志着机器可能的未来故障。这个方法对工业机器人的故障预测非常有效,可以将监测到故障的发生时间,从几分钟前提升到几周前。
不过,我们仍然需要收集一些阳性异常样本来评估检测模型的正确性。与发那科合作进行第一次异常检测研究时,在一个加速实验中,为了收集阳性样本,他们让机器连续运转了几个月。
机器之心:一些跑在英伟达芯片上的经典深度学习模型(比如 alexnet VGG, googlenet),运行速度仍然满足不了工业案例对实时性的高要求,你们在这方面有些什么探索?
就吞吐量来说(主要就训练而言),并行使用更多 GPU 是一个解决办法。不过,我不能透露更多,考虑到更多现有客户案例情况。就模型推论的延迟来说,我们尝试加速 NN 模型,既会调整网络结构,也会调整系统(system)方面。我们研发了 Chainer-TensorRT 库,这个工具包可以用来将 Chainer 模型转化为 NVIDIA‘s TensorRT 推论引擎,进而可以在 GPU 上进行更快的推论。(1)另外,我们还研究了在英特尔 CPU 上快速运行 ONNX 模型,可以使用许多编程语言 (C/C#/Node..)(2)
机器之心:仿真环境与现实环境之间的现实差距也是个头疼的问题,你们尝试了怎样的解决方案?
我们在 2016 年日本高新技术博览会上展示了一个控制无人机的 demo,用的是一种叫「spiral learning」的 sim-to-real(从仿真到现实环境的迁移)技术。我们先在模拟器训练飞行模型,至少要先让无人机飞起来,接下来在真实环境中校准,不断弥合模拟和真实世界的鸿沟。这是个不断迭代的过程,直到模型收敛到一个好的策略。另外,我们是通过控制无人机击中虚拟旗帜来训练模型。无人机经不起撞击,掉在地上或者撞墙了,很容易就坏掉了。有了这个办法,我们可以用更少的无人机来测试。
机器之心:目前与丰田的自动驾驶合作进展如何?
自动驾驶研发合作项目还在进行,不过不方便透露这方面的进展情况。
机器之心:2019 年,深度学习在制造业和机器人领域的应用,你们认为值得关注的趋势有哪些?
很多事情,这个领域一直在变化。不过,听说亚马逊今年某些时候会推出(make) 自己的家用机器人,细节不是很清楚,但我们必须关注这个趋势。
家用机器人:深度学习技术的融合
我们已经习惯了用唤醒词唤醒智能音箱,然后简单地命令它执行一些简单的任务;我们已经习惯按下按钮,让扫地机器人自己工作。但是,你有没有想过用自然语言直接命令机器人执行一些简单的任务?这正是 PFN 2018ICRA 人机交互最佳论文的主要成果——他们提出了首个可处理无约束口语(Unconstrained Spoken Language)的系统,并能有效解决口语指令中的歧义。而且,他们创造性地将现有的边界框预测方法与自然语言处理技术融合在了一个简单框架中,机器人可以根据用户指令,拾取、归位房间物品,且运行速度和精度已经达到了实用水平,公司已经有明确的商业化打算。不难看出,除了与与制造业巨头合作,这家公司正在探索当前主要商业模式之外的可能,将触角伸向更为广阔的 C 端消费者市场,探索自己的商业模式。
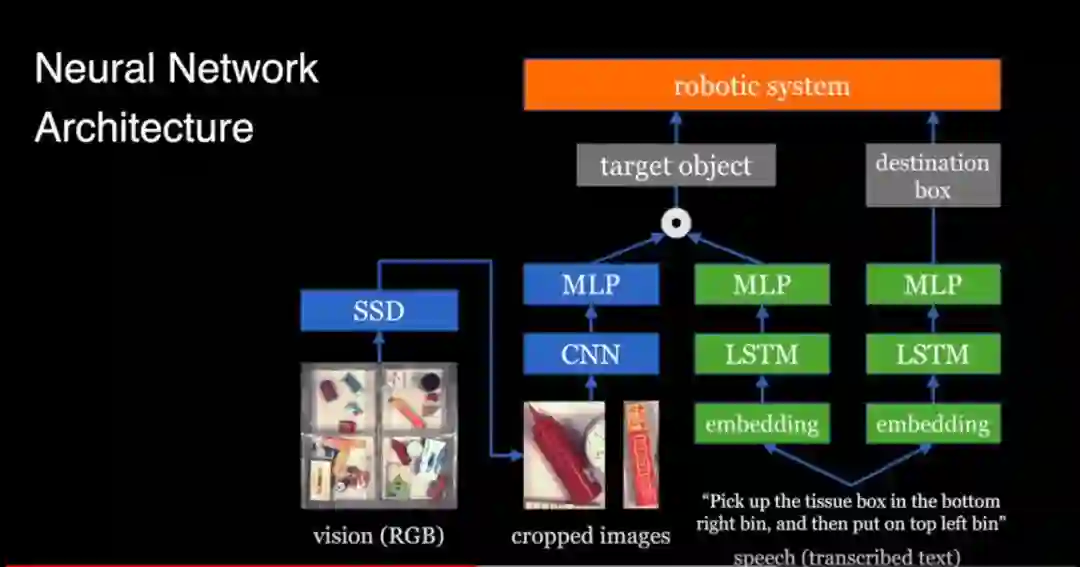
来自 Youtube 视频
机器之心:你们在 2018 年日本高新技术博览会上展示了一款整理(tidy) 家用机器人。家庭环境与工厂环境有很大不同,不仅更复杂,很多物品也不像工件那样易于抓取,你们做了哪些突破?
我们不仅使用了最先进的深度学习技术(CV 和 NLP),而且还将这些最先进的技术做了融合,让机器人变得实用。你可以通过自由表达的方式告诉系统需要收拾的玩具的具体位置,对话可以帮助系统提升完成任务的成功率。家庭环境很复杂,会出现各种各样的物品,我们相信深度学习可以解决感知方面的问题,但是让机器人成功抓取所有这些东西,还是很难。我们也在开展相关研究课题,比如针对末端执行器。不过,整理机器人不会很快上市。

机器之心:什么是无约束的口语指令?如何解决口语指令的模糊性问题?
这是我们在 ICRA 2018 会议上发表的研究成果。和传统的口语指令不同,无约束意味着,不需要担心如何发出命令,直接对机器人发出命令就可以了,比如 play music。一般的口语指令是有固定语法的,就像 Alexa 那样,需要念出「Alexa」唤醒词,再对 Alex 发出命令。为了解决传统口语指令系统不利于自由表达的问题,我们使用了基于神经网络模型的系统,它可以理解每个表达或命令的具体意思。
不过,难点在于需要搜集大量数据来训练模型,针对每一个物品、每个命令搜集很多相关表达数据,让机器可以理解。我们用众包的方式,搜集了足够大的口语指令数据集,因此训练数据集的多样性也更高,训练后的文本识别模型具有足够的泛化能力,可以识别一般的口语表达。
机器之心:融合这些不同深度学习技术最大的难点是什么?
非常依赖可用的计算资源。比如,针对新问题和既有模型引入一个新 trick 时,仅用一套固定超参数训练模型判断这个 trick 是否有效,通常一开始就会降低准确性。相反,你要再次调优所有参数,判断这个 trick 是不是真的见效。追求高效的深度学习研发工作,实验数量和速度非常重要。因此,在训练模型时,我们使用了自己的分布式深度学习框架,和专门的英伟达 GPU 集群(1500 多个),这也是目前这个领域最大的 GPU 集群之一。(3)另外,针对高效的超参调优,我们研发了开源库 Optuna,目前已经在公司广泛应用开来。(4)
机器之心:说到计算资源,你们也在研发自己的芯片,目前进展如何?
做自己的芯片,也是我们 CEO 的梦想。GPU 很有用,我们肯定会在自己的芯片旁继续使用它,但与此同时也需要有所替换,这也是为了解决我们的深度学习训练问题。就每瓦性能来说,我们的芯片性能更优,因为 GPU 是一个通用处理器,针对专门任务,会被专门芯片超越。去年 12 月,我们宣布了要自研芯片,我们计划 2020 年 4 月投入运营装有这个芯片的新型大型计算集群。
机器之心:有商业化整理机器人的计划吗?目前服务机器人商业化都不成功,家庭服务机器人商业化也会面临更多的难题,比如高昂售价就足以让用户望而却步,你们打算如何解决这个问题?
是的,我们确实有商业化的打算。研发、销售都需要大量投入,这些也会推高产品价格,一般的新兴创业公司(new born)很难搞定这些事情。如果未来需要给我们的产品投资,我们已经拥有与机器人有关的业务,比如与发那科在工业机器人方面合作,与丰田的合作,现在也在尝试医疗领域,这是我们独特的优势,也是其他新生的机器人创业公司所不具备的。
机器之心:如何看待 Rethink Robotics 的失败?
他们主要瞄准的是实验室和教研市场,而不是实际应用,比如发那科那样,优傲也很不错,简单、便宜、可以用于实际场景。他们选择的这个市场规模太小了,市场选择的问题。
公司与生态
日本初创公司的普遍成功模式是这样的:利用研究者在大学开发的技术,受到日本政府政策支持,并得到像大和房屋这样的大企业在资金上的支援,最终拿出有竞争力的产品,完成上市。一路走来的 PFN 也带有这样的色彩,不过 PFN 认为,如果公司由他们的投资者控制,那对每个人来说都会变得乏味。
机器之心:作为一家创业公司,你们不仅拥有全栈能力,而且业务多元,涉足制造业、自动驾驶、生物医疗等,每个领域难度都不小,业务之间的跨度也大,这一策略背后的逻辑是什么?如何驾驭业务的多元化?
我们也知道这样的战略很少见。但这些垂直领域的人工智能应用有交叉部分,可以帮助我们的技术规模化。另外,获取不用领域大型公司的资金支持,也有利于公司财务独立。我们不想单纯依赖某一个公司,或某一个消费群体,这是非常有风险的。同时发展许多方向,我们不仅可以更好的管理我们公司的产品组合,也可以帮助我们实现财务独立。
但也像你们说的,同时管理如此多元的业务(manage diverse different product)存在许多困难:不同领域有着不同的商业模式,不同的产品有不同的生命周期,在一个公司内同时运作这些项目,是很难横向对比每个项目的进度,也比较难管理的,这对我们管理团队来说是比较困难的。
你很难用单一的简单 kpi 对所有业务,去衡量各个项目的进度,因为有自己的时间轴和商业模式。如果你用一个简单的单一的数字去评估项目,那么管理团队是很容易评估项目和团队成员的。如果你没有那么简单的 kpi,那么评估项目进度,这时候就需要理解所有的细节,不光光是技术,还需要理解项目的商业模式,以及该产业中的一些商业习惯。
对于管理来说,有很多事情要做。我们的经验是,放弃简单管理的方式,而是管理团队必须学习公司的各个项目,理解每个领域,并且投入到团队中来,参与到用户学习中来。
机器之心:目前公司的主要商业模式是怎样的?有没有考虑向海外扩展业务?
B2B,与丰田、发那科等公司合作是我们目前主要的商业模式。同时,我们也在医疗健康、家用机器人等领域探索我们自己的商业模式。比如,在医疗健康领域,我们已经与在三井(美国)公司合作,我们在伯克利子公司负责这方面的工作。
机器之心:日本经济有着自己的特点,比如长期主导日本经济的是「Japan Inc」(日本传统的,高度集中的经济体系);日本市值最高的十家公司中并没有诸如谷歌、亚马逊、阿里、腾讯这样的互联网巨头,它们如何影响着日本的 AI 创业公司?
我们没有从 VC 那里获得投资,我们引入的都是产业资本。日本市值最高的公司大多都来自制造业,他们往往缺乏软件能力,这些正是我们的机会,不过同时也面临着国外巨头的竞争,比如谷歌云、亚马逊云,英伟达等公司提供的解决方案。
现在,如果你有十来个人,有一个 AI 项目,很容易就能获得几百万美元投资,情况比过去好多了。像中、美一样,日本的风投对 AI 创业公司也很感兴趣,2017 年是一个高峰,但这之后他们关注区块链,比特币更多。

注释:
1、https://github.com/pfnet-research/chainer-trt
2、https://github.com/pfnet-research/menoh/
3、https://www.preferred-networks.jp/en/tag/mn-1b
4、https://github.com/pfnet/optuna
推荐阅读:




