今日 Paper | 分布式表示;基于元学习;县级数据集;GPS-NET等

目录
句子和文档的分布式表示
基于元学习的场景自适应视频帧插值
美国对COVID-19的反应的县级数据集
跨域文档对象检测:基准套件和方法
GPS-NET:用于场景图形生成的图形属性传感网络
句子和文档的分布式表示
论文名称:Distributed Representations of Sentences and Documents
作者:Quoc Le /Tomas Mikolov
发表时间:2014/4/16
论文链接:https://cs.stanford.edu/~quocle/paragraph_vector.pdf
推荐原因
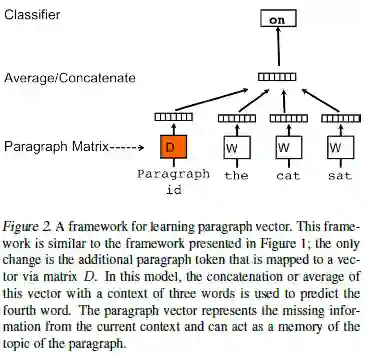
核心问题:这篇文章主要做了一个问题,就是如何表示一个文档或者句子的向量,过去我们常常学习到词向量,而这个工作进一步的提升,变为了如何表示整个句子的词向量。
创新点:本文应用了word2vec中词向量的训练方法,具体来说在每词输入的时候,都将文章的id进行输入,通过反向传播算法,此时文章id对应的embedding就是最终的文档的编码。
研究意义:文档的表示应用很多,如果能够得到一个非常好的文档表示,那么词向量的表示就可以进行省略了。
基于元学习的场景自适应视频帧插值
论文名称:Scene-Adaptive Video Frame Interpolation via Meta-Learning
作者:Choi Myungsub /Choi Janghoon /Baik Sungyong /Kim Tae Hyun /Lee Kyoung Mu
发表时间:2020/4/2
论文链接:https://arxiv.org/abs/2004.00779v1
推荐原因
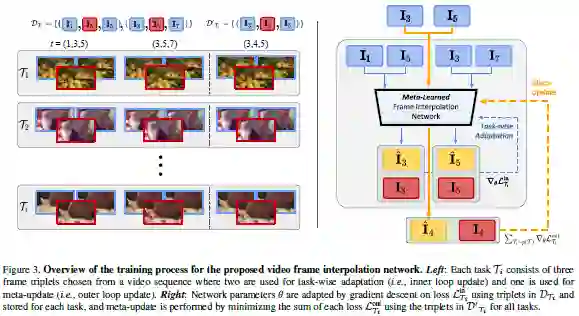
这篇论文被CVPR 2020接收,考虑的是视频帧插值的问题。
在这个问题中,根据前景和背景运动、帧速率和遮挡的变化,每个视频都有不同场景。因此具有固定参数的单个网络很难跨不同视频进行概括。理想情况下每个场景都可以有一个不同网络,但在实际应用的计算中是不可行的。这篇论文提出通过利用在测试时容易获得的其他信息来使模型适应每个视频。首先通过简单的网络微调来展示“测试时间自适应”(test-time adaptation)的好处,然后通过将其与元学习融合以显著提高效率。这篇论文表明仅需进行一次梯度更新即可获得显著性能提升,而无需任何其他参数。最后,这篇论文证明元学习框架可以轻松应用于任何视频帧插值网络,且可以在多个基准数据集上持续提高其性能。

美国对COVID-19的反应的县级数据集
论文名称:A County-level Dataset for Informing the United States' Response to COVID-19
作者:Killeen Benjamin D. /Wu Jie Ying /Shah Kinjal /Zapaishchykova Anna /Nikutta Philipp /Tamhane Aniruddha /Chakraborty Shreya /Wei Jinchi /Gao Tiger /Thies Mareike /Unberath Mathias
发表时间:2020/4/1
论文链接:https://arxiv.org/abs/2004.00756v1
推荐原因
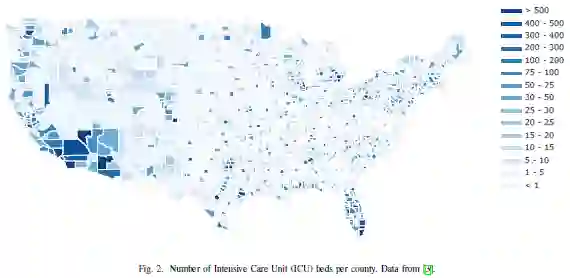
这篇论文为COVID-19的疫情研究者和政策制定者贡献了一个新的数据集,该数据集汇总了县级政府、新闻和学术来源的相关数据。除JHU CSSE COVID-19信息中心的县级时间序列数据外,该数据集还包含300多个变量,这些变量汇总了人口估计值、人口统计学、族裔、住房、教育、就业以及未来收入、气候、过境得分及与医疗保健系统相关的各项指标。此外,这篇论文汇总了每个县(包括杂货店和医院)各个景点的户外活动信息,并汇总了SafeGraph的数据。通过收集这些数据,并提供读取这些数据的工具,该文作者希望能够帮助研究人员调查疾病的传播方式以及哪些社区最能适应在家中工作。
跨域文档对象检测:基准套件和方法
论文名称:Cross-Domain Document Object Detection: Benchmark Suite and Method
作者:Li Kai /Wigington Curtis /Tensmeyer Chris /Zhao Handong /Barmpalios Nikolaos /Morariu Vlad I. /Manjunatha Varun /Sun Tong /Fu Yun
发表时间:2020/3/30
论文链接:https://arxiv.org/abs/2003.13197v1
推荐原因
这篇论文被CVPR 2020接收,考虑的是文档对象检测(Document Object Detection,DOD)的问题。
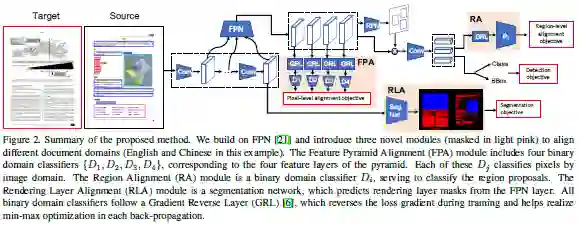
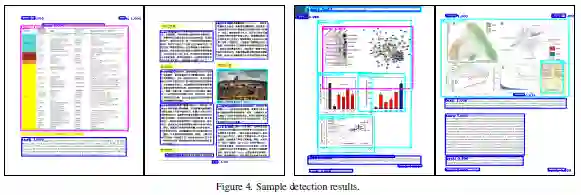
这篇论文研究跨域DOD,使用源域中的标记数据和目标域中的未标记数据来学习目标域的检测器。为此这篇论文建立了一个基准套件,其中包含可用于跨域DOD模型训练和评估的不同类型PDF文档数据集。对于每个数据集,这篇论文提供页面图像、边框标注、PDF文件及从PDF文件提取的渲染层。此外,这篇论文提出了一种新跨域DOD模型,该模型基于标准检测模型并通过合并三个新的对齐模块来解决域偏移:特征金字塔对齐模块,区域对齐模块和渲染层对齐模块。在基准套件上进行的实验证实了新方法的优越性。
GPS-NET:用于场景图形生成的图形属性传感网络
论文名称:GPS-Net: Graph Property Sensing Network for Scene Graph Generation
作者:Lin Xin /Ding Changxing /Zeng Jinquan /Tao Dacheng
发表时间:2020/3/29
论文链接:https://arxiv.org/abs/2003.12962v1
推荐原因
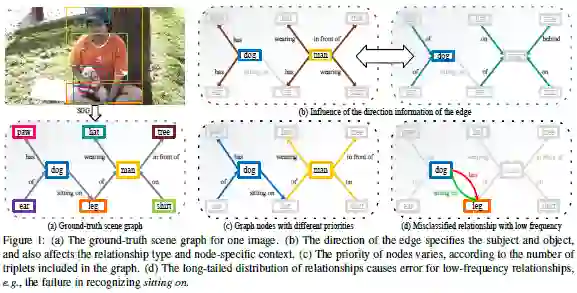
这篇论文被CVPR 2020接收,要处理的是场景图生成(Scene Graph Generation,SGG)问题,即检测图像中的对象及其成对关系。
这篇论文提出了一种图形属性传感网络(Graph Property Sensing Network,GPS-Net)。GPS-Net首先通过一种新的消息传递模块,使用特定于节点的上下文信息来增强节点特征,并通过三线性模型对边缘方向信息进行编码。其次,GPS-Net引入节点优先级敏感损失,以反映训练期间节点之间的优先级差异。第三,GPS-Net通过首先软化分布,然后根据每个对象对的视觉外观对其进行调整来缓解长尾分布问题。GPS-Net在三个数据库,即VG,OI和VRD上实现了当前的最佳性能。