![]()
作者:Julien Kervizic
翻译:陈之炎
校对:李海明
本文整理比较模型部署到生产中使用的不同部署模型方式、生命周期管理方法及数据存储格式。
Mantas Hesthaven拍的发表在 Unspash上的照片
机器学习模型的应用方法多种多样,不一而足。
例如,在客户流失预测中,当客户呼叫服务时,系统中便可以查找到一个静态统计值,但对于特定事件来说,系统则可以获得一些额外值来重新运行模型。
通常,有很多方法可以对模型进行训练,并将其转化为应用产品:
一次性训练
模型在应用前,无需进行连续的多次训练。通常情况下,在数据科学家完成对模型的特定训练之后,便可进行应用,待模型性能无法满足使用要求时,再对其进行更新。
通常,数据科学家会在Jupyter Notebooks环境中组建原型和使用机器学习算法。Jupyter Notebooks是repl上的高级GUI,可以在这个环境中同时保存代码和命令行输出。
采用这种方法,完全可以将一个经过特别训练的模型从Jupyter中的某个代码推向量产。多种类型的库和其他笔记本环境有助于加强数据科学家工作台和最终产品之间的联系。
Pickle
将python对象转换为比特流,并将其存储到磁盘以便后续重新加载。它提供了一种很好的格式来存储机器学习模型,亦可在python中构建其应用程序。
ONNX
为开放式神经网络交换格式,作为一种开放格式,它支持跨库、跨语言存储和移植预测模型。大多数深度学习库都支持该格式, sklearn还有一个扩展库来将模型转换为ONNX格式。
PMML
或预测模型标记语言,是另一种用于预测模型的交换格式。sklearn还有另一个扩展库,可用于将模型转换为PMML格式,这与ONNX是一致的。然而,它的缺点是只支持某些类型的预测模型,PMML从1997年开始出现,大量的应用程序均采用这种格式。例如:像SAP这样的应用程序能够利用PMML标准的某些版本,对于CRM应用程序(如PEGA)也是如此。
POJO
和MOJO是两种H2O.ai的导出格式,他们旨在为Java应用程序提供一个易于嵌入的模型。然而,这两种导出格式只在H2O平台上使用。
对一次性训练模型,可以由数据科学家专门对模型进行训练和精调,或者也可以通过AutoML库进行训练。通过简单设置,便可将模型产品化推进到下一个阶段,例如批训练。
批训练
虽然不是所有的模型都需要应用,但批训练可以根据最新的训练结果使模型的版本得到连续刷新。
批训练受益于AutoML框架,其通过AutoML能够自动执行一系列动作。例如:特征处理、特征选择、模型选择和参数优化。AutoML新近的表现与最勤奋的数据科学家不相上下,甚至超过了他们。
![]()
利用它们可以进行更为全面的模型训练,而不是做预训练:简单地重新训练模型的权重。
目前有多种不同的技术来支持连续的批训练,例如,可以通过多种混合 airflow来管理不同的工作流和类似tpot的AutoML库。
不同的云服务提供商为 AutoML 提供了各种解决方案,并把这些解决方案放到数据工作流中。例如,Azure将机器学习预测和模型训练与其数据工厂进行了整合。
实时训练
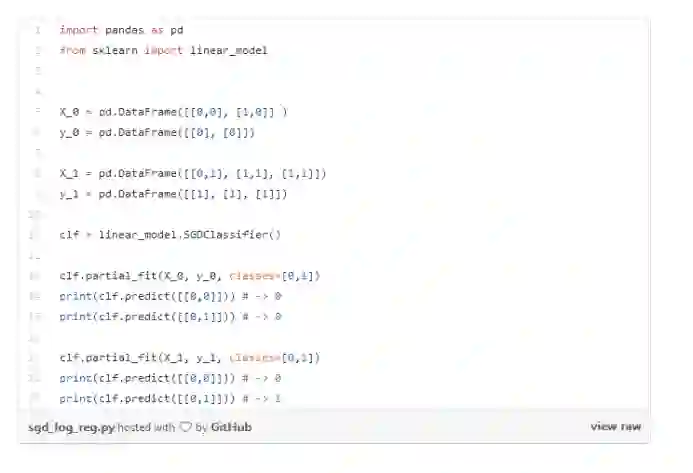
实时训练可以通过“在线机器学习”模型实现,支持这种训练方法的算法包括:K-均值(通过小批处理)、线性回归和Logistic回归(利用随机梯度下降)以及朴素贝叶斯分类器。
Spark中包含 StreamingLinear算法/StreamingLinearRegressionWithSGD算法来执行这些操作,Skinlear具有SGDRegressor和SGD分类器,可实现增量训练。在sklearn中,增量训练通过partial_fit方法完成,如下所示:
![]()
在部署这类模型时,需要严格的操作支持和监控,因为模型对新的数据和噪声很敏感,所以需要动态地监控模型性能。在离线训练中,可以过滤掉高位的点值,并对输入数据进行校正。当需要根据新的数据流不断更新模型训练时,难度系数会高出许多。
在线模型训练的另一个挑战是,过往历史信息得不到衰减。
这意味着,如果数据集的结构有新的变化,则需要重新对模型训练,这在模型生命周期管理中将是一个很大的挑战。
批量预测与实时预测的比较
当选择是设置批量预测还是设置实时预测时,必须了解实时预测的重要性。如果发生重大事件,有可能会获得新的分数,例如当客户呼叫联络中心时,客户流失评分又会是多少。在实时预测时,需要对这些因素进行加权,以克服由于进行实时预测而产生的复杂性和成本影响。
在进行实时预测时,需要有一种处理高峰负荷的方法。需要根据所采用的途径以及使用的预测如何结束,来选择一种实时方法,可能还需要有具有额外计算能力的超级机器,以便在某个SLA中提供预测。这与批量预测的处理方法形成了对比,在批量预测中,可以根据可用容量将预测计算分散到一整天。
在实时预测时,运营责任会更高一些,人们需要对系统是如何工作进行监测,在出现问题时有告警,并考虑到故障转移责任。
对于批量预测来说,运营责任要低得多,只需要对告警进行一些必要的监测,而对于了解产生问题的直接原因的需求要低得多。
实时预测也受成本因素的影响,一味追求高算力,而却没有选择将计算负荷分散在全天进行,可能会迫使你购买那些超出算力需求的硬件设备或提高现货价格。根据所用方法和需求,可能还需要投入额外的成本购买更强大的计算能力来满足SLA的需求。此外,在选择实时预测时,可能会有更高的架构要求。需要注意的是,在应用程序中,所做出的选择要依赖应用程序的预测,对于这样的特定场景,实时预测的成本最终可能会比批量预测的成本更低。
实时预测的预测性能评估比批量预测的预测性能评估更具挑战性。例如,当在短时间内遇到一连串的突发行为时,如何评估性能,会不会为特定的客户产生多个预测结果?实时预测模型的评估和调试要复杂得多,它还需要一个日志收集机制,既允许收集不同的预测结果和特征,也可以生成分数以供进一步评估。
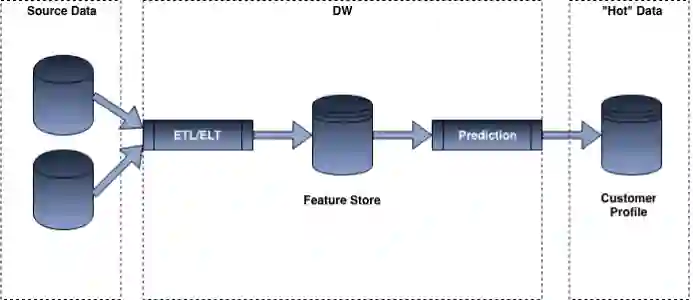
批量预测集成
批量预测依赖于两个不同的信息:一个是预测模型,另一个是提供给模型的特征。在大多数批处理预测体系结构中,ETL既可以从特定的数据存储(特征存储)中获取预先计算的特征,也可以跨多个数据集执行某种类型的转换,并向预测模型提供输入。然后,预测模型对数据集中所有的行数据进行迭代,并输出不同的分值。
![]()
一旦计算得到所有的预测结果,便可以将分数“投入”到那些有信息使用需求的不同系统中。可以根据不同的应用实例,并通过不同的方式来实现分数的使用。例如,如果想在前端应用程序上使用分数,则很可能将数据推送到“缓存”或NoSQL数据库:比如Redis,这样可以提供毫秒的响应;而对于某些用例,比如创建电子邮件,可能只是依赖CSV SFTP导出或将数据加载到更传统的RDBMS。
实时预测集成
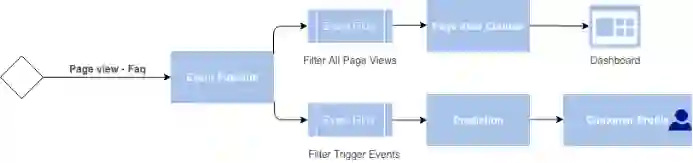
基于实时应用的模型使用需要3个基本组件:客户/用户配置文件、一组触发器和预测模型。
![]()
配置文件:客户配置文件包含和客户相关的所有属性,以及给出预测所必需的不同属性(例如:计数器)。对于客户级预测,为了减少从多个地方提取信息的延迟,以及简化机器学习模型的量产化过程,配置文件是必须的。在大多数情况下,为了更有效地获取数据,需要相似的数据存储类型。
触发器:触发器是引导进程启动的事件,它们可以用于客户流失的预测。例如调用客户服务中心、检查订单历史记录中的信息等。
模型: 模型需要经过预先训练,通常导出到前面提到的 3 种格式之一 (pickle、 ONNX 或 PMML) ,以便可以将其移植到量产中。
取决于数据库集成:诸多数据库供应商为在数据库中绑定高级分析用例做出了重大努力,既可以直接集成Python或R代码,也可以导入PMML模型。
利用Pub/Sub模型:预测模型本质上是对数据流的输入执行某些操作,例如提取客户配置信息等。
Webservice:围绕模型预测设置API封装器,并将其部署为Web服务。根据Web服务的设置方式,它可能执行或不执行驱动模型所需的数据操作。
inApp:也可以将模型直接部署到本地或Web应用程序中,并让模型在本地或外部数据源上运行。
数据库集成
如果数据库的总体大小不大 (用户配置文件<1M),并且更新频率也不大,那么将一些实时更新过程直接集成到数据库中会很有意义。
Postgres允许将Python代码作为函数或称为PL/Python的存储过程来运行。该实现可以访问所有作为PYTHONPATH的一部分库,也可以使用Pandas和SKLearning等库来运行某些操作。
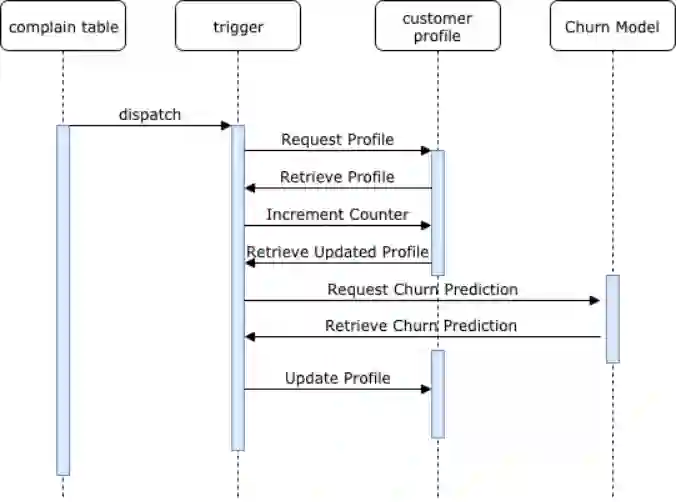
此外,还可以与Postgres的触发器机制相结合来运行数据库,并更新客户流失分数。比如,如果在投诉表中输入了一个新条目,那么让模型实时重新运行的话便很有价值。
![]()
新事件: 当在投诉表中插入新行时,将生成事件触发器。
触发器: 触发器功能将更新该客户在客户配置文件表中提出的投诉数量,并为客户更新记录。
预测请求:使用PL/Python重新运行客户流失模型并检索预测结果。
Different databases are able to support the running of多种数据库支持Python脚本的运行,如前所述, Postgres集成有本地Python, MSSQL Server也可以通过其“机器学习服务(在数据库中)”运行R/Python脚本,诸如Teradata等其他数据库可以通过外部脚本命令运行R/Python脚本。Oracle通过其数据挖掘扩展支持PMML模型。
Pub/Sub
通过pub/sub模型实现实时预测,可以通过节流正确地处理负载。对于工程师而言,这也意味着可以通过一个单独的“日志”提要来输入事件数据,不同的应用程序均可以订阅这个提要。
![]()
页面查看事件被触发到特定的事件主题,在该主题中,两个应用程序订阅一个页面查看计数器和一个预测器。这两个应用程序都从主题中筛选出特定的相关事件,并在该主题中使用不同的消息。页面查看计数器为仪表板提供数据,而预测应用程序则负责更新客户配置文件。
![]()
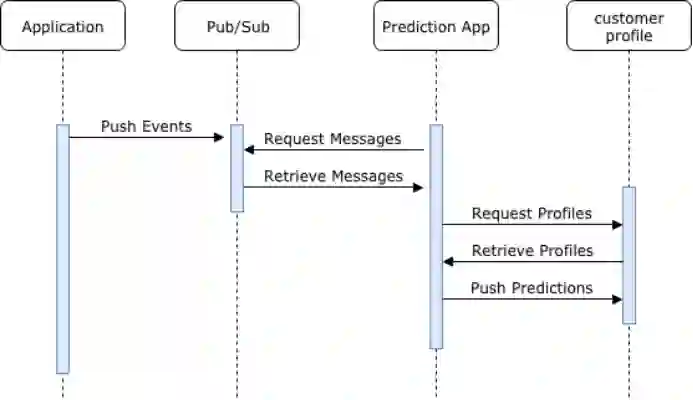
事件消息在发生时被推送到pub/sub主题,预测应用程序会轮询新消息的主题。当预测应用程序检索到新消息时,该程序将请求并检索客户配置文件,并使用消息和配置文件信息进行预测,预测结果最终返回客户配置文件以供进一步使用。
还可以设置一个稍微不同的流程:数据首先被一个“富集应用程序”使用,该应用程序将配置文件信息添加到消息中,然后返回一个新主题,并最终交由预测应用程序推送到客户配置文件上。
您会发现,在数据生态系统中支持这种用例的典型的开源组合是Kafka和SPark流的组合,但是云上可能有不同的设置。值得注意的是:Google发布的pub-sub /数据流(BEAM)提供了一个很好的替代方案,在Azure上,Azure-Service总线或Eventub和Azure函数的组合可以作为一种很好的方式来利用消息生成这些预测。
我们还可以将模型作为互联网服务产品。将预测模型作为互联网服务产品对于工程团队尤为有用,这些团队通常需要处理Web、桌面和移动等多个不同的接口。
当发生大量交互,并且使用本地缓存与后端系统的同步,或者当需要在不同的粒度上进行预测时,比如:在进行基于会话的预测时,通常建议使用第二种方法。
使用本地存储的系统往往具有还原功能,其作用是计算客户配置文件的内容,因此,它提供了基于本地数据的客户配置文件的近似值。
![]()
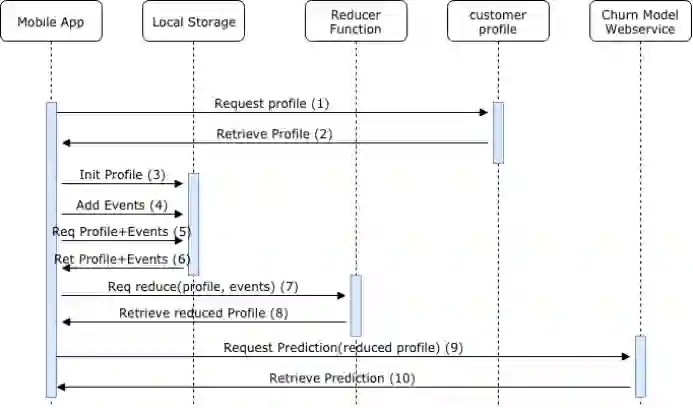
使用移动应用程序处理预测的流程可分为4个阶段进行描述:
应用程序初始化(1至3)阶段:应用程序初始化,向客户配置文件发出请求,检索其初始值,在本地存储中初始化配置文件。
应用程序(4)阶段:应用程序将与该程序中出现的不同事件存储到本地存储区的数组中。
预测准备阶段(5-8):如果应用程序想要检索一个新的客户流失预测,那么它需要将互联网服务所需的信息准备好。首先对本地存储进行初始请求,并检索客户配置文件的值及其存储的事件数组,检索完成后,向还原器函数提出请求,将这些值作为参数,还原器函数输出一个更新后的客户配置文件,并将本地事件合并到这个客户配置文件中。
Web服务预测阶段(9至10):应用程序向客户流失预测的互联网服务产品发出请求,将第8步骤中的有效载荷提供给更新后的客户配置文件。然后,互联网服务产品可以使用载荷提供的信息生成预测并将其值输出给应用程序。
AWS Lambda函数、GoogleCloud函数和MicrosoftAzure函数(尽管目前只支持Beta版Python)提供了一个易于设置的界面,可以轻松地部署可伸缩的Web服务。
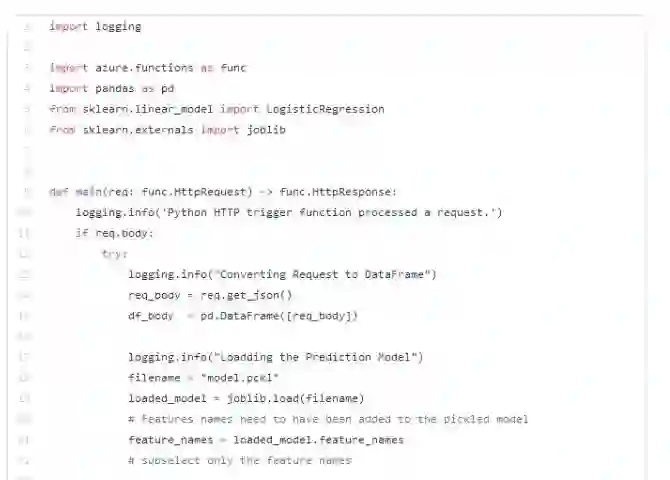
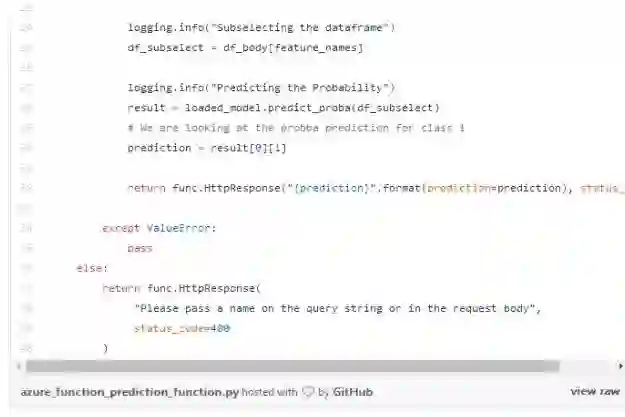
例如,在Azure上,可以通过如下函数实现web-service预测:
![]()
![]()
除了函数之外的另一种选择是通过docker容器(AmazonECS、Azure容器实例或Google Kubernetes引擎)部署一个Flask或Django应用程序。例如,Azure通过“AzureMachineLearning服务”提供了一种简单的方法来设置预测容器。
不同的笔记薄提供商,如Databricks和dataiku,都致力于简化其环境中的模型部署。它们具有将webservice设置到本地环境或部署到外部系统(如Azure ML服务、Kubernetes引擎等)的功能。
应用程序内部
在某些情况下,因为法律和隐私的要求,不允许数据被存储在应用程序外部时,或者必须上传大量文件时,往往会在应用程序内部调用模型。
Android-MLKit 或 Caffe2类似的工具允许在本地应用程序中调用模型,而Tensorflow.js和ONNXJS允许直接在浏览器中或在JavaScript的应用程序中运行模型。
需要综合考虑的几点
除了模型的部署方法外,部署模型到量产时需要考虑以下重要因素。
模型本身的复杂程度,是应首先要考虑的因素。像线性回归和Logistic回归这样的模型非常容易部署,通常不会占用太多的存储空间。使用更为复杂的模型,如神经网络或复杂集成决策树,计算将占用更长时间,冷启动时加载到内存中的时间也会更长,而且运行成本会更高。
需要着重考虑的是实际应用中的数据源与用于训练的数据源之间可能存在的差异。虽然用于训练的数据必须与生产中实际使用数据内容同步,但是重新计算每个值以使其完全同步是不切实际的。
建立一个实验框架,用于客观度量不同模型性能的A/B测试,并确保有足够的跟踪来准确地调试和评估模型的性能。
小结
选择如何将预测模型部署到生产中是一件相当复杂的事情,可以有多种不同的方法来处理预测模型的生命周期管理,也可以用不同的格式来存储它们,从多种方法中选取恰当的方法来部署模型,包含非常宽泛的技术含量。
深入理解特定的用例、团队的技术和分析成熟度、整体组织结构及其交互,有助于找到将预测模型部署到生产中的正确方法。
原文标题:
Overview of the different approaches to putting Machine Learning (ML) models in production
原文链接:
https://medium.com/analytics-and-data/overview-of-the-different-approaches-to-putting-machinelearning-ml-models-in-production-c699b34abf86
编辑:黄继彦
校对:王欣
陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
![]()
点击“阅读原文”拥抱组织