独家 | 带你认识机器学习的的本质(附资料)

作者:Matthew Mayo
翻译:张玲
校对:李洁
本文约2200字,建议阅读10分钟。
本文总结了四种机器学习主流定义,分别从学习的优化过程、计算力、相似性和算法,研究了先驱者们和著名研究员们对机器学习本质的理解。
这是一篇不是十分正式的文章,旨在探讨机器学习的本质。毫无疑问,过去你已经读过许多关于机器学习的深度或半深度的文章,并探索了它与众多其他主题的关系。当讨论这样复杂的概念,最好从最初的一些共同参考资料开始。可问题是,对于机器学习这样的主题,存在着无数这样的参考资料。
所以我想,为什么不深入研究下这些参考资料呢?
来源:https://imarticus.org/what-is-machine-learning-and-does-it-matter/
干脆我们来探讨一下机器学习的定义,将其视作是一个语义学的练习。
汤姆米切尔(Tom Mitchell)
第一个定义,是我个人最喜欢的,由著名的计算机科学家、机器学习研究员,卡内基梅隆大学的汤姆米切尔(Tom Mitchell)教授提出。
对于某类任务T和性能度量P,如果一个计算机程序在某些任务T上以P度量的性能随着经验E的增加而提高,那么我们称这个计算机程序是在从经验E中学习[1]。
Mitchell的这个定义在机器学习领域中是众所周知的,而且是经过时间验证的,这句话首次出现在Mitchell 1977年出版的《Machine Learning》一书中。
这句话对我有很大的影响,多年来我多次提及它,在硕士论文中也引用了它。此外,Goodfellow、Bengio 和 Courville最新出版的权威著作《Deep Learning》中,这段引文在其第5章中格外显眼,因为他们将其作为该书解释学习算法的起点。
图1是Mitchell定义范式的说明。
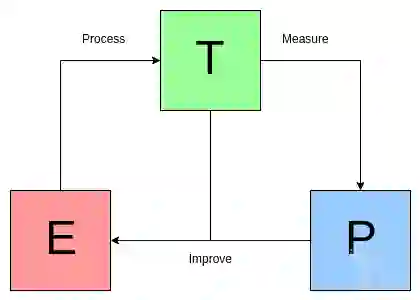
图1:Mitchell 定义范式
伊恩·古德费罗(Ian Goodfellow)、约舒亚·本吉奥(Yoshua Bengio)和亚伦·库尔维尔(Aaron Courville)
提到伊恩·古德费罗(Ian Goodfellow)、约舒亚·本吉奥(Yoshua Bengio)和亚伦·库尔维尔(Aaron Courville),就不得不提他们合著的《Deep Learning》,其中对机器学习的定义是这样的:
机器学习本质上属于应用统计学,更多地关注如何利用计算机对复杂函数进行统计估计,而不太关注如何估算这些函数的置信区间[2]。
在实际应用中,不再使用Mitchell对机器学习的定义,原因是它没有规范性地给出如何实现优化的说明,只是侧重于说明与机器学习优化过程相关的特定组件。相反,《Deep Learning》中对机器学习的定义实际上则更规范些。它指出,当不再强调传统的置信区间时,应当最大化利用计算力(实际上强调了对计算力的利用)。
伊恩·威腾(Ian Witten)、埃贝·弗兰克(Eibe Frank)和马克·霍尔(Mark Hall)
在我看来,另一个特别值得关注的机器学习定义来自Witten, Frank & Hall 所著的《Data Mining: Practical Machine Learning Tool and Techniques》,这是我完整地阅读有关这个主题的第一本书。这本书很少涉及数学,但有很多实用性的解释,所以一直以来都是我为机器学习领域新手推荐必读书目的首选(可能有偏见)。
他们最开始探讨机器学习定义的方式有些零散,试图在机器学习和数据挖掘的背景下将学习、性能和知识的概念组合在一起。离题部分已被剔除,以下是值得关注的引文:
我们感兴趣的是新情境下性能的提升或者是性能提升的潜力。
当以一种可以使自身在未来表现更好的方式改变自己的行为时,就是在学习。
学习意味着思考和目标,必须有目标地去学习。
经验表明,在机器学习和数据挖掘的许多应用中,获得清晰的知识结构,即结构化描述,以及在新实例预测中表现良好的能力,这两者至少是同样重要的。人们通常使用数据挖掘来获取知识,而不仅仅是用来预测[3]。
“数据挖掘”这个术语是机器学习的补充术语的说法是不需要关注的。上述引文出自这本书的第3版,出版于2011年,当时数据挖掘比现在更有吸引力;删掉数据挖掘的相关内容,本书仍然适用于机器学习本身。
不管怎样,虽然Witten, Frank & Hall在序言中贬低了他们想要偏离哲学性的希望,他们实际上做了一项非常棒的工作,变得有一些哲学性。这本书提供了有一定帮助作用的摘录,因为它为机器学习的定义提供了一个不同的角度:Mitchell专注于优化过程的特定组件,Goodfellow、Bengio和Courville倾向于更规范的定义,指出计算力的相对重要性,而这本书则尝试关注“学习”的哪些方面在机器学习过程中是相似的和重要的。上述引文还提供了重要的一点,颇具哲学性和实用性,即在最后一段中指出,获得知识和使用知识的能力都是机器学习的重点部分(见训练和推理)。
克里斯托弗·毕肖普(Christopher Bishop)
让我们来看看最后一篇文章-学者Christopher Bishop的《模式识别和机器学习》对机器学习的定义。值得注意的是,Bishop并没有开门见山地定义这个术语,而是以算法为中心,间接地为机器学习提供了非常好的定义(在数字分类任务中讨论到)。
机器学习算法的结果可以表示为一个函数 y (x),输入新数字图像 x,产生向量 y,用同样的方法编码来作为目标向量。在训练阶段(即学习阶段),根据训练数据确定y (x)精确的形式。一旦训练完模型,就可以用它来确认测试集中新数字图像的类别,正确分类新数字图像的能力被称为泛化,这些新数字图像不同于训练时的数字图像。在实际应用中,输入向量的多样性使得训练数据只能包含所有可能输入向量中的一小部分,因此泛化是模式识别的核心目标[4]。
首先,当谈论“模式识别时”,我们讨论的是有监督机器学习,而不是无监督学习或强化学习(或其他形式的机器学习)。第二,更重要的是,这是唯一一个阐述机器学习处理步骤的定义,无论这些步骤在这个示例中是否简短。同样有趣的是,随后的内容以及Bishop书一半的篇幅简述了许多额外的机器学习概念,并将它们很好地结合在一起。这本书提供了具有可读性的概述而没有陷入数学的泥潭中(大部分内容做到了这一点)。
所以,我们有四种定义机器学习的方法:
第一种是根据优化过程,抽象地定义机器学习;
第二种是更具规范性的定义,指出计算力在机器学习中的重要性;
第三种是关注“学习”哪些方面在机器学习过程中是相似的和重要的;
最后一种是从算法角度概述机器学习。
这些定义都没有错误,但都不是完整的。
这不仅仅是语义学的任务,探讨先驱者们和受人尊敬的学者们所认为的“机器学习”定义将有助于扩展我们自己对机器学习的定义。
参考资料:
[1] Machine Learning, Tom Mitchell, McGraw Hill, 1997.
http://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/mlbook.html
[2] Deep Learning, Ian Goodfellow, Yoshua Bengio & Aaron Courville, MIT Press, 2016.
https://www.deeplearningbook.org/
[3] Data Mining: Practical Machine Learning Tools and Techniques (3rd ed.), Ian Witten, Eibe Frank & Mark Hall, Morgan Kaufmann, 2011.
https://www.cs.waikato.ac.nz/ml/weka/book.html
[4] Pattern Recognition and Machine Learning, Christopher M. Bishop, Springer, 2006.
https://www.springer.com/gp/book/9780387310732
原文标题:
The Essence of Machine Learning
原文链接:
https://www.kdnuggets.com/2018/12/essence-machine-learning.html
编辑:王菁
校对:林亦霖
译者简介

张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无境,数据工作充满挑战。感谢数据派THU提供如此专业的平台,希望在这里能和最专业的你们共同进步!
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THU ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织




