血虐人类天梯玩家,DeepMind星际2 AI现身Nature
作者 | 杨晓凡
编辑 | 唐里
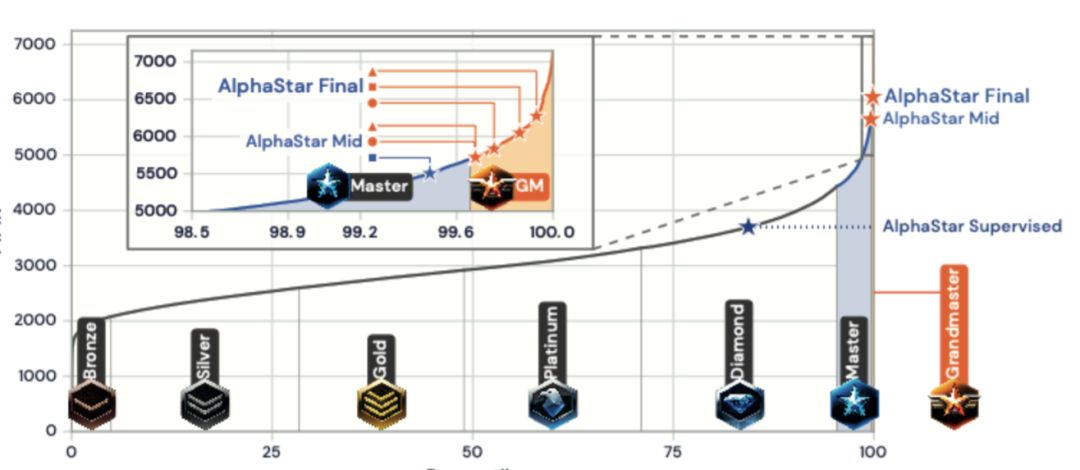
游戏 AI 的新进展接连不断,昨晚 DeepMind 发表推特和博客表示他们的星际 2 AI「AlphaStar」的论文已经被 Nature 杂志接收,最重要的是补上了大规模 1v1 人类对局的实验结果。而这个结果也是令人钦佩的:在星际 2 欧服的大约九万名玩家中取得了「Grandmaster」的段位,天梯排名达到所有活跃玩家的前 0.15%(在九万名玩家中相当于前 150 名以内)。这样的水准直接参加星际 2 天梯比赛可谓是「炸鱼」般的存在,一路被血虐的人类玩家不知道有没有怀疑过自己到底碰上的是 AI 还是职业选手(笑)。
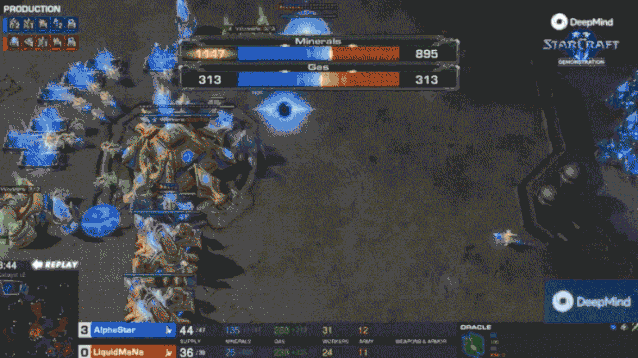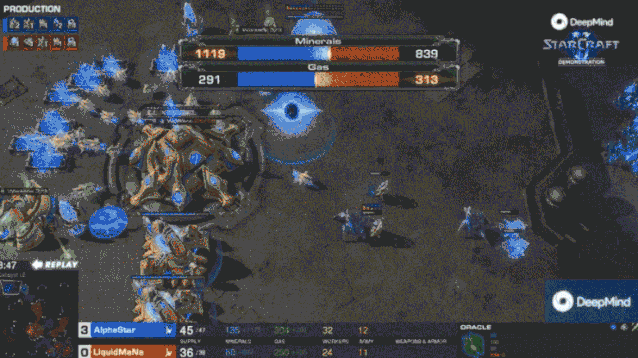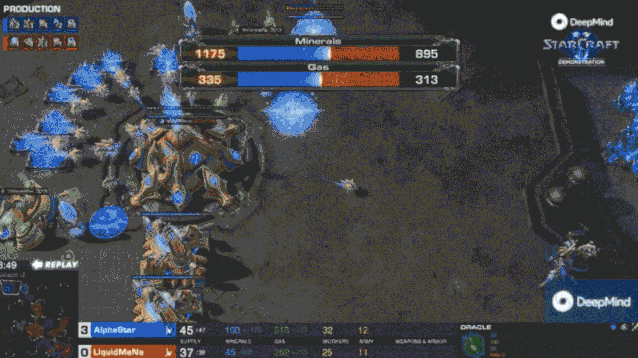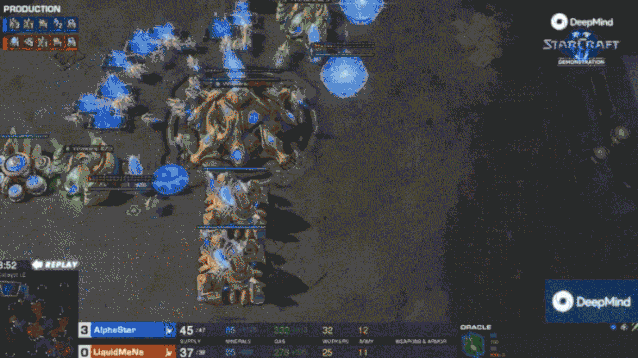
一月的比赛中,AlphaStar 会建造大量工人,快速建立资源优势(超过人类职业选手的 16 个或 18 个的上限)

一月的比赛中,AlphaStar 控制的两个追猎者黑血极限逃生
AlphaStar 是如何走到这一步的?
技术方面,今年一月 DeepMind 就公开了 AlphaStar 和人类职业选手的一些测试比赛对局,并解释了许多 AlphaStar 中重要的技术原理,包括:
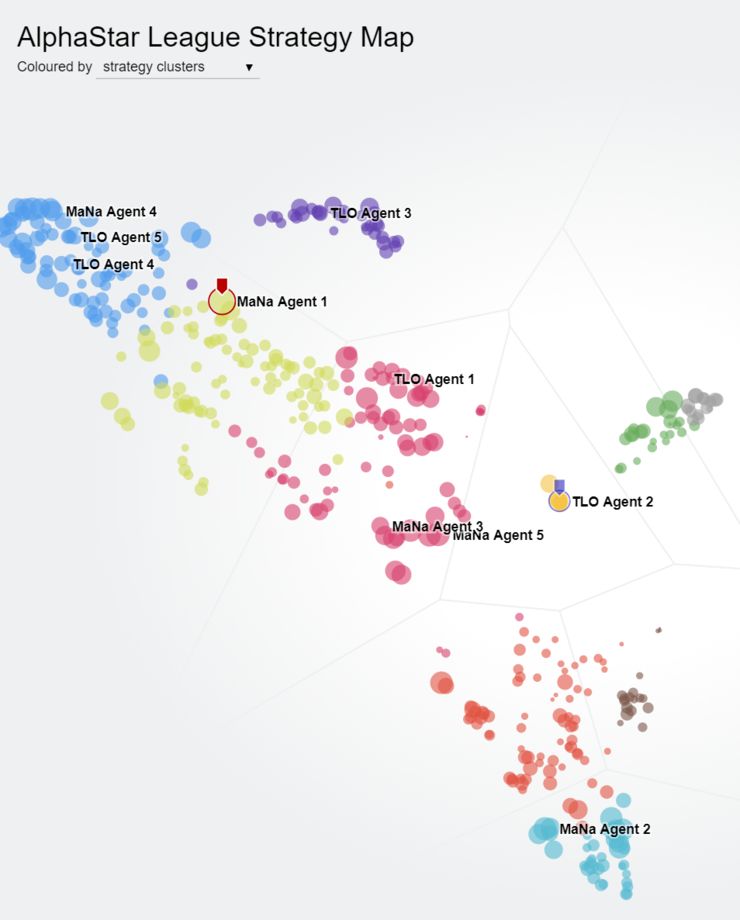
AlphaStar league 中的个体形成了明显的策略分布
今年 7 月,DeepMind 准备 AlphaStar 论文的 Nature 版本,并准备进行大规模人类 1v1 比赛作为论文中的重要实验的时候,他们也曾发出预告。而且,其实 1 月时和人类比赛的 AlphaStar 版本中有一些设定对 AI 有偏袒,这次进行大规模比赛的版本中进行了修改,以便更公平,也更好地体现 DeepMind 的科研水准。这些改动包括:
-
一月的版本可以直接读取地图上所有的可见内容,不需要用操作切换视角,这次需要自己控制视角,和人类一样只能观察到视野内的单位,也只能在视野内移动单位; -
一月的版本仅使用了神族,这次 AlphaStar 会使用人族、虫族、神族全部三个种族; -
一月的版本在操作方面没有明确的性能限制,这次,在与人类职业选手共同商议后,对 AlphaStar 的平均每秒操作数、平均每分钟操作数(APM)、瞬时最高 APM 等一些方面都做了更严格的限制,减少操作方面相比人类的优势。 -
参与测试的 AlphaStar 都是从人类比赛 replay 和自我比赛中学习的,没有从与人类的对局中学习。
除此之外,AlphaStar 的表现会在整个测试期间保持不变,不进行训练学习;这样得到的测试结果能直接反应 DeepMind 目前的技术水准到达了怎么样的水平。另一方面,作为 AlphaStar 技术方案的一大亮点,参与测试的 AlphaStar 也会是 AlphaStar 种群(AlphaStar league,详见下文)中的多个不同个体,匹配到的不同 AlphaStar 个体可能会有迥异的游戏表现。
这个新版的 AlphaStar 一共经过了 44 天的训练,然后在星际 2 天梯上(在暴雪的帮助下)用各种各样的马甲进行比赛,以免被玩家轻易发现。最终达到了星际 2 欧服的「Grandmaster」段位,以及所有活跃玩家的前 0.15% 排名。
AlphaStar 是怎样一个里程碑?
首先,星际 2 是一个不完全信息游戏(博弈),战争迷雾隐藏了对手的许多信息,AI 需要具有探索、记忆甚至推测的能力才能获得更好的表现。
其次,虽然 AlphaStar 和围棋 AI AlphaGo 一样都是以自我对局作为重要的训练策略,但在星际 2 中,策略的遗忘和互相克制更加明显,并没有某一个策略可以稳定地胜过所有其他的策略,所以继续使用简单的自我对局学习会让智能体陷入在不同策略间游移但水平停滞不前的境地。为了应对这个问题,DeepMind 采用了群体强化学习的训练策略(上文中提到的 AlphaStar league),用一个群体中许多不同个体的各自演进来保存并持续优化各种不同的游戏策略。
星际 2 还具有很大的行为空间,比如每个玩家可以同步做出行动、每个行动可以有不同的时间长短、位移和移动都是空间连续的、攻击防御技能物品等还有很多的变化,要比围棋的行为空间大很多。为了应对这样的行为空间,DeepMind 不仅使用了模仿学习找到优秀的初始策略,而且借助了一些网络设计技巧来明确智能体对策略的使用和切换,以及使用策略不在线的强化学习算法,让旧策略完成的比赛也能帮助新策略的学习。除此之外,DeepMind 还发现,对于这么大的行动空间,许多在其他任务中能起到帮助的强化学习技巧已经变得帮助不大了,这对整个强化学习领域来说也是新的发现。
在越来越困难的任务中,使用了基于学习的智能体、借助自我对局持续进化的开放目标的学习系统已经展现出了越来越好的表现。这次在 AlphaStar 的例子里,大规模比赛结果已经表明通用化的学习方法完全可以拓展 AI 系统的规模,让它在复杂、动态、多玩家的环境中发挥出良好的表现。在 DeepMind 看来,开发 AlphaStar 的过程中涉及的技术都可以帮助他们未来开发出更安全、更鲁棒、更有用的通用 AI 系统,最好还能够对真实世界问题的研究解决带来帮助。
参考资料:
1、AlphaStar 论文 Nature 版:https://doi.org/10.1038/s41586-019-1724-z
2、AlphaStar 论文开放阅读版:https://storage.googleapis.com/deepmind-media/research/alphastar/AlphaStar_unformatted.pdf
3、参考 deepmind.com/blog






