从一键整容到一键毁容,CNN变身网红克星。

先告诉各位一个好消息,号称“亚洲四大邪术之首”的PS大法,即将被PS的出品公司Adobe“制服”。
Adobe 官方在6月份发布了一篇文章,其中提到:虽然他们对 PS 和其他创意工具对世界产生的影响感到自豪,但他们也认识到技术伦理的含义。
于是Adobe联合加州大学伯克利分校为了“反PS”研发出了一个新技术。
新技术基于训练卷积神经网络(CNN),识别出人像照片中被液化的痕迹,并用RGB流(改变像素的红色,绿色和蓝色值)显示出修改范围和程度,甚至后续可以还原出原图!
而液化几乎可以说是大家利用PS修图、美颜中最最最核心的工具了。
这项技术能够99%正确识别面部液化痕迹,相当于未来我们人人都拥有悟空一样的火眼金睛,让P图怪无从遁形,让世间再无照骗。到时候就是网红们的末日了,想想还有点小兴奋那。
如果说Adobe的新技术是悟空的火眼金睛,那卷积神经网络(后续简称CNN)就相当于是被悟空偷吃的金丹。
而小七今天要送给大家制作金丹的秘籍!
小七决定把售价469元的【深度学习第四期】中第二课《CNN从入门到高级应用(上)》的课件送给大家。
神经网络与卷积神经网络
DNN能用到计算机视觉上吗?
为什么需要CNN?
卷积神经网络和人工神经网络的差异在哪?
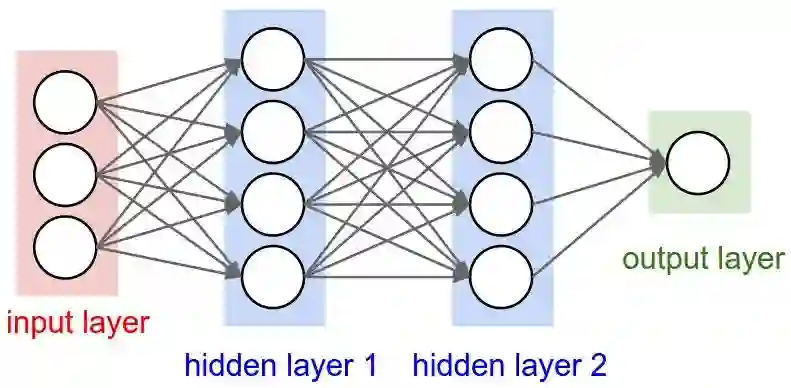
1、CNN的层级结构
保持了层级网络结构
不同层次有不同形式(运算)与功能

主要有以下层次:
(1)数据输入层/ Input layer
(2)卷积计算层/ CONV layer
(3)激励层/ Activation layer
(4)池化层/ Pooling layer
(5)全连接层/ FC layer
(6)Batch Normalization层(可能有)
(1)数据输入层/ Input layer
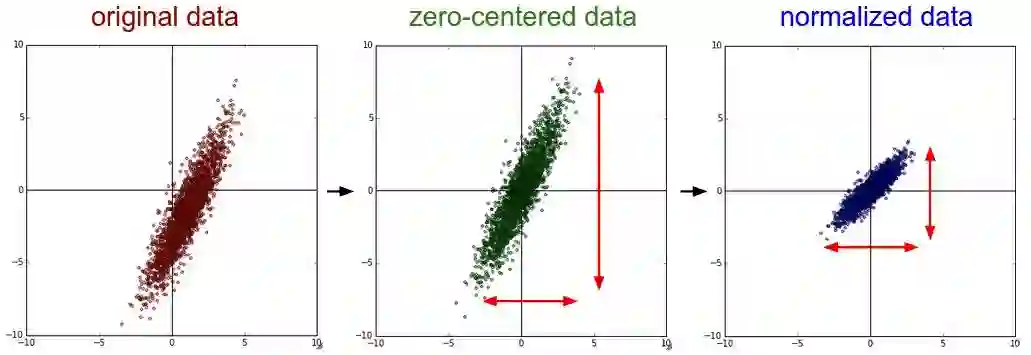
3种常见的数据处理方式
去均值:把输入数据各个维度都中心化到0。
归一化:幅度归一化到同样的范围。
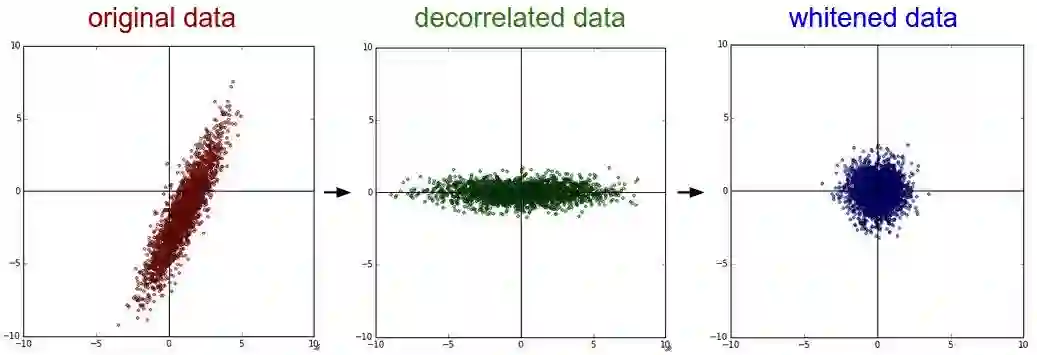
PCA/白化:用PCA降维;白化是对数据每个特征轴上的幅度归一化。
去均值与归一化:
去相关与白化:
(2)卷积计算层/ CONV layer
局部关联,每个神经元看做一个filter。
窗口(receptive field)滑动,filter对局部数据计算。
涉及概念:深度/depth、步长/stride、填充值/zero-padding。
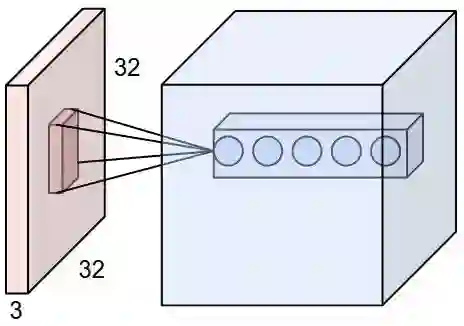

参数共享机制:
假设每个神经元连接数据窗的权重是固定的 。
固定每个神经元连接权重,可以看做模板。
每个神经元只关注一个特性。
需要估算的权重个数减少: 一层1亿=> 3.5w。
一组固定的权重和不同窗口内数据做内积: 卷积。
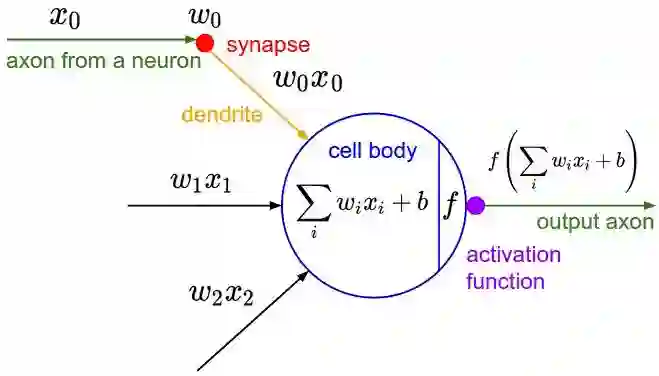
(3)激励层/ Activation layer
把卷积层输出结果做非线性映射
把卷积层输出结果做非线性映射:Sigmoid、Tanh(双曲正切)、ReLU、 Leaky ReLU、 ELU、Maxout等等。
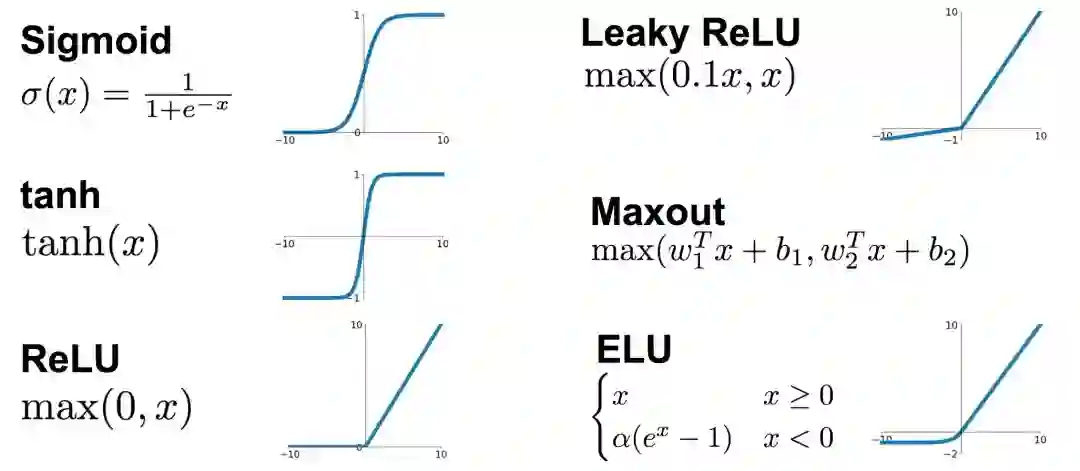
激励层要注意以下4点
CNN慎用sigmoid!慎用sigmoid!慎用sigmoid!
首先试RELU,因为快,但要小心点。
如果2失效,请用Leaky ReLU或者Maxout。
某些情况下tanh倒是有不错的结果,但是很少。
(4)池化层/ Pooling layer
夹在连续的卷积层中间。
压缩数据和参数的量,减小过拟合。
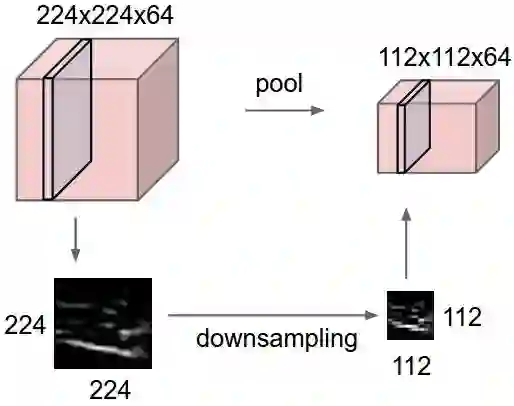
Max pooling
average pooling
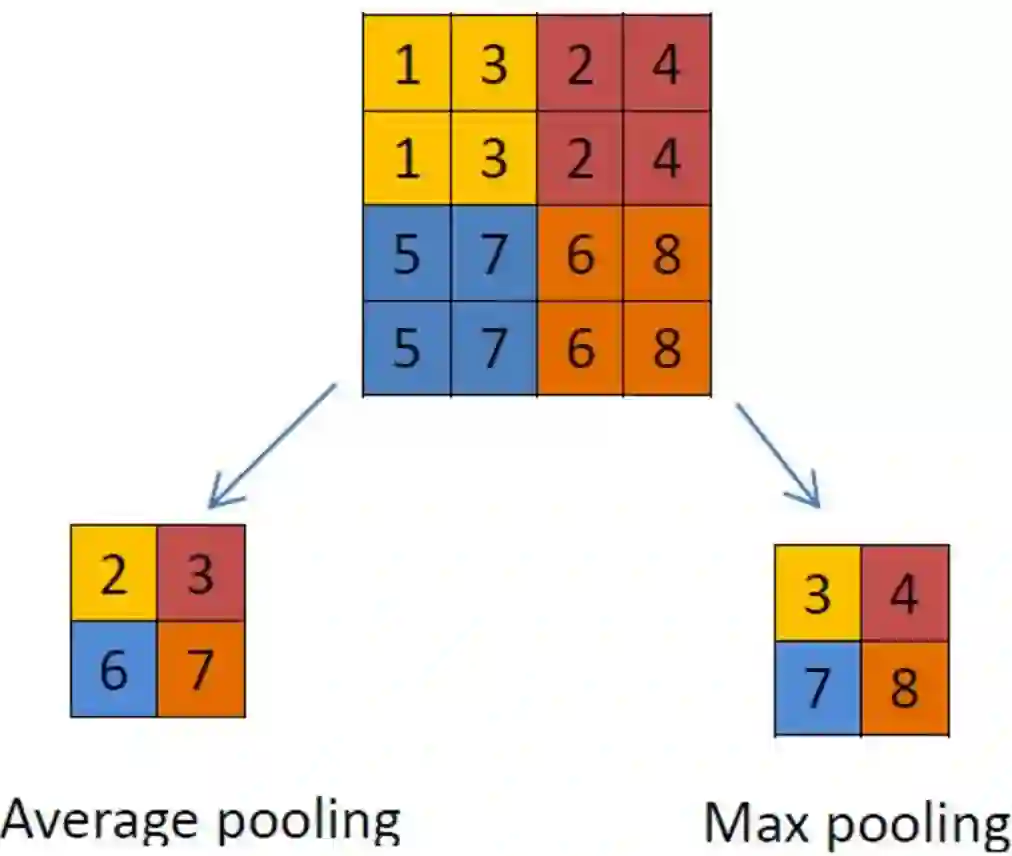
(5)全连接层/ FC layer
两层之间所有神经元都有权重连接
通常全连接层在卷积神经网络尾部
典型的CNN结构为:
INPUT
[[CONV -> RELU]*N -> POOL?]*M
[FC -> RELU]*K
FC
2、卷积层可视化理解:


CONV Layer 1:

CONV Layer 2:


3、训练算法
同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距。
找到最小化损失函数的W和b,CNN中用的算法是SGD;SGD需要计算W和b的偏导。
BP算法就是计算偏导用的;BP算法的核心是求导链式法则。
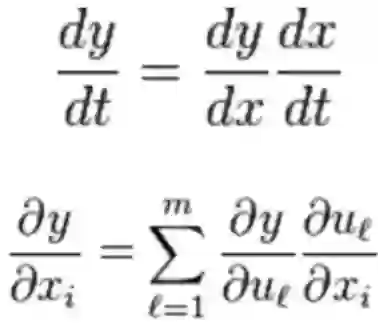
BP算法利用链式求导法则,逐级相乘直到求解出dW和db。
利用SGD/随机梯度下降,迭代和更新W和b。
4、优缺点
优点:
共享卷积核,优化计算量。
无需手动选取特征,训练好权重,即得特征。
深层次的网络抽取图像信息丰富,表达效果好。
缺点:
需要调参,需要大样本量,GPU等硬件依赖。
物理含义不明确。
正则化与Dropout
神经网络学习能力强可能会过拟合。
Dropout(随机失活)正则化:别一次开启所有学习单元
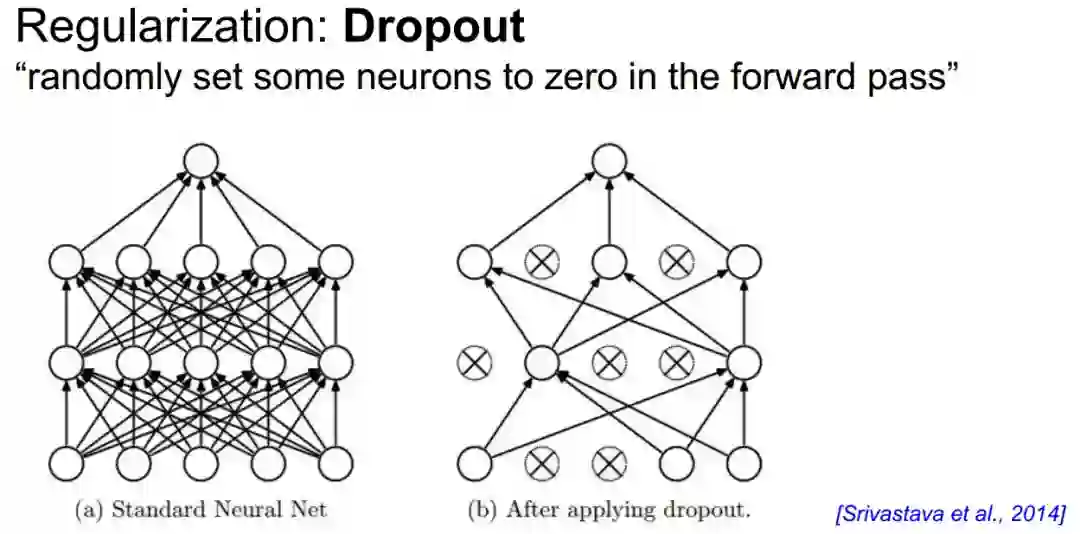
1、正则化与Dropout处理

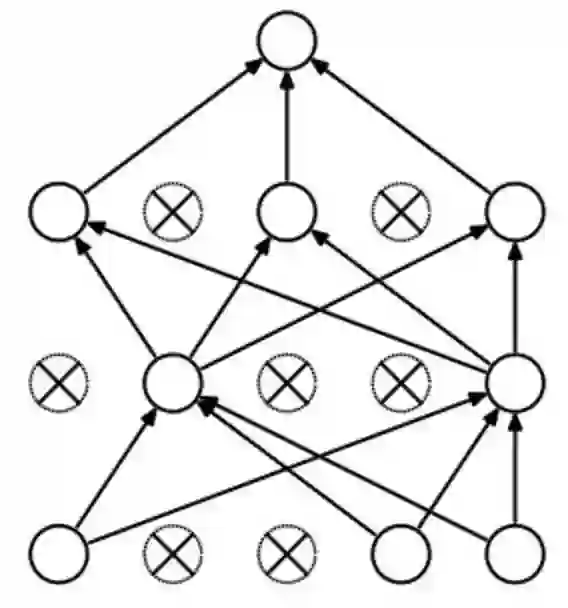
实际实现:把预测阶段的时间转移到训练上

2、Dropout理解
防止过拟合的第1种理解方式:
别让你的神经网络记住那么多东西(虽然CNN记忆力好)
学习的过程中,保持泛化能力
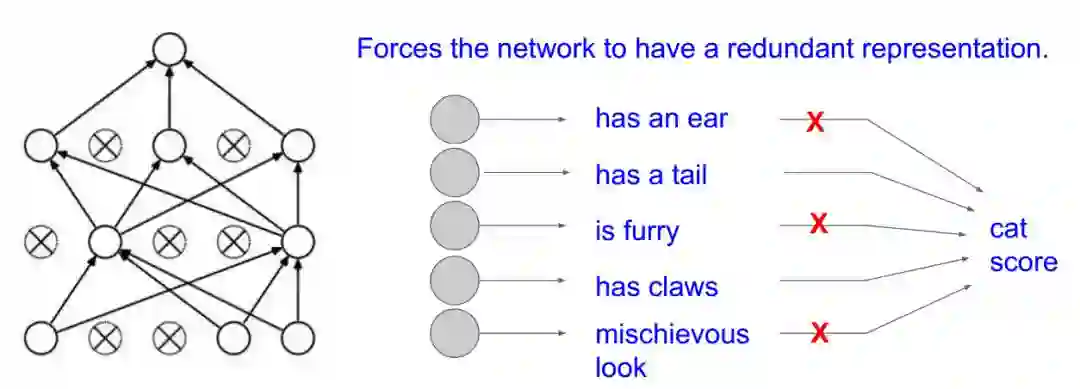
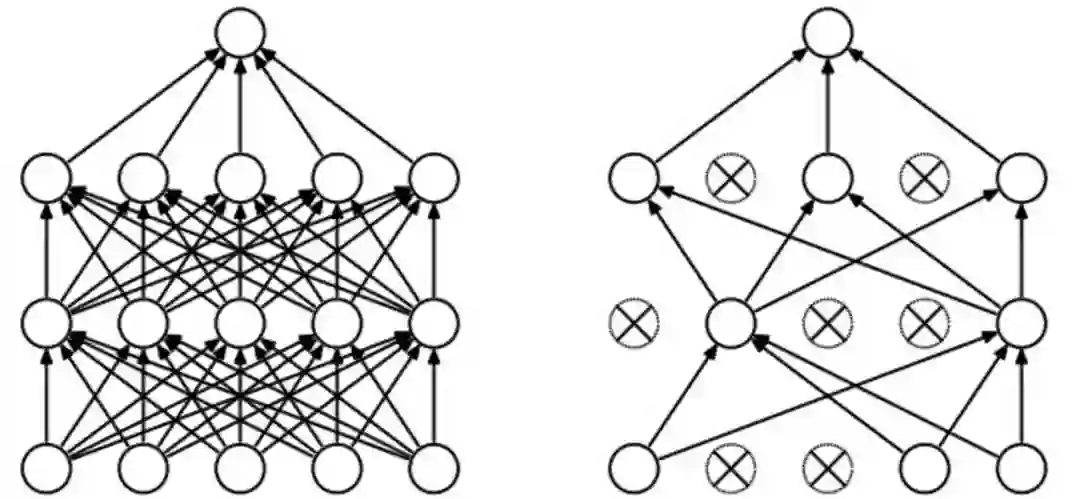
防止过拟合的第2种理解方式:
每次都关掉一部分感知器,得到一个新模型,最后做融合。
不至于听一家所言。
典型CNN
LeNet:这是最早用于数字识别的CNN。
AlexNet:2012ILSVRC比赛远超第2名的CNN,比LeNet更深,用多层小卷积层叠加替换单大卷积层。
ZF Net:2013ILSVRC比赛冠军。
GoogLeNet:2014ILSVRC比赛冠军。
VGGNet:2014ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如objectdetection)上效果很好。
ResNet:2015ILSVRC比赛冠军,结构修正(残差学习)以适应深层次CNN训练。
DenseNet:CVPR2017best paper,把ResNet的add变成concat。
因篇幅有限,大家如果想看典型CNN的更多介绍,可以在公众号回复“CNN”,获取课件。


大量学员拿到30-40万年薪
多位名校博士+BAT专家手把手教学
现在报名
送18VIP会员
[包2018全年在线课程和全年GPU]
前100人可享特惠价
↓立刻扫码查看详情↓