【学界】IEEE IV 2018:如何构建出逼真的下雨天场景,来验证物体识别的鲁棒性?德国图宾根大学做到了
来源:智车科技
由IEEE智能交通系统协会 (ITSS)主办的 The 29th IEEE Intelligent Vehicles Symposium(第29届IEEE IV 国际智能车大会)将于6月26日-6月30日在江苏常熟举办。本届IEEE IV大会共收到来自34个国家的603篇论文,本篇论文为大会优秀论文之一,数据详实观点新颖。
摘要:自动驾驶领域最近的发展表明,这些车辆在不久的将来会出现在每个城市的街道上,而这些城市不会容忍交通事故的发生。为了保证安全需求,自动驾驶汽车和被使用的软件必须在尽可能多的条件下进行详尽的测试。通常被考虑的影响因素越多,测试越全面,一般情况下,汽车就越安全。然而,在每次产生或希望产生特定的场景之前,都要反复地记录相同的测试集,这是一种非常耗费时间和资源的过程,特别是在使用真实车辆测试的时候。这就需要用环境模拟进行仿真测试。
本课题通过对环境的仿真模拟,研究了影响自动驾驶车辆传感器的环境因素。主要模拟了下雨环境中,挡风玻璃上的雨滴是如何影响摄像头成像的。我们提出了一种新的方法,利用基于R-树连续最近邻查询算法来渲染雨滴。摄像头前的3D场景由立体图像生成,这些水滴被设置了真实的物理特性。所构建的模拟环境真实,派生的图像可以用来扩展用于机器学习的训练数据集,而不必强制获取新的真实图像。
这篇论文的第一作者为 Alexander von Bernuth, 来自德国图宾根大学Wilhelm Schickard计算机科学研究所计算机工程系主任。

Rendering Physically Correct Raindrops on Windshields for Robustness Verification of Camera-based Object Recognition
Alexander von Bernuth, Georg Volk and Oliver Bringmann University of Tubingen, ¨ {bernuth, volkg, bringmann}@informatik.uni-tuebingen.de
恶劣天气状况仿真模拟测试的必要性
自动驾驶汽车将使世界各地的研究人员和制造商在很长一段时间内都处于忙碌的状态。这是因为自动驾驶汽车在未来可能会成为公共交通的主导,而且必须经过彻底的安全验证。如果像车辆或行人检测这样的关键系统没有进行最全面的测试,这个检测覆盖所有能想到的环境影响,以及所有可能的组合,难以想象会发生什么。比如在阴天的阳光下,有背光和脏镜头的情况。
在测试过程中希望随机遇到或者刻意设计所有这些边缘场景的组合,看起来都非常愚蠢的。根据分析师的观点,一辆载有所有待测试技术的汽车必须以109公里的速度驾驶没有出错,才有资格获得ISO 26262 [1]标准。此外,车辆的任何部分接收到更新时,都需要重新运行所有测试。
因此,许多制造商面临的主要挑战之一是时间密集型测试,特别是在原型车中调度大量的测试驱动程序。一种可能的解决方案是依靠一个相对较短的驱动器,并通过模拟不同的环境影响因素通过随机组合来生成多个版本。虽然目前已经有人对这些环境影响因素进行了一些模拟研究,但尚未探索的天气条件和影响仍然很多。
我们自己的调查得出的结论是,下雨时,如果不是暴雨,不会影响目标或交通标志检测算法。因此,本文研究了在相机或相机镜头前挡风玻璃上放置被渲染的雨滴以及这些雨滴对物体识别算法的影响。 本文的第一部分将综述了其他学者的研究,重点研究在摄像机前和摄像机上模拟雨和尘埃等影响。第二部分关注的是水滴的产生,从场景重建开始,到我们的射线追踪法结束。之后,第三部分将介绍结果和应用。在第四部分中,我们讨论调查结果并提出可以改善方法和未来工作。
下雨场景天气模拟研究现状
大多数与天气和环境相关的模拟研究都集中在游戏中的直接使用或合成场景的渲染,只有很少的研究考虑到环境的物理特性。到目前为止,所有的论文作品都没有研究雨滴在镜头前的影响,但在某些情况下,他们对水滴的描述非常准确。Starik 和 Werman 的工作使用了3D场景,该场景假设在任何地方都具有相同深度[2]。他们从视频中提取雨的特征,并将学习过的蒙版应用到没有下雨的图像上。然而他们忽略了单个雨滴的物理特性,如果从视差图中提取场景的深度,考虑更确切的情况可能会有更好的结果[3],[4]。实现上述这些是可行的,因为作者在视频采集时使用的是立体相机,他们用摄像头和物体把空间分隔成小部分,通过计算这些部分的正确雨量并在OpenGL中渲染雨滴。
Hospach和Muller研究把雨滴抽象成非常薄的三角形,它们呈现出多彩的白色,并且他们混合比例基于降雨强度。这个技巧需要快速显卡来支持渲染。他们忽略了折射等效果,因为差异很小。
Wang等人使用光线追踪来渲染雨滴,这种方法依赖于光源精确位置信息[5]。作者将来自不同光源的光线射向所有雨滴,并根据 Phong 照明模型计算像素颜色。不发光的物体被筛掉,而且不会在雨滴中发生折射。
与本文相比,最相似的论文是T. Sato的论文,但是他们为了满足实时约束做了许多简化的假设[6]。作者将视频图像映射到摄像头的前面单个半球,而不管物体与摄像头的真实距离如何。然后,他们向雨滴占领的每个像素投射光线,并检查这些光线与半球接触形成的图像。相应的像素值将在渲染雨滴时用作纹理元素。
许多研究雨滴在挡风玻璃上的研究人员关注的是它们的定位、合并和移动。不同的工作大都集中在模拟流体动力学[7]-[11]。 Extrand等人研究放置在倾斜表面上的水滴的形状,如玻璃板[12]。 Garg和Nayar [13]做了更多有关下落过程水形状的研究。此外,还有人在竭尽全力描述水滴的物理和光学特性[14]。不同的研究人员采用了完全不同的方法,有人通过检测并去除图像中的雨滴,而不是创建这些雨滴[15],[16]。由于所描述的方法利用了一些有趣的物理性质,因此可以从移除雨滴的方法中学到很多东西。
之前发表的论文都局限于单一的雨滴,静止和下降,忽略了相机的环境是三维场景。要么他们完全忽略了深度,要么作出广泛的假设,也忽略了水滴中场景物体的正确折射。我们的方法将所有这些考虑在内。仿真结果接近于真实照片,这对于训练神经网络的数据集来说是非常必要的。
点云渲染的方法
关于点云的渲染,现有许多不同的方法。一种是创建一个表示曲面的网格,并将图像作为纹理映射到它们上[17]。 其他人也使用大量的预处理来创建多个深度图并逐步细化渲染[18]。但即使网格划分简单且便宜,我们也不得不填补出现在树木或汽车等物体后面的间隙。如果不是固定的,这些缝隙可能会导致黑点,因为它们可能会将光线折射到通常看不见的区域。
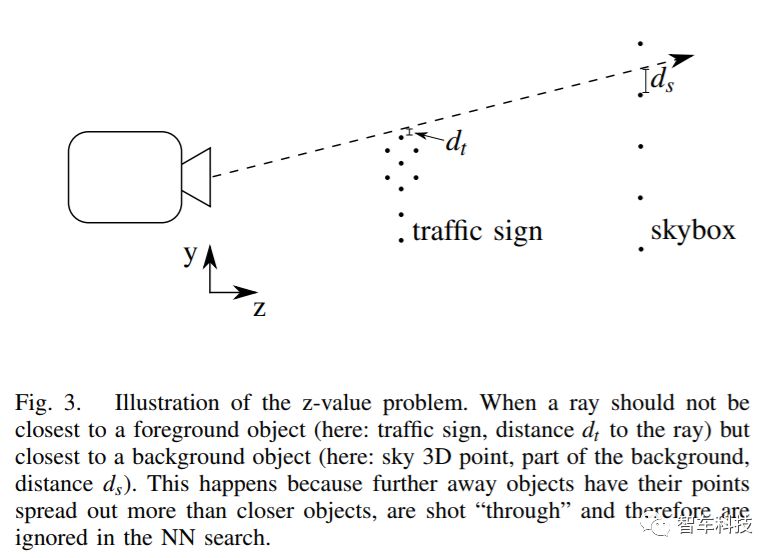
Schaufler和Jensen将光线射入点云并搜索超过某个阈值的点密度[19]。在一个范围内的所有点都被用于表面法线和位置的插值。这样就避免了昂贵的3D重建。不幸的是,如果没有足够的点或没有足够密集地采样,表面上可能会出现孔。这些孔将表现为黑色区域,并且尤其出现在具有非常不同深度的物体的边缘附近,例如在天空的前方看到一个交通标志。 Adnoni等人提出了另一种寻找线段最近邻的方法 [20]。它们在高维搜索时使用近似值。
Adnoni等人提出了另一种寻找线段最近邻的方法 [20],它们在高维搜索时使用近似值。这不一定适用于我们的用例,并且涉及复杂的数据结构,这对我们做三维来说太难了。
上面提到的所有论文都没有将雨滴的真实渲染环境和有限场景中找到相应的对象并用最先进的目标检测算法结合起来。本文将完成以上所有内容,并额外展示了训练渲染图片的神经网络模型,这可能会给现代物体识别带来帮助。
基于最近邻查询算法的雨滴下落仿真
为了描述出物体折射和雨滴渲染相结合的场景,必须将其作为点云以3D形式再现。这个过程需要了解场景的深度。可以使用对极几何(对应于深度的视差图)或利用LiDAR或其他传感器来计算每个像素与相机距离的深度图。场景计算完成后,必须对挡风玻璃上的雨滴进行建模。我们用一个简单而强大的抽象模型:每一滴水都被挡风玻璃切断的球体所代表。

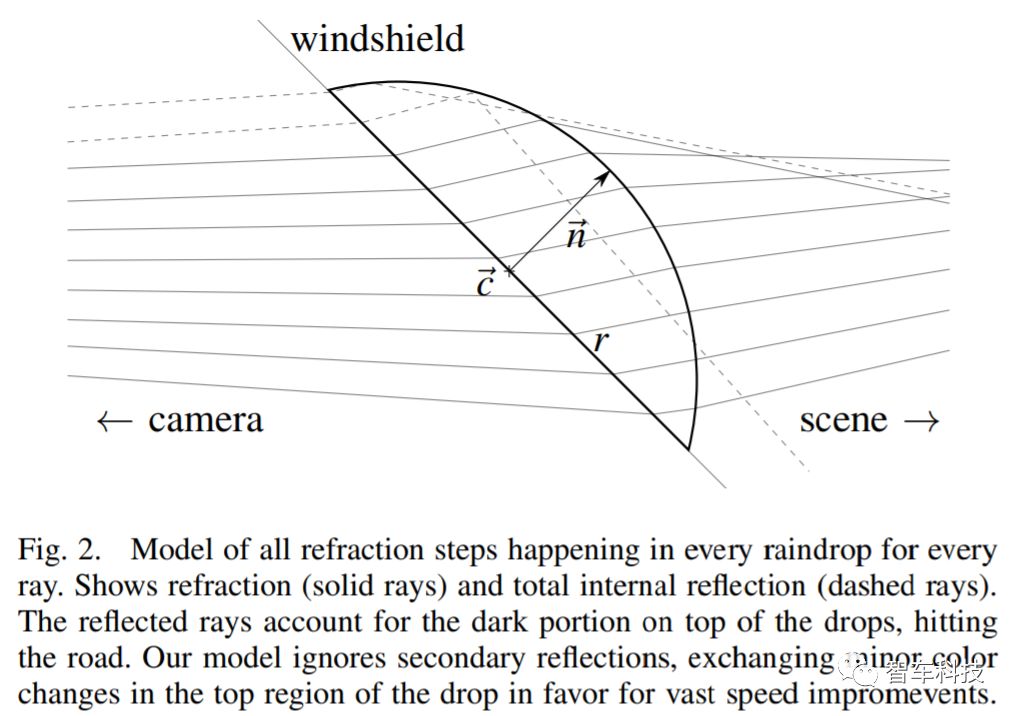
这就看起像一个球形帽,起码在几何上很容易处理。然后,光线会投射到由投影面积的每个图像像素上,并在这些像素中发生折射。产生的射线被发送到场景中,并搜索点云中最近的位置。这一点的颜色决定了降落的像素颜色。搜索两百万个点中的其中一个点的最近邻点可能是微不足道而且是快速的,用同样的方法搜索空间中的一条线就显得非常费劲。只有使用连续最近邻搜索才能使此方法可行。
1.场景重建
第一步是摄像机前场景的三维重建。在处理来自(校准过的)立体相机的图像时,可以使用立体重建计算相机到每个像素的距离[21]。其他方法也可以用额外的传感器,如LiDAR来捕捉深度。我们用的数据集是Cityscapes[22]中的图像。它由数千张包含各种街景的图片组成,使用立体相机拍摄,并带有预先计算的视差图。这些可以很容易地转换成深度图。 VIRES虚拟测试驱动软件[23]是我们使用的具有相应深度图像的另一个来源。深度图非常精确,因为它们基于地面实况数据。此外,可以使用汽车(用户或计算机控制的),行人和其他障碍物快速构建自定义场景。我们用于物体检测的图像来源是KITTI数据集[24]。深度图使用Hirschmuller匹配算法 [25] 的OpenCV来计算。
结合深度和颜色信息,我们可以定位摄像头的三维位置。通过公式可以求得所有像素组成的3D点云,如图1所示。这些点云呈现了在渲染雨滴场景中物体的图像。
2.下落模型
一旦完成3D表示,就有必要在虚拟挡风玻璃上创建和分配雨滴。 单个雨滴被模拟为球帽状。这个帽子的特点是它的中心c,半径r,高度和法线n(从基座指向圆顶)。生成雨滴意味着设置固定的z值(从相机到挡风玻璃的距离),随机或故意设置每个雨滴的x和y坐标,高度和半径。当高度和半径相关时,一个值就能通过另一个值求得[26]。 我们选择h = tan(θ/ 2)·d,其中h表示液滴高度,θ表示液滴的接触角,d表示液滴直径。 Park等人在观察半径为2mm的液滴时,接触角θ被确定为大约87° [27]。 相应的法线简单地指向与相机视角矢量相同的方向。当向前倾斜挡风玻璃时,所有下降中心和法线也围绕x轴旋转。
3.折射
在折射场景形成之前,我们将从相机发出的光线照射到图像平面中的每个像素。为了减少计算工作量,只有光线落在圆点的后面(具有中心,半径和法线的圆)才被跟踪。所有其他光线都被丢弃,并且来自原始图像的像素值被用于最终的图像。在雨滴下落的过程中,我们折射的射线遵循斯奈尔定律。有关折射的更多信息,请参阅已建立的文献[28]。折射的光线落在雨滴内, 然后,通过生成垂直于法线的随机矢量并且只要下降半径来计算球体的中心。加上正常缩放到半径长度,我们现在有四个点位于球体上,足以计算球体的中心[29]。在全内反射的情况下,所得到的光线不会被进一步折射。每种折射的视觉表示可以在图2中找到。
4.最近邻查询算法
接下来,我们将计算光线中最近邻的像素来推迟光线等效像素的颜色。此点的颜色分配给相应的像素,并在展示位置中可见。找到神经网络的一个非常简单的方法是查看每条射线的每个点,计算从该点到射线的距离并取最近的点。即使在允许快速最近邻(NN)查询的R树中组织点后,也可以对光进行采样,并搜索每个样本的NN。最后,我们选择了连续最近邻搜索[31],因为它不仅提供了一个精确的最近邻点,而且在包含超过两百万个点的大型点云中,很短时间内(仅仅是毫秒)就能完成搜索。
在数据集里评估该算法的质量
为了评估我们的光线跟踪算法的质量,我们用完全渲染场景,忽略雨滴和拍摄光线通过每个像素进行对比。这允许进行详细的错误检测。在图4中可以由相减图像和取绝对值的差分图像。像素越亮,两个图像之间的差异越高。显然,不同深度的物体的边缘显示出不同的差异。这是因为前面提到的Z值问题,但远好于完全没有修正情况下的识别。


作为雨滴渲染的例子,我们从Cityscapes数据集中获取一幅图像,随机生成雨滴并渲染了这些图像。结果可以在图5中找到。
为了测试物体识别算法的能力,我们将其应用于KITTI数据集中排名最高的神经网络模型算法中。可以预料到的是,大雨滴可能会遮挡像行人的小物体或行驶车辆的部分外观,可能会让在完美图像上训练过的神经网络产生混淆。
我们使用的网络是一个单阶段对象检测网络[31]的循环滚动卷积(RRC)网络。它目前在KITTI数据集中排名第四。利用相应的立体图像重建了450个KITTI数据集的模拟雨滴场景。这些图像用作RRC网络的输入。使用没有雨滴的相同图像做为对比。这个过程的概述可以在图6中找到。
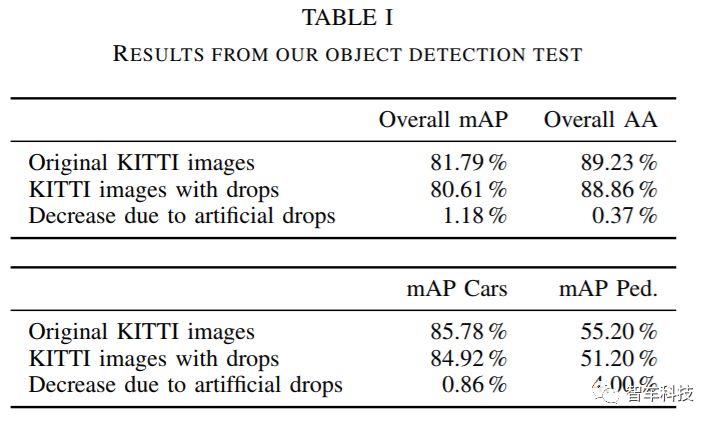
通过计算中[35]常用的测量平均精度(mAP)来评估结果。表I中的结果表明,当图像中存在雨滴时,总体平均精度下降了1.18%,整体平均精度下降了0.37%。 此外,我们发现像行人这样的小物体更容易被雨滴遮挡(mAP减少4%),而不像汽车这样的大物体。在顶部神经网络的识别率相差百分之零点几的时候,即使是很小的改进,也会给予其他人很多帮助。

该研究的结果与应用
这项研究提出了仅基于一对立体图像的人为创建雨滴方法。物理上正确的折射和反射包含在我们的模型中,以及一些允许更快开发的简化。然而,结果是显著的。我们在一个倾斜的挡风玻璃上实现了照片真实的雨滴下落,并呈现了他们折射出的所有物体。尽管雨滴用球帽状做了简化,但我们的水滴看起来很逼真。
我们的光线跟踪方法产生了一个3D场景的近乎完美的渲染,没有昂贵的网格和纹理的预计算。甚至像交通标志这样的小物体也不会在整个场景中丢失;车牌中的字母也是可读的。这是可能的,而3D场景重建依赖于特征匹配和具有离散值的视差图。神经网络处理的对象检测,另外训练与雨滴准备的图像可以获得更好的结果,并超越其他竞争对手。这项工作可以导致更好的整体得分和鲁棒性的传感器缺陷,这些机器学习算法。
处理目标检测的神经网络还额外使用雨滴制作的图像进行训练,取得良好的效果。这项工作可以为这些机器学习算法提供更好的总体分数和鲁棒性。 到目前为止,我们的连续NN搜索运行在最多8个CPU内核上(这是我们的CPU,Intel i7-7700K提供的最高线程数)。在那里,每个KITTI图像的运行时间大约3分钟。雨滴越小越少,计算速度越快。
该算法的一个有趣的应用可能是使用它生成图像,作为Iseringhausen等人工作的输入[37]。他们在场景前面的玻璃板上使用水滴作为光场照相机,这些水滴在不同位置上用作多个镜头。通过逆向工程设计投影形状,他们可以推断出背后的场景,并能从不同的角度创建3D渲染图,这正好与我们的工作相反。
REFERENCES
[1] A. Weitzel, H. Winner, C. Peng, S. Geyer, F. Lotz, and M. Sefati, Absicherungsstrategien fuer Fahrerassistenzsysteme mit Umfeldwahrnehmung. Fachverlag NW in der Carl Schuenemann Verlag GmbH, 2014. [Online]. Available: https://trid.trb.org/view/ 1339882
[2] S. Starik and M. Werman, “Simulation of rain in videos,” Texture Workshop, International Conference on Computer Vision, 2003 (ICCV), vol. 2, pp. 406–409, 2003. [Online]. Available: http://www.cs.huji.ac.il/∼werman/Papers/Rain.pdf
[3] D. Hospach, S. Mueller, O. Bringmann, J. Gerlach, and W. Rosenstiel, “Simulation and evaluation of sensor characteristics in vision based advanced driver assistance systems,” 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), pp. 2610– 2615, 2014. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/ epic03/wrapper.htm?arnumber=6958108
[4] D. Hospach, S. Mueller, W. Rosenstiel, and O. Bringmann, “Simulation of Falling Rain for Robustness Testing of Video-Based Surround Sensing Systems,” Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 233–236, 2016.
[5] C. Wang, M. Yang, X. Liu, and G. Yang, “Realistic Simulation for Rainy Scene,” Journal of Software, vol. 10, no. 1, pp. 106–115, 2015.
[6] T. Sato, Y. Dobashi, and T. Yamamoto, “A Method for Real-Time Rendering of Water Droplets Taking Into Account Interactive Depth of Field Effects,” in Iwec 2002, 2002, pp. 110–117.
[7] H. Wang, P. J. Mucha, and G. Turk, “Water drops on surfaces,” ACM Transactions on Graphics, vol. 24, no. 3, p. 921, 2005. [Online]. Available: http://portal.acm.org/citation.cfm?doid=1073204.1073284
[8] K. Kaneda, Y. Zuyama, H. Yamashita, and T. Nishita, “Animation of Water Droplet Flow on Curved Surfaces,” PACIFIC GRAPHICS, pp. 50–65, 1996. [9] K. Kaneda, S. Ikeda, and H. Yamashita, “Animation of water droplets moving down a surface,” The Journal of Visualization and Computer Animation, vol. 10, no. 1, pp. 15–26, 1999.
[10] S. Takenaka, Y. Mizukami, and K. Tadamura, “A Fast Rendering Method for Water Droplets on Glass Surfaces,” The 23rd International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), vol. 23, pp. 13–16, 2008.
[11] M. Jonsson and A. Hast, “Animation of Water Droplet Flow on Structured Surfaces,” Special Effects and Rendering. Proceedings from SIGRAD 2002, pp. 17–22, 2002.
[12] C. W. Extrand and Y. Kumagai, “Liquid Drops on an Inclined Plane: The Relation between Contact Angles, Drop Shape, and Retentive Force,” Journal of Colloid and Interface Science, vol. 170, no. 2, pp. 515–521, 1995. [Online]. Available:
http: //www.sciencedirect.com/science/article/pii/S0021979785711307
[13] K. Garg and S. K. Nayar, “Vision and rain,” International Journal of Computer Vision, vol. 75, no. 1, pp. 3–27, 2007.
[14] ——, “Photometric Model for Raindrops,” Columbia University Technical Report, 2003.
[15] S. You, R. T. Tan, R. Kawakami, Y. Mukaigawa, and K. Ikeuchi, “Raindrop detection and removal from long range trajectories,” Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 9004, pp. 569–585, 2015.
[16] J. C. Halimeh and M. Roser, “Raindrop detection on car windshields using geometric-photometric environment construction and intensitybased correlation,” IEEE Intelligent Vehicles Symposium, Proceedings, pp. 610–615, 2009.
[17] M. Bolitho, M. Kazhdan, R. Burns, and H. Hoppe, “Multilevel streaming for out-of-core surface reconstruction,” Proceedings of the fifth Eurographics symposium on Geometry processing, pp. 69–78, 2007. [Online]. Available: http://portal.acm.org/citation.cfm? id=1282001
[18] M. Arikan, R. Preiner, and M. Wimmer, “Multi-depth-map raytracing for efficient large-scene reconstruction,” IEEE Transactions on Visualization and Computer Graphics, vol. 22, no. 2, pp. 1127–1137, 2016.
[19] G. Schaufler and H. Jensen, “Ray tracing point sampled geometry,” In Rendering Techniques 2000: 11th Eurographics Workshop on Rendering, pp. 319—-328, 2000. [Online]. Available: https://www.cs.princeton.edu/courses/archive/spring01/cs598b/ papers/schaufler00a.pdf
[20] A. Andoni, P. Indyk, R. Krauthgamer, and H. L. Nguyen, “Approximate line nearest neighbor in high dimensions,” Symposium on Discrete Algorithms, pp. 293–301, 2009. [Online]. Available: http://portal.acm.org/citation.cfm?id=1496770.1496803
[21] M. Sonka, V. Hlavac, and R. Boyle, Image Processing, Analysis, and Machine Vision, 2nd ed. Pacific Grove: Cengage Learning, 1998.
[22] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The Cityscapes Dataset for Semantic Urban Scene Understanding,” Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. [Online]. Available: http://arxiv.org/abs/1604.01685
[23] M. Dupuis and W. Karl, “VTD - VIRES Virtual Test Drive,” 2017. [Online]. Available: https://vires.com/vtd-vires-virtual-test-drive/
[24] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,” International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, 2013.
[25] H. Hirschmuller, “Stereo Processing by Semiglobal Matching and Mutual Information,” Ieee Transactions on Pattern Analysis and Machine Intelligence, vol. 30, no. 2, pp. 328–341, 2008.
[26] G. Bracco and B. Holst, Surface science techniques. Springer-Verlag Berlin Heidelberg, 2013, vol. 51, no. 1.
[27] J. Park, H. S. Han, Y. C. Kim, J. P. Ahn, M. R. Ok, K. E. Lee, J. W. Lee, P. R. Cha, H. K. Seok, and H. Jeon, “Direct and accurate measurement of size dependent wetting behaviors for sessile water droplets,” Scientific Reports, vol. 5, no. June, pp. 1–13, 2015. [Online]. Available: http://dx.doi.org/10.1038/srep18150
[28] P. Shirley, Fundamentals of computer graphics. Natick (Mass.): Peters, 2002.
[29] W. H. Beyer, CRC handbook of mathematical sciences. CRC press, 1987.
[30] D. H. Eberly, 3D game engine design: a practical approach to realtime computer graphics. CRC Press, 2006.
[31] Y. Tao, D. Papadias, and Q. Shen, “Continuous Nearest Neighbor Search,” VLDB ’02 Proceedings of the 28th international conference on Very Large Data Bases, pp. 287–298, 2002.
[32] N. Roussopoulos, S. Kelley, and F. Vincent, “Nearest neighbor queries,” Proceedings of the 1995 ACM SIGMOD International Conference on Management of Data - SIGMOD ’95, pp. 71–79, 1995. [Online]. Available: http://portal.acm.org/citation.cfm?doid= 223784.223794
[33] H. G. Dietz, “Out-of-focus point spread functions,” Proceedings of SPIE, vol. 9023, pp. 1–11, 2014. [Online]. Available: http: //dx.doi.org/10.1117/12.2040490
[34] J. S. J. Ren, X. Chen, J. Liu, W. Sun, J. Pang, Q. Yan, Y.-W. Tai, and L. Xu, “Accurate Single Stage Detector Using Recurrent Rolling Convolution,” CoRR, vol. abs/1704.0, 2017. [Online]. Available: http://arxiv.org/abs/1704.05776
[35] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The Pascal Visual Object Classes (VOC) Challenge,” International Journal of Computer Vision, vol. 88, no. 2, pp. 303–338, jun 2010. [Online]. Available: https://doi.org/10.1007/ s11263-009-0275-4
[36] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the KITTI vision benchmark suite,” Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 3354–3361, 2012.
[37] J. Iseringhausen, M. B. Hullin, B. Goldlucke, N. Pesheva, S. Iliev, ¨ A.-d. Wender, and M. Fuchs, “4D Imaging through Spray-On Optics,” ACM Trans. Graph. Article, vol. 36, no. 35, 2017. [Online]. Available: http://dx.doi.org/10.1145/3072959.3073589

2018.6.26-6.30
IEEE IV 2018
由IEEE智能交通系统协会(ITSS)主办的第29届国际智能车大会( IEEE IV 2018)将于2018年6月26日-30日在中国常熟举办。IEEE Intelligent Vehicle Symposium(IEEE 国际智能车大会)是 IEEE 智能交通协会举办的两大年度旗舰会议之一,旨在为全球该领域相关的研究人员、工程师、学者提供当今最先进技术的交流研讨机会。
国际学术顶级会议,阔别十年,再度登陆中国
现报名正式启动
现面向全球招募赞助商和媒体
关于大会更多信息,请关注智车科技微信公众号或访问活动行页面:
http://www.huodongxing.com/event/4434937824300
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【深度】从DensNet到CliqueNet,解读北大在卷积架构上的探索
☞【深度】Ian Goodfellow等提出自注意力GAN,ImageNet图像合成获最优结果!




