强化学习在生成对抗网络文本生成中扮演的角色(Role of RL in Text Generation by GAN)(上)

本文作者华南理工大学胡杨,本文首发于知乎专栏 GAN + 文本生成 + 读博干货。AI研习社已获得作者授权。
既然已经身在工业届,那么我就谈谈工业界未来几年需要什么样的机器学习人才。不谈学术界主要还是因为大部分人最终不会从事研究,而会奋斗在应用领域。相较而言,工业界对人才的需求更加保守,这和学术界不同。这受限于很多客观因素,如硬件运算能力、数据安全、算法稳定性、人力成本开支等。
1. 基础:文本生成模型的标准框架
文本生成(Text Generation)通过 机器学习 + 自然语言处理 技术尝试使 AI 具有人类水平的语言表达能力,从一定程度上能够反应现今自然语言处理的发展水平。
下面用极简的描述介绍一下文本生成技术的大体框架,具体可以参阅各种网络文献(比如:CSDN 经典 Blog“好玩的文本生成”[1]),论文等。
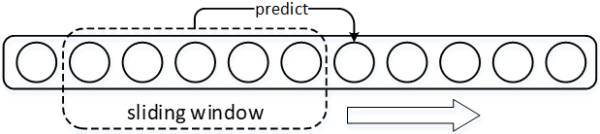
文本生成按任务来说,比较流行的有:机器翻译、句子生成、对话生成等,本文着重讨论后面两种。基于深度学习的 Text Generator 通常使用循环神经网络(Basic RNN,LSTM,GRU 等)进行语义建模。在句子生成任务中,一种常见的应用:“Char-RNN”(这里 “Char” 是广义上的称谓,可以泛指一个字符、单词或其他文本粒度单位),虽然简单基础但可以清晰反应句子生成的运行流程,首先需要建立一个词库 Vocab 包含可能出现的所有字符或是词汇,每次模型将预测得到句子中下一个将出现的词汇,要知道 softmax 输出的只是一个概率分布,其维度为词库 Vocab 的 size,需再通过函数将输出概率分布转化为 One-hot vector,从词库 Vocab 中检索得出对应的词项;在 “Char-RNN” 模型训练时,使用窗口在语料上滑动,窗口之内的上下文及其后紧跟的字符配合分别为一组训练样本和标签,每次以按照固定的步长滑动窗口以得出全部 “样本 - 标签” 对。
与句子生成任务类似,对话生成以每组 Dialogue 作为 “样本 - 标签” 对,循环神经网络 RNN_1 对 Dialogue 上文进行编码,再用另一个循环神经网络 RNN_2 对其进行逐词解码,并以上一个解码神经元的输出作为下一个解码神经元的输入,生成 Dialogue 下文,需要注意的是:在解码前需配置 “开始” 标记 _,用于指示解码器 Decoder 开启 Dialogue 下文首词(or 字)的生成,并配置 “结束” 标记 _,用于指示解码器结束当前的 Text Generation 进程。
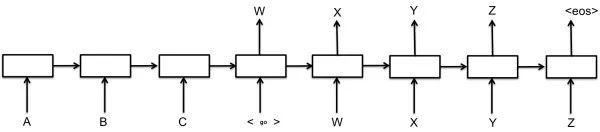
这便是众所周知的 “Seq2Seq” 框架的基础形态,为了提高基础 Seq2Seq 模型的效果,直接从解码器的角度有诸如 Beam-Search Decoder[2]、Attention mechanism Decoder[3](配置注意力机制的解码器)等改进,而从神经网络的结构入手,也有诸如 Pyramidal RNN[4](金字塔型 RNN)、Hierarchical RNN Encoder[5](分层循环网络编码器)等改进。改进不计其数,不一一详举,但不管如何,预测结果的输出始终都是一个维度为词库大小的概率分布,需要再甄选出最大值的 Index,到词库 Vocab 中检索得出对应的单词(or 字符)。
2. 问题:GAN 为何不能直接用于文本生成
2.1. GAN 基础知识
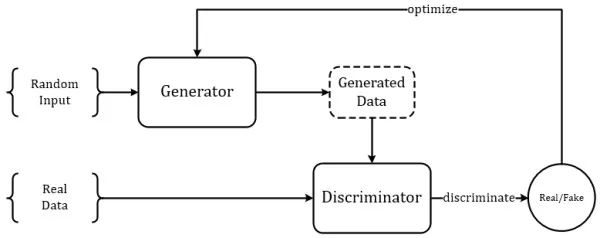
GAN 对于大家而言想必已经脍炙人口了,这里做一些简单的复习。GAN 从结构上来讲巧妙而简单(尽管有与其他经典工作 Idea 相似的争议 [6~7]),也非常易于理解,整个模型只有两个部件:1. 生成器 G;2. 判别器 D。生成模型其实由来已久,所以生成器也并不新鲜,生成器 G 的目标是生成出最接近于真实样本的假样本分布,在以前没有判别器 D 的时候,生成器的训练依靠每轮迭代返回当前生成样本与真实样本的差异(把这个差异转化成 loss)来进行参数优化,而判别器 D 的出现改变了这一点,判别器 D 的目标是尽可能准确地辨别生成样本和真实样本,而这时生成器 G 的训练目标就由最小化 “生成 - 真实样本差异” 变为了尽量弱化判别器 D 的辨别能力(这时候训练的目标函数中包含了判别器 D 的输出)。GAN 模型的大体框架如下图所示:
我们再来简单复习一下 GAN 当中的一些重要公式,这一步对后文的阐述非常重要。不管生成器 G 是什么形状、多么深的一个神经网络,我们暂且把它看成一个函数 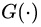
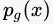
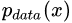
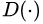
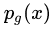
而 GAN 模型的整体优化目标函数是:
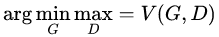
其中函数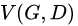
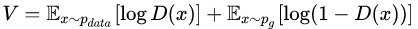
根据连续函数的期望计算方法,上式变形为:
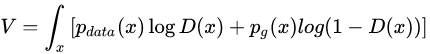
先求外层的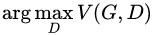
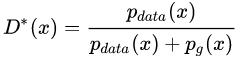
代回原式:
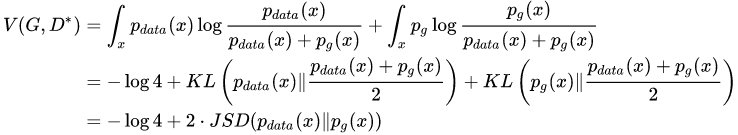
所以,当生成器 G 能生成出与真实样本一样分布的样本,那么 ok,就达到最好的结果,然后大家注意一点,这里生成样本的 loss 衡量方法是 JS 散度。
2.2. GAN 面对离散型数据时的困境(啥是离散型数据?)
GAN 的作者早在原版论文 [8] 时就提及,GAN 只适用于连续型数据的生成,对于离散型数据效果不佳(使得一时风头无两的 GAN 在 NLP 领域一直无法超越生成模型的另一大佬 VAE[9])。文本数据就是最典型的一种离散型数据,这里所谓的离散,并不是指:文本由一个词一个词组成,或是说当今最流行的文本生成框架,诸如 Seq2Seq,也都是逐词(或者逐个 Character)生成的。因为哪怕利用非循环网络进行一次成型的 Sentences 生成,也无法避免 “数据离散” 带来的后果,抱歉都怪我年轻时的无知,离散型数据的真正含义,我们要从连续性数据说起。 图像数据就是典型的连续性数据,故而 GAN 能够直接生成出逼真的画面来。我们首先来看看图像数据的形状:
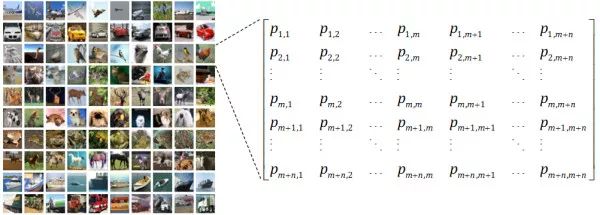
图像数据在计算机中均被表示为矩阵,若是黑白图像矩阵中元素的值即为像素值或者灰度值(抱歉外行了,我不是做图像的),就算是彩色图像,图像张量即被多加了一阶用于表示 RGB 通道,图像矩阵中的元素是可微分的,其数值直接反映出图像本身的明暗,色彩等因素,很多这样的像素点组合在一起,就形成了图像,也就是说,从图像矩阵到图像,不需要 “采样”(Sampling),有一个更形象的例子:画图软件中的调色板,如下图,你在调色板上随便滑动一下,大致感受一下图像数据可微分的特性。

文本数据可就不一样了,做文本的同学都知道,假设我们的词库(Vocabulary)大小为 1000,那么每当我们预测下一个出现的词时,理应得到的是一个 One-hot 的 Vector,这个 Vector 中有 999 项是 0,只有一项是 1,而这一项就代表词库中的某个词。然而,真正的隔阂在于,我们每次用无论什么分类器或者神经网络得到的直接结果,都是一个 1000 维的概率分布,而非正正好好是一个 One-hot 的 Vector,即便是使用 softmax 作为输出,顶多也只能得到某一维上特别大,其余维上特别小的情况,而将这种输出结果过渡到 One-hot vector 然后再从词库中查询出对应 index 的词,这样的操作被称为 “Sampling”,通常,我们找出值最大的那一项设其为 1,其余为 0。
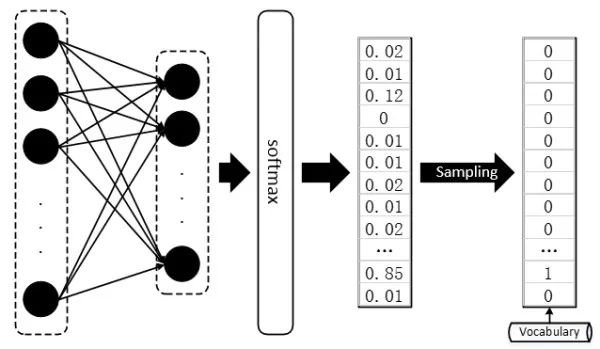
当前神经网络的优化方法大多数都是基于梯度的(Gradient based),很多文献这么说:GAN 在面对离散型数据时,判别网络无法将梯度 Back propagation(BP)给生成网络。这句话当时让我等听的云里雾里,不妨换一个角度理解,我们知道,基于梯度的优化方法大致意思是这样的,微调网络中的参数(weight),看看最终输出的结果有没有变得好一点,有没有达到最好的情形。
但是判别器 D 得到的是 Sampling 之后的结果,也就是说,我们经过参数微调之后,即便 softmax 的输出优化了一点点,比如上图的例子中,正确结果本应是第三项,其 output 的倒数第二项从 0.82 变为了 0.65,第三项从 0.12 变为了 0.32,但是经过 Sampling 之后,生成器 G 输出的结果还是跟以前一模一样,并再次将相同的答案重复输入给判别器 D,这样判别器 D 给出的评价就会毫无意义,生成器 G 的训练也会失去方向。
有人说,与其这样不如每次给判别器 D 直接吃 Sampling 之前的结果,也就是 softamx 输出的那个 distribution,同样,这么做也有很大的问题。我们回到 GAN 的基本原理,判别器 D 的初衷,它经历训练就是为了准确辨别生成样本和真实样本的,那么生成样本是一个充满了 float 小数的分布,而真实样本是一个 One-hot Vector,判别器 D 很容易 “作弊”,它根本不用去判断生成分布是否与真实分布更加接近,它只需要识别出给到的分布是不是除了一项是 1 ,其余都是 0 就可以了。所以无论 Sampling 之前的分布无论多么接近于真实的 One-hot Vector,只要它依然是一个概率分布,都可以被判别器 D 轻易地检测出来。
上面所说的原因当然也有数学上的解释,还记得在 2.1 节的时候,请大家注意生成样本的 loss 衡量标准是什么吗?没错,就是 JS 散度,JS-divergence 在应用上其实是有弱点的(参考文献 [10]),它只能被正常地应用于互有重叠(Overlap)的两个分布,当面对互不重叠的两个分布 P 和 Q,其 JS 散度:
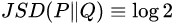
大家再想想,除非 softmax 能 output 出与真实样本 exactly 相同的独热分布(One-hot Vector)(当然这是不可能的),还有什么能让生成样本的分布与真实样本的分布发生重叠呢?于是,生成器无论怎么做基于 Gradient 的优化,输出分布与真实分布的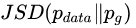
3. 过渡方案:对于 GAN 的直接改进用于文本生成
为了解决 GAN 在面对离散数据时的困境,最直接的想法是对 GAN 内部的一些计算方式进行微调,这种对于 GAN 内部计算方式的直接改进也显示出了一定的效果,为后面将 GAN 直接、流畅地应用于文本等离散型数据的生成带来了希望。 接下来简单介绍相关的两篇工作 [11~12]。
3.1. Wasserstein-divergence,额外的礼物
Wasserstein GAN[13](简称 WGAN),其影响力似乎达到了原版 GAN 的高度,在国内也有一篇与其影响力相当的博文——“令人拍案叫绝的 Wasserstein GAN”[10],不过在看这篇论文之前,还要推荐另外一篇论文 “f-GAN”[14],这篇论文利用芬切尔共轭(Fenchel Conjugate)的性质证明了任何 f-Divergence 都可以作为原先 GAN 中 KL-Divergence(或者说 JS-Divergence)的替代方案。 f-GAN 的定义如下:
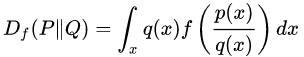
公式中的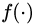
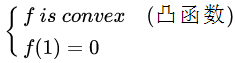
不难看出, KL-Divergence 也是 f-Divergence 的一种,f-GAN 原文提供了数十种各式各样的 f-Divergence,为 GAN 接下来沿此方向上的改进带来了无限可能。
Wasserstein GAN 对 GAN 的改进也是从替换 KL-Divergence 这个角度对 GAN 进行改进,其详细的妙处大可参看文献 [10,13],总的来说,WGAN 采用了一种奇特的 Divergence—— “推土机 - Divergence”,Wasserstein-Divergence 将两个分布看作两堆土,Divergence 计算的就是为了将两个土堆推成一样的形状所需要泥土搬运总距离。如下图:
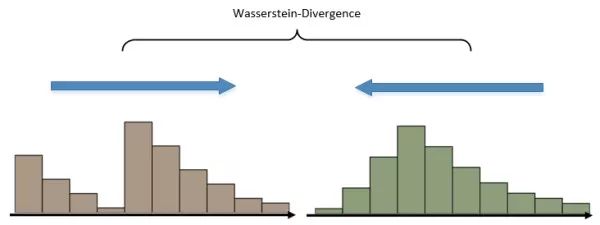
使用 Wasserstein-Divergence 训练的 GAN 相比原版的 GAN 有更加明显的 “演化” 过程,换句话说就是,WGAN 的训练相比与 GAN 更加能突显从 “不好” 到 “不错” 的循序渐经的过程。从上面的 2.2 节,我们知道 JS 散度在面对两个分布不相重叠的情况时,将发生 “异常”,计算结果均为

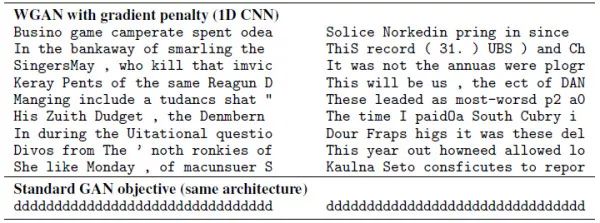
既然 Wasserstein 散度能够克服 JS 散度的上述弱点,那么使用 Wasserstein GAN 直接吸收生成器 G softmax 层 output 的 Distribution Vector 与真实样本的 One-hot Vector,用判别器 D 进行鉴定,即便判别器 D 不会傻到真的被 “以假乱真”,但生成器 output 每次更加接近于真实样本的 “进步” 总算还是能被传回,这样就保证了对于离散数据的对抗训练能够继续下去。不过 Wasserstein GAN 的原著放眼于对于 GAN 更加远大的改进意义,并没有着重给出关于文本生成等离散数据处理的实验,反倒是后来的一篇 “Improved Training of Wasserstein GANs”[11] 专门给出了文本生成的实验,从结果上可以看出,WGAN 生成的文本虽然远不及当下最牛 X 的文本生成效果,但好歹能以 character 为单位生成出一些看上去稍微正常一点的结果了,对比之下,GAN 关于文本生成的生成结果显然是崩塌的。
3.2. Gumbel-softmax,模拟 Sampling 的 softmax
另外一篇来自华威大学 + 剑桥大学的工作把改进 GAN 用于离散数据生成的重心放在了修改 softmax 的 output 这方面。如 2.2 节所述,Sampling 操作中的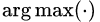
既然如此,论文的作者寻找了一种可以高仿出 Sampling 效果的特殊 softmax,使得 softmax 的直接输出既可以保证与真实分布的重叠,又能避免 Sampling 操作对于其可微特征的破坏。它就是 “耿贝尔 - softmax”(Gumbel-Softmax),Gumbel-Softmax 早先已经被应用于离散标签的再分布化 [15](Categorical Reparameterization),在原先的 Sampling 操作中,
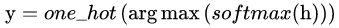
而 Gumbel-Softmax 略去了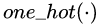
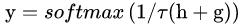
精髓在于这其中的 “逆温参数”τ,当 τ → 0 时,上式所输出的分布等同于
论文的实验仅仅尝试使用配合 Gumbel-Softmax 的 GAN 进行长度固定为 12 的 Context-free grammar 序列生成,可见 GAN 的训练并没有崩塌,在少数样例上也得到了还算逼真的效果。

所以,对于 GAN 进行直接改进用于文本生成,虽说是取得了一定的成效,但距离理想的状态仍然道阻且长,有没有更好的办法呢?当然!
4. RL 在 GAN 文本生成中所扮演的作用
4.1. 关于 Reinforcement Learning 的闲聊闲扯
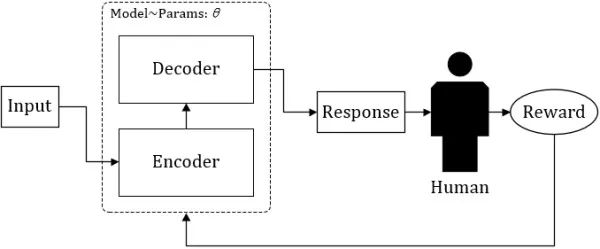
强化学习(Reinforcement Learning,RL)由于其前卫的学习方式,本不如监督学习那么方便被全自动化地实现,并且在很多现实应用中学习周期太长,一直没有成为万众瞩目的焦点,直到围棋狗的出现,才吸引了众多人的眼球。
RL 通常是一个马尔科夫决策过程,在各个状态 
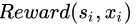
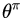
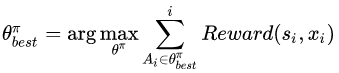
为了达到这个目标,强化学习机可以在各个状态尝试各种可能的动作,并通过环境(大多数是人类)反馈的奖励或者惩罚,评估并找出能够最大化期望奖励 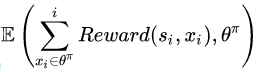
其实也有人将 RL 应用于对话生成的训练当中 [16],因为对话生成任务本身非常符合强化学习的运行机理(让人类满意,拿奖励)。设,根据输入句子 a ,返回的回答 x 从人类得到的奖励记为 R(a,x) ,而 Encoder-Decoder 对话模型服从的参数被统一记为 θ ,则基于 RL 的目标函数说白了就是最大化生成对话的期望奖励,其中 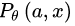
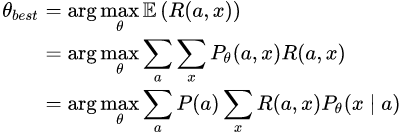
既然是一个最优化的问题,很直接地便想到使用基于梯度(Gradient)的优化方法解决。当然,在强化学习中,我们要得到的是最优策略 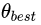
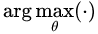
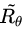
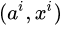
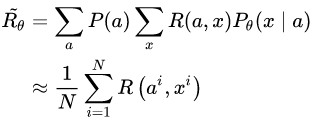
在优化过程中,对话模型的权重 θ 更新如下, 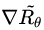
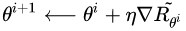
借助复合函数的求导法则,继续推导奖励的变化梯度,
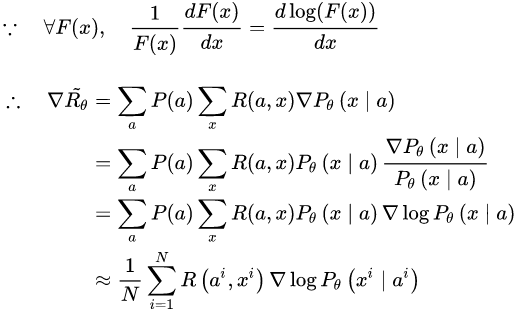
这样一来,梯度优化的重心就转化到了生成对话的概率上来,也就是说,通过对参数 θ 进行更新,奖励会使模型趋于将优质对话的出现概率提高,而惩罚则会让模型趋于将劣质对话的出现概率降低。
自 AlphaGo 使得强化学习猛然进入大众视野以来,大部分对于强化学习的理论研究都将游戏作为主要实验平台,这一点不无道理,强化学习理论上的推导看似逻辑通顺,但其最大的弱点在于,基于人工评判的奖励 Reward 的获得,让实验人员守在电脑前对模型吐出来的结果不停地打分看来是不现实的,游戏系统恰恰能会给出正确客观的打分(输 / 赢 或 游戏 Score)。基于 RL 的对话生成同样会面对这个问题,研究人员采用了类似 AlphaGo 的实现方式(AI 棋手对弈)——同时运行两个机器人,让它们自己互相对话,同时,使用预训练(pre-trained)好的 “打分器” 给出每组对话的奖励得分 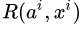
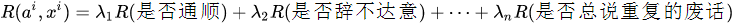

稍微感受一下 RL ChatBot 的效果:

4.2. SeqGAN 和 Conditional SeqGAN
前面说了这么多,终于迎来到了高潮部分:RL + GAN for Text Generation,SeqGAN[17] 站在前人 RL Text Generation 的肩膀上,可以说是 GAN for Text Generation 中的代表作。上面虽然花了大量篇幅讲述 RL ChatBot 的种种机理,其实都是为了它来做铺垫。试想我们使用 GAN 中的判别器 D 作为强化学习中奖励 Reward 的来源,假设需要生成长度为 T 的文本序列,则对于生成文本的奖励值 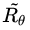
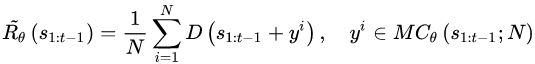
这里要说明几点,假设需要生成的序列总长度为 T,
在新一代的判别器 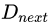
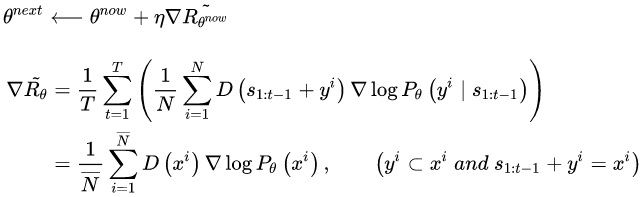
直到生成器 G 生成的文本足以乱真的时候,就是更新训练新判别器的时候了。一般来说,判别器 D 对生成序列打出的得分既是其判断该序列为真实样本的概率值,按照原版 GAN 的理论,判别器 D 对于 real/fake 样本给出的鉴定结果均为 0.5 时,说明生成器 G 所生成的样本足以乱真,那么倘若在上面的任务中,判别器屡屡对生成样本打出接近甚至高出 0.5 的得分时,即说明判别器 D 需要再训练了。在实做中为了方便,一般等待多轮生成器的训练后,进行一次判别器的训练。
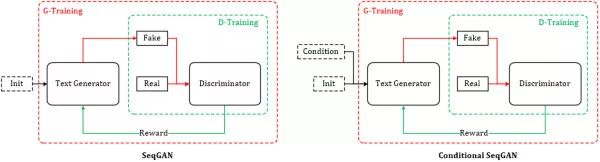
SeqGAN 的提出为 GAN 用于对话生成(Chatbot)完成了重要的铺垫,同样起到铺垫作用的还有另外一个 GAN 在图像生成领域的神奇应用——Conditional GAN[18~19],有条件的 GAN,顾名思义就是根据一定的条件生成一定的东西,该工作根据输入的文字描述作为条件,生成对应的图像,比如:

对话生成可以理解为同样的模式,上一句对话作为条件,下一句应答则为要生成的数据,唯一的不同是需要生成离散的文本数据,而这个问题,SeqGAN 已经帮忙解决了。综上,我自己给它起名:Conditional SeqGAN[20]。根据 4.1 节以及本节的推导,Conditional SeqGAN 中的优化梯度可写成:
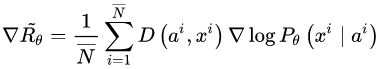
不难看出,此式子与 4.1 节中的变化梯度仅一字之差,只是把 “打分器” 给出的奖励得分 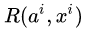
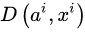
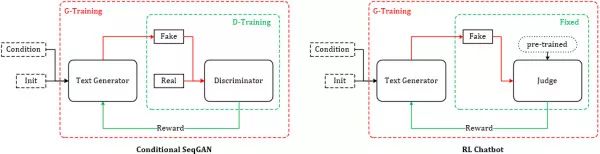
RL+ GAN 利用强化学习中的 Reward 机制以及 Policy Gradient 等技术,巧妙地避开了 GAN 面对离散数据时梯度无法 BP 的难题,在使用强化学习的方法训练生成器 G 的间隙,又采用对抗学习的原版方法训练判别器 D。 在 Conditional SeqGAN 对话模型的一些精选结果中,RL+ GAN 训练得到的生成器时常能返回一些类似真人的逼真回答(我真有那么一丝丝接近 “恐怖谷” 的感受)。

另外,相关细节与延伸参见明天将会推送的下篇。


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
手把手教你用 TensorFlow 实现文本分类(上)
▼▼▼



