ECCV 2020 | IIAI&谷歌等提出MIRNet:用于真实图像的恢复和增强
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:Whn丶nnnnn | 知乎专栏:论文学习
https://zhuanlan.zhihu.com/p/261580767
本文已由原作者授权,不得擅自二次转载
Learning Enriched Features for Real Image Restoration and Enhancement

论文地址:https://arxiv.org/abs/2003.06792
开源代码:https://github.com/swz30/MIRNet
补充材料:
https://drive.google.com/file/d/1QIKp7h7Rd85odaS6bDoeDGXb0VLKo8I9/view?usp=sharing
Title
学习丰富的特征,用于真实图像的恢复和增强(MIRNet),MIRNet针对低级图像任务,主要任务是图像去噪,超分辨,图像增强。本文与之前读过的CycleISP同属于阿联酋人工智能研究院的一个团队,两篇文章分别中了2020 CVPR oral和2020 ECCV,个人认为该团队在模块的选择,网络结构的构建上还是理解很深刻的,CycleISP的论文笔记我会在文章结尾处附上链接。
Keywords:Image denoising,super-resolution,image enhancement
Abstract
以从低分辨率(退化)图像中恢复出高质量图像内容为目标,图像恢复(Image Restoration)已经在众多领域得到广泛应用。现有的基于CNN的方法通常在全分辨率(full-resolution)或渐进式低分辨率(progressively low-resolution)上进行:在full-resolution下虽然得到了良好的空间精确度(spatially precise),但是不能获得鲁棒性较好的上下文信息(context);而在progressively low-resolution下,虽然在语义上可靠(semantically reliable)/得到好的上下文信息,但是在空间上并不太准确。那么在本文中,提出了一种新颖的结构,可以通过神经网络保持空间上精确的高分辨率表示;并从低分辨率表示中获取良好的上下文信息(strong contextual information)。网络的核心是包含几个关键元素的多尺度残差块(multi-scale residual block):(a)用于提取多尺度特征的并行多分辨率卷积流(parallel multi-resolution convolution streams);(b)跨多分辨率流的信息交换;(c)用于捕捉上下文信息的空间和通道注意机制(spatial and channel attention mechanisms);(d)基于注意机制的多尺度特征聚合(aggregation)。简言之,MIRNet学习丰富的特征,结合了多个尺度的上下文信息的同时保持了高分辨率的细节,在图像去噪、超分辨率、图像增强任务上取得了极好的效果。
1. Introduction
在图像采集时,经常会引入不同程度的退化(degradation),这可能是由于相机的物理因素限制,也可能是由于不合适的照明条件。因此常常会产生有噪点(noisy)和低对比度(low-contrast)的图像。近年来,深度学习模型在图像恢复和增强(image restoration and enhancement)方面取得重大进展,因为它可以从大规模数据集中学习到较强的前沿信息。现有的CNN通常遵循两种结构设计(这部分在Abstract里已经描述了,所以简单提一下,详细的可以参考原文):(a)Encoder-Decoder:将输入逐步映射为低分辨率(下采样),然后再反向映射为原始分辨率(上采样),这种U-Net结构的模型能够充分学习上下文信息(broad context),但是缺点是下/上采样过程中难以将空间细节恢复回来;(b)High-resolution(single-scale):不采用任何下采样操作,能够保持准确的空间细节,但是由于网络的感受野有限,在上下文信息获取方面的效率很低。
图像恢复重要的是仅出去不需要的退化图像内容(例如噪声),同时保持需要的空间细节(例如真实的纹理和边缘)。为了实现这一目标,本文提出了一种新的多尺度方法,该方法保持住原始高分辨率特征,减少了精确的空间细节损失;同时使用并行卷积流在较分辨率下获取上下文特征,多分辨率并行分支与主要高分辨率分支进行信息交换和互补,从而提供了空间细节精确而又上下文信息丰富的特征。
文中提出的方法与现有的多尺度图像处理方法的主要区别在于聚合上下文信息(aggregate contextual infomation)的方式。已有的方法通常分别(in isolation)处理各个尺度,并仅以从上向下的方式交换信息。相反,作者在各个分辨率上将所有尺度的信息逐步融合,从而有了自下而上和自上而下的信息交换;同时,使用提出的选择性核融合机制(selective kernel fusion mechanism),结合了具有不同感受野的特征。
本文的主要贡献包括:
提出了一种新型的特征提取模型(feature extraction model),可以在多尺度上提取互补的特征,同时保持原有的高分辨率特征以保留精确的空间细节。
提出定期重复的信息交换机制,将跨分辨率分支的特征逐渐融合在一起。
提出一种选择性核网络融合多尺度特征的方法,结合可变的感受野(receptive fields),在每个空间分辨率下保持原始特征信息。
递归残差设计(recursive residual design)简化了整体学习过程,允许构建更深的网络。
在5个真实图像基准数据集上进行试验,分别进行图像去噪、超分辨率、图像增强任务,均达到SOTA(state-of-the-art)的水平。
2. Related Work
这一部分还是老样子,简单写一写,具体内容还请参考原文和References部分进行学习。
Image denoising:经典方法主要基于修改变换系数(modifying transform coefficients)或邻域像素平均(averaging neighborhood pixels);基于自相似度(self-similarity)的算法:NLM、BM3D;利用图像中的冗余(自相似)的基于patch的算法;基于深度学习的方法:比如文中对比的CBDNet、VDN、RIDNet等。
Super-resolution(SR):在深度学习兴起之前,基于采样理论(sampling theory)、边缘引导插值(edge-guided interpolation)、图像先验信息(natural image priors)、patch-exemplars和稀疏(sparse representations)等理论已有了许多SR算法;深度学习兴起后,基于递归学习(recursive learning)、渐进重建(progressive reconstruction)、密集链接(dense connections)、注意机制(attention mechanisms)、多分支学习(multi-branch learning)和生成对抗网络(GAN)也有众多SR算法产出。
Image enhancement:对于图像增强,直方图均衡(histogram equalization)是最常用的算法,但经常会产生增强不足或过强的现象,受Retinex理论的激励,已有多种模仿人类视觉的增强算法被提出,最近也有基于CNN,encoder-decoder、GAN的神经网络被提出。
3. Proposed Method
首先概述提出的MIRNet,再对各部分细节进行详细的描述。MIRNet主要包括以下几个部分:
并行的多分辨率卷积流,用于提取(fine-to-coarse)从语义上更丰富和(coarse-to-fine)空间上精确的特征;
跨多分辨率流的信息交换;
来自多个流的特征基于注意机制的聚合(aggregation);
对偶注意单元(dual-attention units)用于捕获空间和通道维度的上下文信息;
残差大小调整模块,执行下采样和上采样操作。
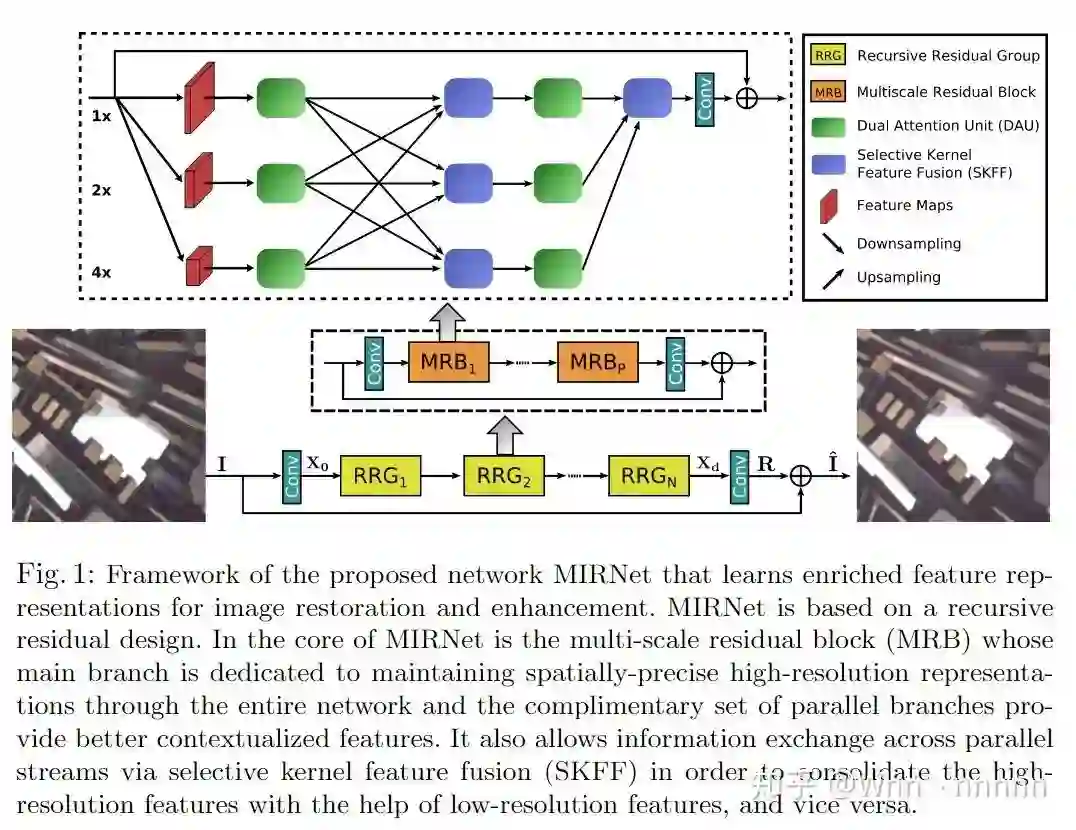
从上图可以看出,MIRNet主要是由多层RRG(Recursive Residual Group)堆叠而成的,而每个RRG内又包括多个MRB(Multi-scale Residual Block)模块,每个MRB展开后,内部有DAU(Dual Attention Unit)、SKFF(Selective Kernel Feature Fusion)等模块。整个网络的流水线(Pipeline)可以概述为:输入一张图片 









3.1. Multi-scale Residual Block(MRB)
为了对上下文进行encode,现有的CNN通常采用以下的架构设计:(a)神经元的感受野(receptive field)在每个层/阶段都是固定的;(b)特征图的空间大小逐渐减小以获得较强的低分辨率表示;(c)从低分辨率中逐渐恢复出高分辨率表示。但是众所周知,灵长类动物的视觉皮层中,同一区域的神经元的局部感受野的大小是不同的,在本文中,提出了多尺度残差块(MRB),通过保持高分辨率表示而生成空间精确的输出,同时从低分辨率接收丰富的上下文信息,文中的MRB包括并行连接的的多个(3个)卷积流。它允许跨并行卷积流进行信息交换,以便在低分辨率特征的帮助下合并高分辨率特征。
3.2. Selective kernel feature fusion(SKFF)
视觉皮层中的神经元的基本特征之一是能够根据刺激(stimulus)改变感受野,通过在同一层中使用多尺度特征生成(multi-scale feature generation),然后进行特征聚合和选择(feature aggregation and selection),可以将这种自适应调整感受野的机制并入CNN中。特征聚合最常用的方法包括简单的串联(concatenation)或加和(summation),然而这些选择只能为网络提供有限的表达能力,在MRB中,引入了一种利用自注意机制对多种分辨率的融合特征进行非线性处理的过程,将其称为选择性核特征融合(SKFF)。
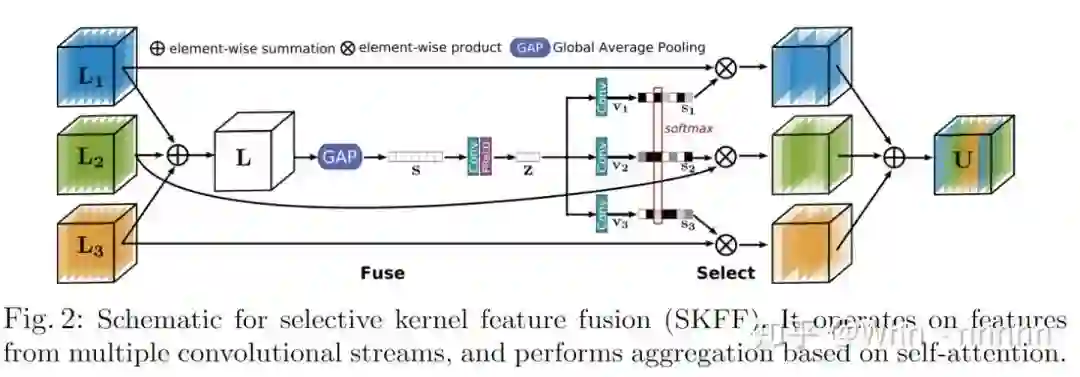
SKFF模块通过Fuse和Select两个操作对感受野进行动态调整,如上图所示。Fuse通过组合来自多分辨率流的信息来生成全局特征描述子(global feature descriptors),Select使用这些描述子对特征图进行重新校准并进行聚合。针对本文中的三个分支流:
(1)Fuse:从三个并行卷积流接收输入,首先按元素求和的方式将多尺度特征组合在一起: 






(2)Select:对 



3.3. Dual attention unit(DAU)
SKFF模块可以在多分辨率分支上融合信息,那么还需要一种在空间和通道维度上与特征张量进行信息共享的机制,此处作者提出了对偶注意力单元(dual attention unit,DAU)用来提取卷积流中的特征。DAU抑制作用较弱的特征,而仅允许带有更多信息的特征继续传递,DAU由CA(channel attention)和SA(spatial attention)两部分组成。
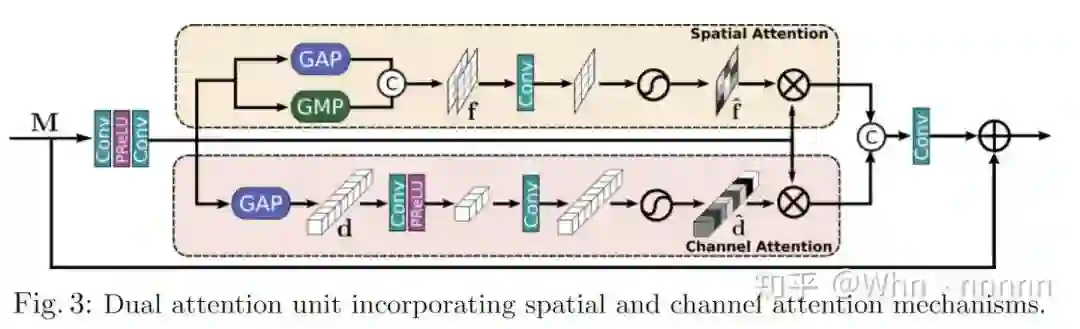
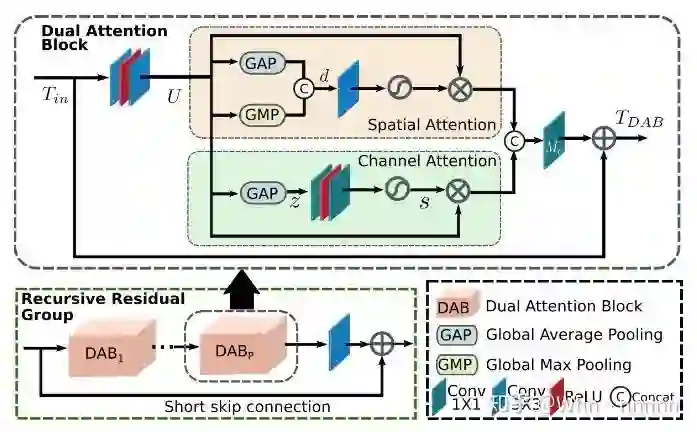
将上面的两图对比看,可以看出两个模块基本上完全一致,DAU(DAB)的确是该团队提出的网络中的关键模块,在CycleISP中并没有对CA和SA两个模块进行十分详细的描述,在本文中则着重讲了一下(这里推荐结合CycleISP以及SA和CA两篇参考文章一起学习):
(1)Channel attention(CA):通过squeeze和excitation操作来利用卷积特征图通道间的关系。给定一个特征图 




(2)Spatial attention(SA):旨在利用卷积特征图的空间依赖性,SA的目标是生成空间注意图,并使用它来重新校准传入的特征 


3.4. Residual resizing modules
MIRNet采用递归残差设计(recursive residual design)具有skip connections,可以简化学习过程中的信息流,为了保持结构中的残差性质(residual nature),引入了残差大小调整模块(residual resizing modules)来进行下采样和上采样。
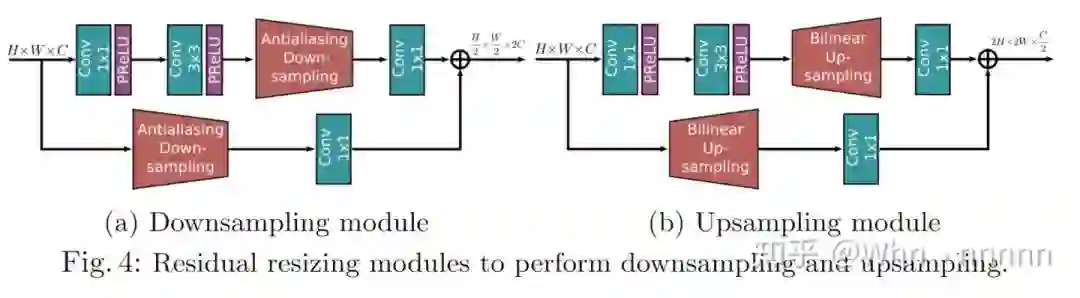
在MRB中,特征图的大小沿卷积流保持不变,而跨流方向,特征图的大小根据输入分辨率索引和输出分辨率索引进行变化(下采样或上采样),执行2倍下采样则将上图中的下采样模块应用一次,对于4倍下采样,则将该模块连续使用两次,上采样也是类似的操作。在上图中,作者集成了抗混叠下采样(anti-aliasing downsampling)来改善平移方差(shift-equivariance)。
4. Experiments
这一部分的详细内容还是请参考原文和文章的补充材料,在此只介绍一下使用的训练集,测试集,部分实现细节,以及图像去噪、超分辨、图像增强的部分实验结果,与SOTA算法的定量对比结果。
4.1. Real Image Datasets
Image denoising:(1)DND:由于不包含训练和验证集,所以50张图均用于test;(2)SIDD:320个图像对用于train,1280个图像对用于validation。
Super-resolution:(1)RealSR:2倍、3倍、4倍的train图像对分别有183、234、178对,每个尺度有30对图像用于test。
Image enhancement:(1)LoL:低亮度图片,485个图像对用于train,15对用于test;(2)MIT-Adobe FiveK:4500个图像对用于train,500对用于test。
4.2. Implementation Details
提出的网络是end-to-end可训练的,不需要预训练子模块,作者使用了3个RRG,每个RRG还包含2个MRB,每个MRB由3个并行卷积流组成,通道维度为64、128、256,分辨率的scale factors分别为 





4.3. Image Denoising


不难看出,MIRNet的确表现优异,在PSNR、SSIM数值上和视觉效果上,超过了RIDNet、VDN等算法,达到SOTA级别的效果。
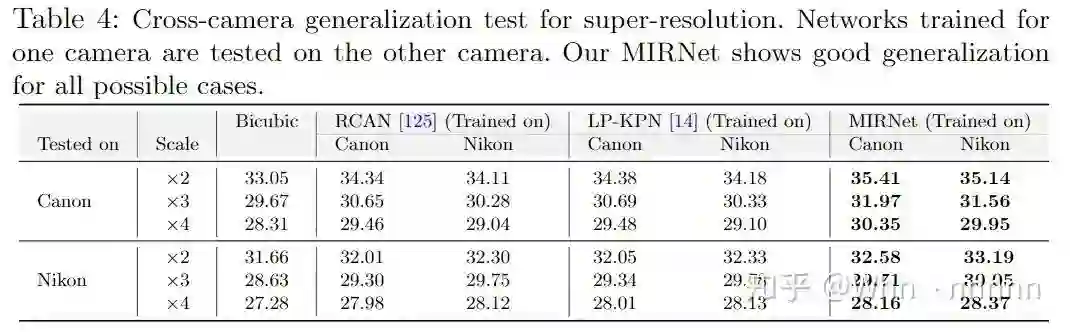
4.4. Super-Resolution(SR)
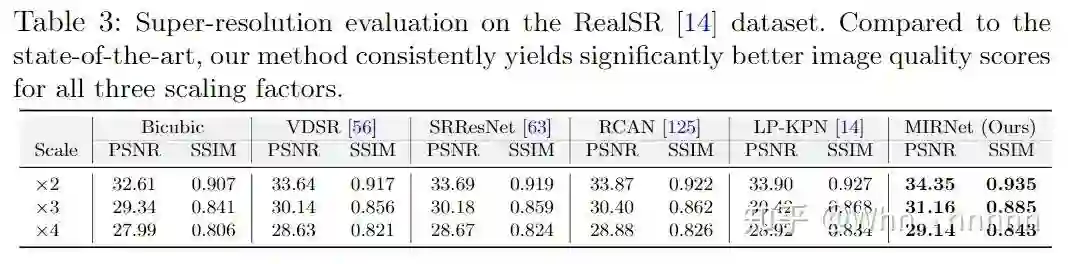

对于SR部分,我了解的方法并不太多,不过从文中的实验对比数据来看,MIRNet的表现还是十分优秀的,因为了解不多,这里就不做过多的评价了。
4.5. Image Enhancement
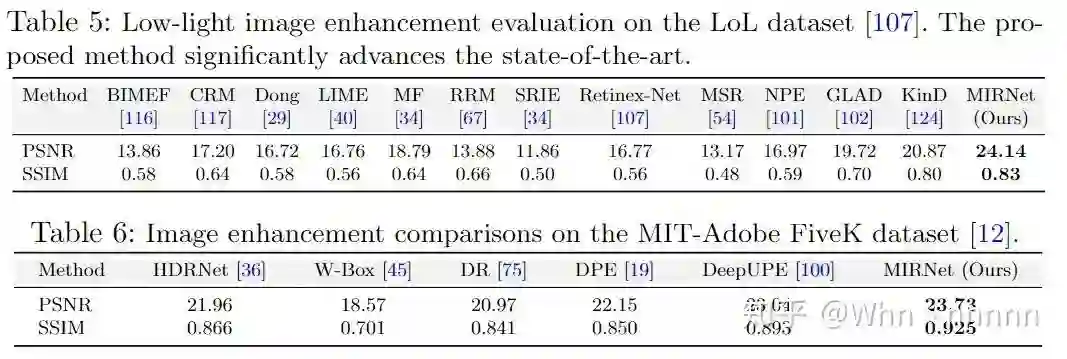

对于图像增强,我了解的就要更少一点了,所以还是仅就文中的实验数据和视觉效果来看,MIRNet的效果不弱于其他SOTA算法。
By the way,由于文章略长,MIRNet在去噪,超分,增强方面均可以应用,对比数据较多,所以这里只截取了一部分图片,可以在文章中和Supplementary中找到更详细的结果对比。此外,文章中在三个应用领域部分分别提及了模型的泛化能力(generalization),这里也只做一个综述:去噪方面,SIDD和DND数据集中的图片有着不同特征的噪声,而训练时仅使用SIDD训练集,模型在SIDD和DND测试集上均表现良好,证明了MIRNet良好的泛化能力;超分辨率方面,使用Canon和Nikon两种相机的图片进行了一个交叉实验,验证了MIRNet的泛化能力较强。
5. Ablation Studies
由于投稿篇幅的限制,有一部分消融实验(Ablation studies)的数据被放在了补充材料中,这部分,作者主要验证了使用的Skip connections、DAU、SKFF、residual resizing modules等模块的必要性,对性能的提升,以及内部结构的选择,在这里主要选取一部分结果图即可。
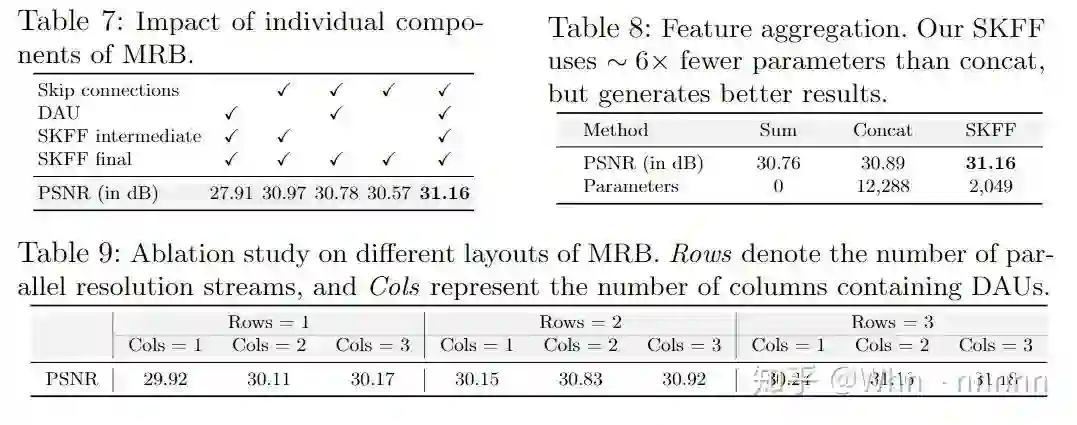

6. Concluding Remarks
在本文中,作者团队提出了一种新颖的网络结构,主要分支致力于全分辨率处理,而互补的并行分支则提供了良好的上下文特征,网络学习每个分支以及跨多尺度分支的特征间的关系,在确保不牺牲原始特征细节的情况下动态调整感受野,进行特征融合,在图像去噪、超分辨率、图像增强三个任务,五个数据集上均表现优异。
7. Something I want to say
(这篇文章加上补充材料...真的略长,猛玩了3天之后终于开始学习。)
文章提出的网络在PSNR、SSIM数值结果和视觉效果上的确表现十分优秀,DND sRGB benchmark上rank4(前3名我查不到文章和代码),在我自己的real-world noisy images上去噪效果也很不错,不得不说,阿联酋AI研究所的这支队伍对于网络结构的设计,模块的选择真的有很独到的见解,MIRNet和CycleISP分别中了ECCV和CVPR,MIRNet着重低级图像任务(去噪、超分、增强),而CycleISP的主要贡献则是用神经网络模拟ISP和逆ISP过程,为real-world noisy images数据的创造提供了新的方法,而在去噪网络部分则设计的比较简单。两篇文章都十分重视RRG,DAU这些模块,而且也都得到了很不错的结果,也给了我很多启发。
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-去噪、超分辨率交流群成立
扫码添加CVer助手,可申请加入CVer-去噪、超分辨率 微信交流群,目前已满300+人,旨在交流去噪等写事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如去噪、超分辨率+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!

