76分钟训练BERT!谷歌深度学习的大批量优化研究被ICLR 2020接收

新智元报道
新智元报道
来源:arXiv
新智元编辑部
【新智元导读】爱也BERT,恨也BERT!BERT是史上最强的NLP模型之一,但却也是工业界目前最耗时的应用,计算量远高于ImageNet!谷歌的研究人员提出新的优化器,将BERT的训练时间从3天成功缩短到76分钟!该论文已被ICLR 2020接收。戳右边链接上 新智元We站公开课 了解更多!
谷歌发布的史上最强NLP模型之一BERT,是NLP领域的一项重大突破。
随着大规模数据集的出现,在海量数据集上训练大型深度神经网络,甚至使用随机梯度下降(Stochastic Gradient Descent,SGD)等计算效率高的优化方法,都已变得尤为具有挑战性。例如,BERT和ResNet-50等最先进的深度学习模型在16个TPUv3芯片上训练需要3天,在8台Tesla P100 GPU上训练需要29小时。
人们对于使用大批量随机优化方法来解决此问题的兴趣激增。该研究领域中最杰出的算法是LARS,它通过采用逐层自适应学习率,在几分钟内在ImageNet上训练RESNET。然而,LARS对于像BERT这样的注意力模型表现不佳,这表明其性能增益在各个任务之间并不一致。
这该如何是好?且来看看近日 Google、UC Berkeley、UCLA研究团队的被ICLR 2020接收的力作——《Large Batch Optimization for Deep Learning: Training BERT in 76 minutes》。他们首先研究了一种原则性的逐层自适应策略,来加速large mini-batches的深度神经网络的训练。利用该策略,研究团队开发了一种新的逐层自适应大批量优化技术LAMB,并给出了LAMB和LARS的收敛分析,表明在一般非凸情形下收敛到驻点(Stationary Point)。实验结果表明,LAMB在BERT和RESNET-50训练等任务中具有很好的性能,且超参数调整很少。特别是对于BERT训练,提出的优化器支持使用非常大(32868)的批处理,而不会降低性能。通过将批处理大小增加到TPUv3 Pod的内存限制,BERT训练时间可以从3天减少到76分钟!


受LARS的启发,研究了一种特别适合大批量学习的通用适应策略,并为该策略提供了直觉。
基于自适应策略,提出了一种新的优化算法(LAMB)来实现SGD中学习速率的自适应。此外,还提供了LARS和LAMB的收敛分析,以获得非凸情况下的一个驻点。我们将重点介绍在大型批处理设置中使用这些方法的好处。
展示了LAMB在多个挑战性任务中的强大实证性能。使用LAMB,将训练BERT的批量大小扩展到32k以上,而不会降低性能;时间从3天减少到76分钟。这是目前将BERT训练经过时间减少到几个小时以内的第一项工作。
还展示了LAMB在训练RESNET这样最先进的图像分类模型方面的效率。本项研究提出的自适应解算器是第一个能够为RESNET-50实现最先进准确性的自适应解算器。
LAMB的全称是Layer-wise Adaptive Moments optimizer for Batching training。
BERT 训练的基线使用权重衰减的 Adam 作为优化器,这是 Adam 优化器的一个变体。另一个自适应优化器LARS,早前被提出用于ImageNet上RESNET的大批量学习。
为了得到进一步的改进,研究团队对LAMB使用混合批处理训练。BERT训练包括两个阶段:总epochs的前9/10使用128的序列长度,而总epochs的后1/10使用512的序列长度。由于内存限制,第二阶段的训练需要更长的序列长度,因此在TPUv3 Pod上最多只能使用32768个批处理大小。
LAMB 算法的概述如下所示:

本研究在两个重要的大批量训练任务:BERT和RESNET-50训练上,比较LAMB与现有优化器的实证结果。还比较了在小批量(<1k)和小数据集(如CiFAR、MNIST)上,LAMB与现有优化器的结果。
BERT训练
首先是加速BERT训练的实证结果。本实验使用与Devlin et al.相同的数据集,由Wikipedia和BooksCorpus拼接而成,分别为2.5B和8亿词。在本文中,特别关注的是SQuAD task。在实验中,以SQuAD-v1上的F1分数作为精度指标,所有的比较都是基于Devlin等人的基线BERT模型。
为了训练BERT, Devlin等人首先使用序列长度为128的900k迭代训练模型,然后在最后的100k迭代中转换为512的序列长度。这导致了在16个TPUv3芯片上大约需要3天的训练时间。
文本首先的实验,除了将训练优化器更改为LAMB之外,保持与基线相同的训练过程,使用与基线相同数量的epochs运行,但批量大小从512扩展到32K(选择32K大小(序列长度512)主要是由于TPU Pod的内存限制)。通过使用LAMB优化器,能够在批量大小为32768的15625次迭代(序列长度为128的14063次迭代和序列长度为512的1562次迭代)中获得91.460的F1分数。对于批量大小为32K,本文将BERT训练时间从3天缩短到约100分钟。
本文在表中报告F1分数为91.345,这是未调谐版本的分数。
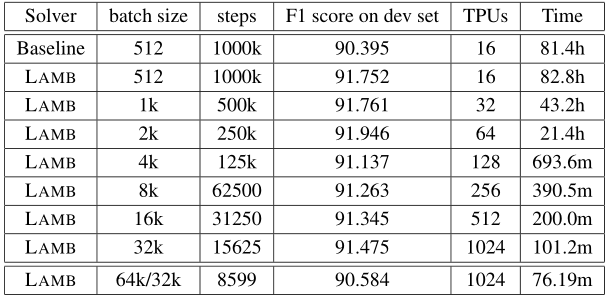
表 1:使用SQuAD-v1的F1 score作为精度指标。F1的基线成绩是由BERT的公共知识库提供的预训练模型(BERT-large)实现的 (截止到2019年2月1日)。本文在实验中使用TPUv3s。本文使用了与基线相同的设置:总epochs的前9/10使用序列长度128,最后 1/10使用序列长度512。所有的实验运行相同数量的epochs。Dev set表示测试数据。值得注意的是,本文可以通过手动调整超参数来获得更好的结果。
大批量处理技术是加快深度神经网络训练的关键。本文提出了LAMB优化器,它支持自适应的元素更新(Adaptive Elementwise Updating)和逐层学习率(Layerwise Learning Rates)。此外,LAMB是一个通用优化器,适用于小批量和大批量。
本文还为LAMB优化器提供了理论分析,重点介绍了其性能优于标准SGD的情况。对于广泛的应用程序,LAMB的性能要优于现有的优化器。通过使用LAMB,我们可以将BERT预训练的批处理规模扩展到64K而不失准确性,从而将BERT训练时间从3天缩短到76分钟左右。LAMB也是第一个能够在RESNET-50的ImageNet训练中获得最先进精度的大批量自适应解算器。



