【ICML2022】NeuroFluid: 流体仿真的人工智能新范式
“
近日,上海交通大学人工智能研究院杨小康教授、王韫博助理教授指导的AI+Science研究团队的成果《NeuroFluid: Fluid Dynamics Grounding with Particle-Driven Neural Radiance Fields》被国际顶级机器学习会议ICML 2022收录。论文所提出的“神经流体(NeuroFluid)”模型,利用基于神经隐式场的人工智能可微渲染技术,将流体物理仿真看作求解流体场景三维渲染问题的逆问题——从流体场景的一段多视角表观图像中,即可反推出流体内部的运动规律。这项成果为计算流体动力学、多粒子动力学系统研究开辟了一种人工智能新途径。
论文链接:
https://www.zhuanzhi.ai/paper/ddad8ebf86c68fae5d98015f1bc671f7
代码地址:
github.com/syguan96/NeuroFluid
项目主页:
syguan96.github.io/NeuroFluid/
● ● ● ● ● ● ●

图1. NeuroFluid从流体的视觉观测中反演其物理动态
流体运动研究是重要的自然科学基础研究领域,在航空航天、大气、海洋、航运、能源、建筑、环境等众多领域有着广泛应用。在传统研究方法中,求解流体运动(例如速度场)需要首先在理论上精确刻画流体的动力学模型,并结合微分方程、数值分析对模型求解。但是通常对于复杂问题(例如湍流),人们很难用数学物理方程进行描述,复杂流体的Navier-Stokes方程是世界级千禧难题,至今依然没被很好解决。现有基于深度学习的方法通常从拉格朗日视角描述流体,即流体被看作由许多粒子组成,通过测定和约束每个粒子的运动即可测定和改变流体的运动。但是大多数方法通常要求已知流体的物理属性(例如粘性),并且需要粒子的运动信息(位置和速度)作为训练数据,这在真实场景中几乎不太可能。
针对流体力学模型难以刻画和求解的问题,本文提出一种名为NeuroFluid的神经网络方法,实现流体动态反演(fluid dynamics grounding),即根据稀疏视角下对流体的2D表观视觉观察,推断推流体内在的3D物理运动状态,例如粒子的速度和位置等。如图2所示,NeuroFluid包含基于神经网络的流体粒子状态转移模型(Particle Transition Model)和由粒子驱动的神经网络渲染器(PhysNeRF),并将二者整合到一个端到端的联合优化框架中。优化过程包含三个阶段:
1. 模拟:粒子状态转移模型根据初始状态(可用立体视觉方法粗估)预测流体粒子在后续时刻的运动轨迹;
2. 渲染:神经网络渲染器PhysNeRF(图2右)根据粒子的几何信息将模拟结果渲染成图像;
3. 比对:渲染图像和真实图像比对,计算误差,通过梯度反向传递优化模型参数。
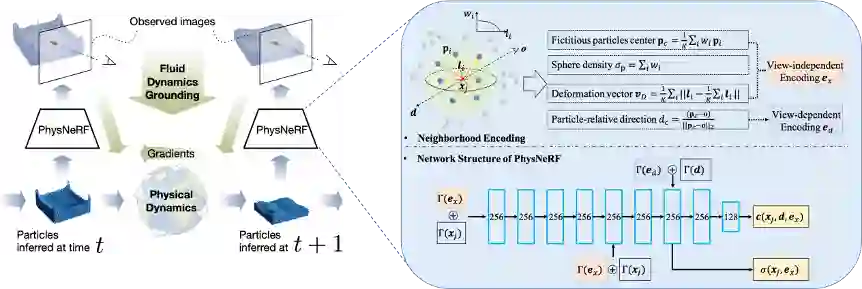
图2. NeuroFluid的训练过程(图左)及PhysNeRF的渲染示意(图右)
本文使用的流体数据(HoneyCone、WaterCube、WaterSphere)具有不同的物理属性(如密度、粘度、颜色)或初始状态(如流体粒子位置、整体形态)。
下列的实验从粒子动态反演、未来状态预测、新视角图像渲染、PhysNeRF域外场景泛化,验证了NeuroFluid的有效性。
1
实验1:流体粒子动态反演
本实验计算从图像反演的粒子位置与真实粒子位置之间的距离误差(Pred2GT distance),作为评价指标。图3展示了NeuroFluid与流体粒子预测的有监督方法DLF[1]的数值结果对比,显然,NeuroFluid从视频中反演的流体粒子状态比DLF(用粒子运动速度和位置作为训练数据)更准确。图4对模型的粒子状态推断结果做了可视化,注意到随着时间的推移,NeuroFluid相比基线模型,其反演结果运动更加自然,能更好地匹配真实流体动态。
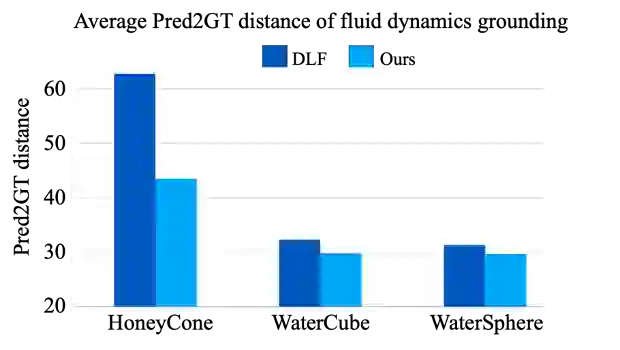
图3. NeuroFluid(浅蓝色)在三个测试集上关于流体粒子位置的反演结果,相比流体粒子仿真的有监督模型DLF,NeuroFluid从图像推理流体内部状态,明显具有更好的准确性
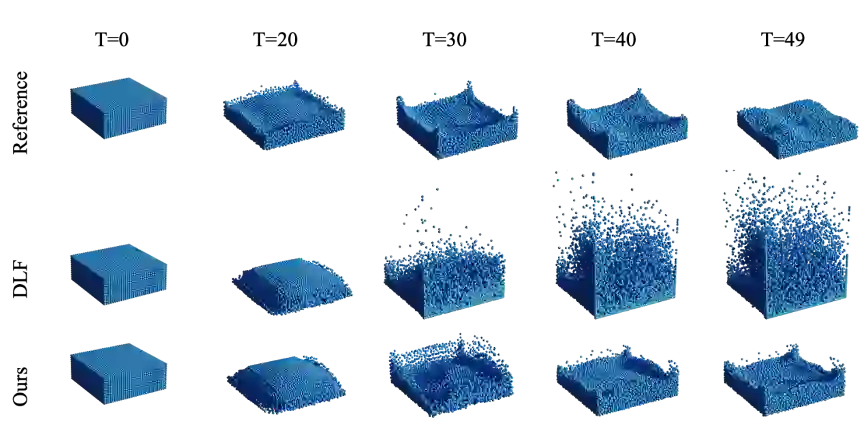
图4. NeuroFluid(第三行)在WaterCube场景中对流体粒子位置的推断结果,图中第一行为生成对应观测图像序列时所使用的“真实”流体粒子位置
2
实验2:流体未来状态预测
在有效学习了流体的粒子状态转移模型后,可以很方便地实现预测流体在未来时刻的运动状态。如图5所示,本实验评估未来十个时刻内,模型预测的粒子位置与真实情况的误差。结果表明,NeuroFluid能够通过视觉观测学习流体运动的规律,推演合理的流体未来动态。
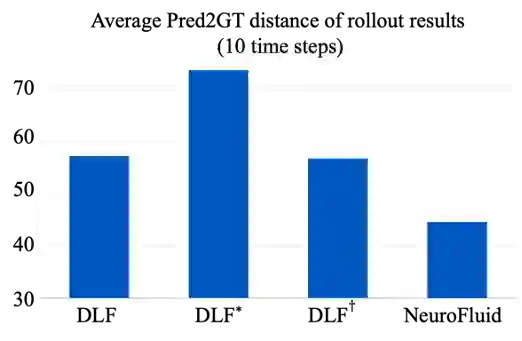
图5. 流体未来状态预测误差。其中,DLF*表示将基线模型在与测试场景物理属性相近的数据上进行微调;DLF+表示将基线模型直接在测试场景上进行微调
3
实验3:流体场景的新视角图像渲染
为了验证PhysNeRF渲染器的有效性,本实验在新视角合成(novel view synthesis)的任务上,广泛对比了各种基于神经隐式场的可微渲染技术,包括NeRF[2],NeRT-T (即NeRF+Time Index), D-NeRF[3]和Li et al. (2022)[4]等。如图6所示,在输入了粒子几何信息的情况下,NeuroFluid的渲染结果不仅在动态上与目标结果的匹配度最高,而且可以更好地渲染出流体的细节(如溅起的水珠)。

图6. 新视角合成结果对比,左起第一列为新视角下的目标图像
4
实验4: 域外场景泛化
PhysNeRF的基本假设是流体图像渲染应以粒子状态为驱动,故而应具有不同粒子分布下的强大泛化能力。为验证其泛化能力,本实验在使用有限的场景训练好PhysNeRF渲染器后,在测试时改变了流体的初始形貌,如图7所示,该几何形状为计算机图形学经典的Stanford Bunny。值得注意的是,在没有用Stanford Bunny数据对模型进行训练微调的情况下,PhysNeRF较为精细地渲染出了流体的表面细节。

图7. PhysNeRF在域外流体场景(训练所未见)上的泛化效果
总结:上海交通大学AI+Science研究团队所提出的NeuroFluid模型能成功拟合符合视觉观测的流体运动转移规律,从视觉表观观测反演流体内在运动,有望为传统流体力学无法准确刻画的复杂流体运动(如湍流)提供一种全新的计算范式。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NRFD” 就可以获取《【ICML2022】NeuroFluid: 流体仿真的人工智能新范式》专知下载链接



