
题目:* Variational Autoencoders and Nonlinear ICA: A Unifying Framework
摘要:
变分自编码器的框架使我们能够有效地学习深层潜在变量模型,从而使模型的边际分布对观测变量的适应数据。通常,我们想要更进一步,想要在观察到的和潜在的变量上近似真实的联合分布,包括在潜在变量上真实的前后分布。由于模型的不可识别性,这通常是不可能的。我们解决这个问题的方法是证明,对于一个广泛的深层潜在变量模型,通过观察到的和潜在的变量来识别真正的联合分布实际上是可能的,直到非常简单的转换。我们的结果需要对潜在变量进行因式的先验分布,这些潜在变量取决于另外观察到的变量,如类标签或几乎任何其他观察结果。我们以非线性独立分量分析的最新发展为基础,将其扩展到有噪声的、不完全的或离散的观测,并集成在极大似然框架中。作为一个特例,结果也包含了可识别的基于流的生成模型。
作者简介:
Ilyes Khemakhem是UCL Gatsby计算神经科学学院三年级的博士生,导在读博士之前,在Ecole polytechnique完成了工程学位,主要研究应用数学,还获得了计算机视觉和机器学习(MVA)硕士学位。研究主要集中在无监督学习,即非线性独立分量分析、密度估计。还对因果关系、神经科学(特别是在神经成像数据上应用机器学习模型)、统计物理和微分几何感兴趣。个人主页:https://ilkhem.github.io/
Durk Kingma是机器学习领域的研究科学家,在谷歌大脑工作,拥有阿姆斯特丹大学的博士学位。研究过生成模型、变分(贝叶斯)推理、随机优化、可识别性等课题。个人主页:http://www.dpkingma.com/
成为VIP会员查看完整内容


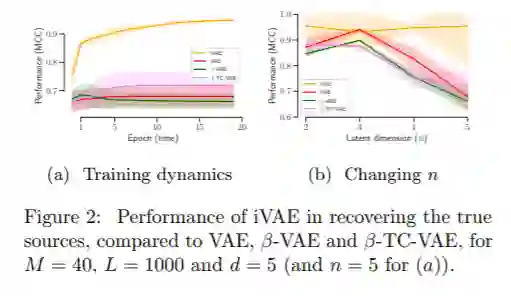
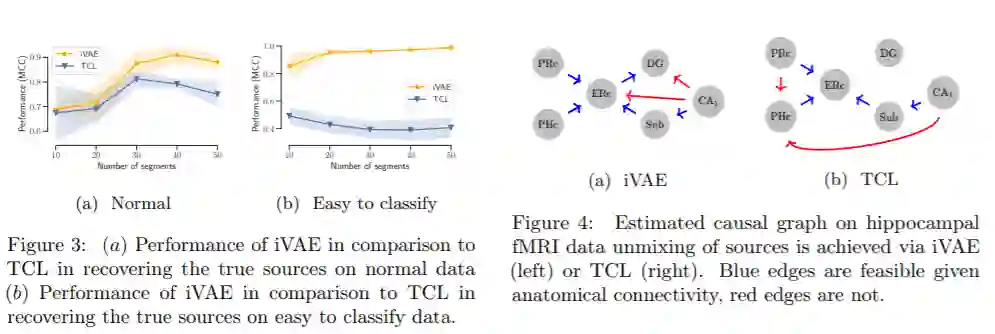
相关内容
专知会员服务
74+阅读 · 2019年11月20日
专知会员服务
36+阅读 · 2019年11月12日
Arxiv
7+阅读 · 2019年10月8日
相关主题



相关VIP内容
专知会员服务
74+阅读 · 2019年11月20日
专知会员服务
36+阅读 · 2019年11月12日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年10月8日