实用:用深度学习方法修复医学图像数据集
新智元编译
来源:wordpress
编译:小潘
【新智元导读】医学图像数据很难处理,经常包含旋转倒置的图像。这篇文章介绍如何利用深度学习以最小的工作量来修复医疗影像数据集,缓解目前构建医疗 AI 系统中收集和清洗数据成本大的问题。

在医学成像中,数据存储档案是基于临床假设的。不幸的是,这意味着当你想要提取一个图像时,比如一个正面的胸部x光片,你通常会获得一个存储了许多其他图像的文件夹,并且没有简单的方法来对它们加以区分。
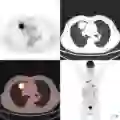
图1:这些图片来自于相同的文件夹是有道理的,因为在放射学中我们记录的是病例而非图像。这是病人受伤后,同时扫描的所有身体部位。
根据机构的不同,你可能会得到水平或垂直翻转的图像。它们可能包含反向像素值。他们可能会旋转。问题是,当处理一个巨大的数据集,比如5万到十万个图像时,你怎么能在没有医生指导的情况下发现这些畸变呢?
您可以尝试编写一些优雅的解决方案,比如:因为大多数胸部X光高度都比宽度高,因此在X光的两侧有黑色的边界,所以如果底部有超过50个黑色的像素行,那么它可能旋转了90度。
但和往常一样,我们的经验失败了。
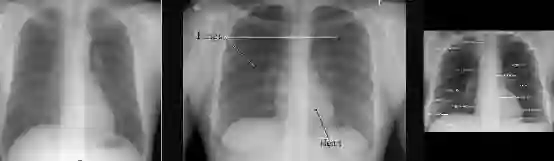
图2:这里只有中间的图像有经典的“黑色边框”
这些脆弱的规则不能解决上述问题。
进入software 2.0,我们使用机器学习来构建我们无法自行编码的解决方案。像旋转的图像这样的问题是embarrassingly learnable。这意味着机器可以像人类一样完美地实现这些任务。
因此,显而易见的解决办法是使用深度学习来为我们修复数据集。在这篇文章中,我将向您展示这些技术的可应用领域,如何用最少的努力做到这一点,并展示一些使用方法的示例。举个例子,我将使用Wang等人开发的CXR14数据集,它看起来是经过精心策划的,但有时仍然包含一些糟糕的图片。如果你使用CXR14数据集,我们甚至可以给你包含430个新标签的数据集,这样你就不用担心那些糟糕的图片了!
我们真正需要问的第一个问题是现在的问题是embarrassingly learnable么?
考虑到大多数的研究都是正常的,你需要一个非常高的精确度来防止排除那些“好“的研究。我们应该瞄准99.9%的目标。
很酷的一点是,对于视觉上可以识别的问题,它很简单,我们也可以很好地解决。一个很好的问题是“你能想象一个单一的视觉规则来解决这个问题吗?”“ImageNet数据集的主要目的就是区分区分狗和猫,而解决办法也肯定不是这样。
有太多的变化,有太多的相似之处。我经常在演讲中使用这个例子:我甚至无法想象如何编写规则来直观地区分这两种类型的动物。这并不是令人embarrassingly learnable。
但在医学数据中,许多问题其实很简单。因为医学图像的变化是很小的。解剖学、角度、光线、距离和背景都很稳定。为了说明这一点,让我们看一个来自CXR14的简单示例。在数据集中的普通胸部x光中,有一些是旋转的(这在标签中没有被识别,所以我们不知道是哪一个)。它们可以旋转90度左右,或180度的上下颠倒。
这是embarrassingly learnable么?

图3:旋转和垂直的胸部x光的区别真的非常简单
答案是肯定的。从视觉上看,异常的研究与正常的研究完全不同。你可以使用一个简单的视觉规则,比如“肩膀应该高于心脏”,你会在所有的样例上得到验证。鉴于解剖学是非常稳定的,而且所有人都有肩膀和心脏,这应该是一个可学习的卷积神经网络规则。
我们要问的第二个问题是:我们有足够的训练数据吗?
在旋转图像的情况下,我们当然有足够的数据,我们可以进行数据生成。我们所需要的只是几千个普通的胸部x光片,然后随机旋转。例如,如果你使用的是numpy数组,你可能会使用这样的函数:
def rotate(image):
rotated_image = np.rot90(image, k = np.random.choice(range(1,4)), axes = (1,2))
return rotated_image
这只是在顺时针方向旋转90 ,180度或270度。在这种情况下通常绕着第二和第三个轴旋转,因为第一个轴是通道的数量(根据theano矩阵维度的约定)。
注意:在这种情况下,CXR14数据集中几乎没有旋转的图像,所以不小心地“纠正”了已经旋转的图像的几率非常小。我们可以假设数据中没有旋转图像,这样有利于模型的学习。如果大量的不正常图像,那么你最好同时选择正常和不正常的图像。因为像旋转这样的问题很容易被识别的,我发现我可以在一个小时内给出几千个标签,所以这并不需要花费太多的精力。由于这些问题很简单,我经常发现我只需要几百个例子来“解决”这个挑战。
所以我们建立了一个正常图像的数据集,旋转其中的一半,并相应地标记它们。在我的例子中,我选择了4000个训练用例,其中2000个是旋转的,2000个验证集案例中有1000个是经过旋转处理的。这似乎是一个相当数量的数据(记住,根据经验法则,在将误差考虑在范围之内,1000个例子可能是好的,而且它适合于RAM,所以很容易在我的家用电脑上进行训练。
为了在机器学习中有一个有趣的变化,我不需要一个单独的测试集。证明在Pudding中可见:我将在整个数据集上运行这个模型,并通过对数据进行检查来获得测试结果。
总的来说,进行这类工作可以使我们的生活变得轻松。我缩小图像到256 x 256像素,因为旋转检测看起来不需要高分辨率,我使用一个经过预先训练的resnet50,它以keras作为基础网络。对于使用预先训练的网络,并没有一个明确的理由,因为几乎所有你使用的网络都会在一个简单的解决方案上得到收敛,但是它很简单,并且不会导致任何速度的减慢,因为无论如何训练时间都是快的。我使用了一组默认的参数,因为我不为这个简单的任务需要做任何调优。
您可以使用手边的任何网络和编码。一个VGG-net就行。一个densenet也可以。实际上,任何网络都是可以实现这个任务的。
在几十轮的迭代后,我在验证集上得到了我期待的结果:
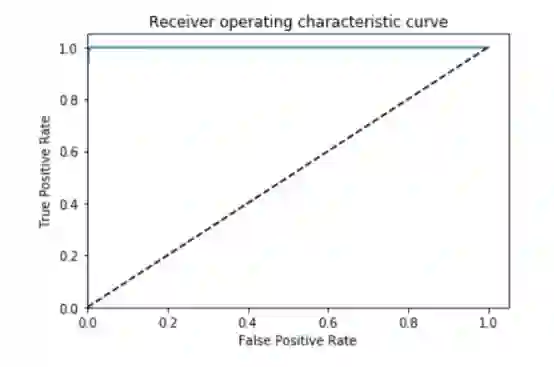
图4:AUC = 0.999, ACC = 0.996, PREC = 0.998, REC = 0.994 �
很好,如果这是一项embarrassingly learnable任务,我发现的正是我所期待的。
就像我之前说过的,在医学图像分析中,我们总是需要检查我们的结果。通过对照图片,确保模型或过程实现了你的目标。
因此,最后一步是在整个数据集上运行模型,进行预测,然后排除旋转的研究。因为在数据中几乎没有旋转的研究,尽管我知道这样做以后,召回率会非常高,我可以简单地看一下所有被预测旋转的图像。
如果这是一个有大量异常图像的问题,比方说包括了超过5%的异常数据,那么收集几百个随机的案例并手工标记一个测试集就会更有效率,然后你就可以跟踪你的模型在适当的指标上的精确度。
我特别关心的是任何被认为是旋转过的正常研究(假阳性),因为我不想失去有价值的训练案例。这实际上一个超出你想象的担忧,因为这个模型很可能会过度调用特定类型的病例(可能是那些病人懒散和倾斜时记录的病例),如果我们排除这些规则,我们将引入偏差数据,不再有“真实世界”的代表数据集。这显然对医疗数据很重要,因为我们的目标是构建能够在真正的诊所工作的系统。
该模型总共将171个案例识别为“旋转”的图像。有趣的是,它实际上是一个“异常”探测器,识别出许多实际上并没有旋转的异常情况。这是有道理的,因为它可能是在学习解剖学上的里程碑。任何不正常的东西,比如旋转的电影或其他身体部位的x光,相比较于这场模型都被标记了不同的标签。所以我们得到的结果比找到不正常旋转的图像要多得多。
在171个被选中的预测中,51个是被旋转过的前胸x光片。鉴于患病率低得离谱(120,000个中有51个),这已经是一个非常低的假正率了。
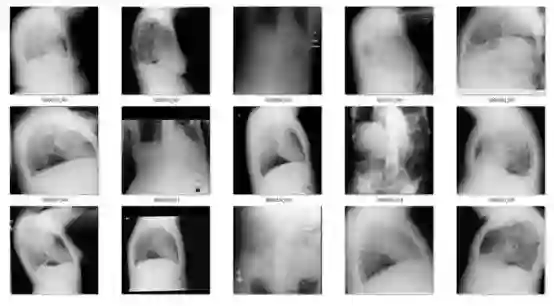
图5:旋转胸片的例子
在剩下的120个病例中,56个不是正面的胸片。主要是侧面照和腹部x光片。不管怎样,我还是想把这些都去掉。
其余的呢?有一种混合的研究,就是图像包含大量黑色或白色的边界,淘汰性研究,也就是说整个图像都是灰色的,反向像素水平的研究,等等。
总的来说,有大约10个研究,我称之为“假阳性”(意思是挑出的图像是我可能想要保存的正面x射线)。值得庆幸的是,即使你想把它们重新加起来,只有171个预测,因此容易进行人工管理。
所以旋转检测器看起来像是部分地解决了一些其他的问题(比如像素值的反转)。要知道它有多好,我们需要检查它是否漏掉了其他坏的情况。我们可以测试这个,因为像素值的反转很容易生成数据(对于图像中的x,x=max-x)。
此处需要再一次提及embarrassingly learnable问题。在这种情况下,在没有机器学习的情况下,可能有一些方法可以做到这一点(柱状图应该看起来很不一样),但这也很简单。
那么,这个特定的探测器是否发现了比旋转探测器更多的逆序呢?是的。旋转探测器在整个数据集中发现了4个,而反演探测器发现了38个反向研究。所以旋转探测器只发现了部分差的研究。
书归正传:训练单个模型来解决每个问题是正确的方法。
所以,我们需要特定的模型来完成额外的数据清洗任务。
为了证明少量的标签数据是有用的,我使用旋转检测器(n=56)拍摄了横向和不良区域的影片,并在它们上面训练了一个新模型。由于我没有很多数据,我决定用HOG wild,并且不使用验证集。由于这些任务是embarrassingly learnable,一旦它接近100%,它的泛化能力会有很好的表现。显然这里有过度训练的风险,但我仍然选择冒险。
实验证明结果非常好!我还发现了另外几百个侧面图像,腹部图像和一些骨盆的图像。
显然,如果我从头开始构建这个数据集,它解决这个问题会更容易,因为我可以获得很多相关的非正面胸部图像。对我来说,要比现在做得更好,我需要从我当地的医院档案中提取出一系列的图像,这超出了这篇文章的论述范围。所以我不能确定我取得了大部分的成就,但是从这样一个小的数据集里,这是一个相当不错的努力。
除了关于CXR14的数据外,我注意到的一件事是,我的模型在儿童的图像上的表现很差。这些儿科图像在外观上与成人图像是不同的,它们被旋转探测器、倒置探测器和bad-部分探测器识别为“异常”。我建议他们应该被忽略,但是随着病人年龄被包含在标签中,这样就可以在没有深入学习的情况下完成。考虑到在5岁以下的数据集中,只有286个病人,我个人会把所有的病人排除在外,除非我特别想要研究那个年龄段的病人并且真正知道我在做什么,从医学成像的角度来看。实际上,我可能会把所有10岁以下的人排除在外,因为这是一个合理的年龄,可以考虑到体型和病理特征更“成熟”。在10岁以下的人群中,约有1400例,约占1%。
书归正传:
小儿胸部X光与成人非常不同。考虑到低于10岁的数据只占大约1%的数据,除非有很好的理由,否则应该排除它们。
糟糕的定位和放大的图像可能会成为一个问题,但这是取决任务的,武断地定义一个“坏图像”对于所有任务来说都是不可能的,这不是我想做的。还有一件事是特定于任务的。
总的来说,使用深度学习来解决简单的数据清理问题效果很好。 经过大约一个小时的时间,我已经清理了数据集中大部分旋转和倒置的图像。我可能已经确定了很大一部分的横向图像和其他身体部位的图像,虽然我确信我需要为他们建立特定的探测器。如果没有原始数据,这对于这篇简单博客来说太长了。
从更广泛的角度来看CXR14数据,它没有太多的图像错误。美国国家卫生研究院的团队很好地整理了他们的数据。然而在医疗数据集里,情况并非总是如此,如果你想要建立高性能的医疗人工智能系统,就一定需要利用临床基础设施来处理研究任务的噪音。
到目前为止,我们已经解决了一些非常简单的挑战,但并不是我们在医学成像中遇到的所有问题都这么简单。
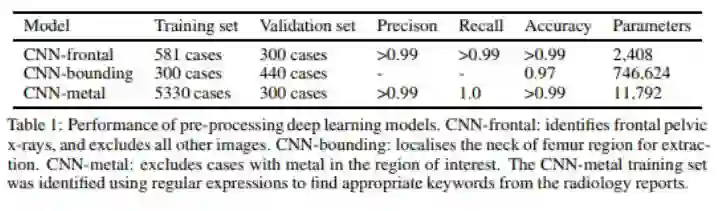
我们的团队在构建大型髋部骨折数据集时应用了这些技术。我们排除了来自其他身体区域的图像,我们排除了植入金属的病例,如髋关节置换,我们还放大了臀部区域,删除了与我们的问题无关的图像区域,如髋部骨折不发生在臀部的情况。
我们是通过一个自动文本挖掘过程来实现金属排除的问题的,这些假肢几乎总是在出现的同时被发现,所以我发现了与植入物有关的关键字。这些标签是在10分钟左右被创建的。
在身体部分的错误检测和错误的边界框预测的情况下,我们没有办法自动生成标签。所以直接进行手工处理。即使是像边界框预测这样复杂的东西(这确实是一个解剖学上的里程碑式的鉴定任务),我们只需要大约750个案例,每个数据集只花了一个小时左右的时间。
在这种情况下,我们使用人工标记的测试集来对结果进行量化。从我们的一篇论文中:
考虑到对骨折问题的标记需要几个月的时间,花费额外的一个或两个小时来获得一个干净的数据集是一个很小的代价。而且该系统现在可以接受任何临床图像,并且通过利用我们的知识可以自动排除无关或低质量的图像。这正是一个医学人工智能系统如何在现实应用的案例,除非你想雇一个人来为你处理模型所分析的所有图像。
我们都认为深度神经网络和人类解决视觉问题一样好,只要有足够的数据。然而, “足够的数据”在很大程度上取决于任务的难度。
对于医学图像分析问题的一个分支,它是我们在构建医学数据集时经常需要解决的问题,任务非常简单,这使得问题很容易用少量的数据来解决。通常,模型只需要不到一个小时的时间来识别图像,而医生却需要花费几个小时的时间来对每个数据集进行人工处理。
作为该方法的证明并用于感谢阅读我博客的读者,我已经提供了一组约430张不良图像的标签,以排除CXR14数据集,并建议排除约1400名10岁以下儿童,除非你真的知道你为什么要保留这些数据。这不会改变任何论文的结果,但这些数据集的图像清晰度越高越好。
我在这里所展示的结论没有任何技术上的创新,这就是为什么我不写一篇相关的正式论文的原因。但对于我们这些正在构建新数据集的人,特别是那些没有深度学习经验的医生,我希望这可能会引发一些关于软件2.0如何能够以数量级的方式解决您的数据问题的想法,因为它比手动方法更省力。目前构建令人惊叹的医疗AI系统的主要障碍是收集和清理数据的巨大成本,在这种情况下,深度神经网络确实没太大的用处。
我在Windows文件资源管理器中检查了我所有的图像!
我在这个博客文章的结尾附加了我的地址,我在我的空间中进行旋转探测器的预测。
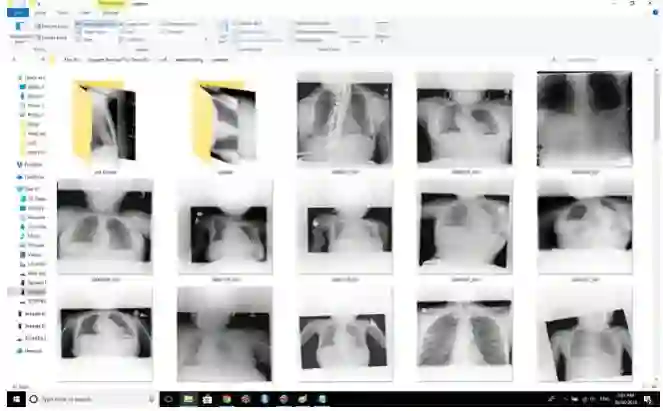
我只是将我想要看到的案例转移到一个新文件夹,然后打开文件夹(使用“超大图标”的视图模式)。这种尺寸的图像大约是屏幕高度的四分之一,而且在大多数屏幕上都大到可以检测到旋转等大的异常。当我用大的异常标记图像时,我只是按下ctrl键点击文件夹中的所有例子,然后将它们剪切/粘贴到一个新文件夹中。这就是我如何做到每小时1000个数据处理的的秘密。
就像这个系统的janky一样,它比我从网上的repos或自己编写的大多数东西都要好得多。
用于移动文件的python代码非常简单,但在构建数据时是我最常用的代码,所以我想我应该包括它:
pos = rotation_labs[rotation_labs[‘Preds’] > 0.5]
在这种情况下,rotationlabs是一个panda 的dataframe,它存储图像索引/文件名和该案例的模型预测。我把它的子集变成了一个只有正例的dataframe。
for i in pos[‘Index’]:
fname = “F:/cxr8/chest xrays/images/” + i
shutil.copy(fname, “F:/cxr8/data building/rotation/”)
所有这些都是将相关的图像复制到我所做的一个名为“rotation”的文件夹中。
然后我就可以去那个文件夹看一看。如果我做了一些手工管理,想要把这些图像重新读出来,那么它就很简单了:
new_list = os.listdir(“F:/cxr8/data building/rotation/”)
William Gale是我在这方面的杰出合著者。他成功地在本科毕业后获得了微软的一个ML研究职位,现在主要集中在语言问题上。他是值得关注的。
我知道我曾承诺过要在一段时间内修复这些标签,但这只是因为我的博士学位而被搁置了。实际上我一直在研究数据的重新定义,所以请关注这个博客。