极大提升合成速度,百度提出首个全并行语音合成模型ParaNet
选自arXiv
作者:Kainan Peng、Wei Ping、Zhao Song、Kexin Zhao
机器之心编译
参与:淑婷
当前所有基于神经网络的语音合成模型都依赖于自回归,或者循环神经网络,而百度最近提出了一种依赖于非自回归的全并行模型。该模型在合成速度和语音质量方面都有很大的提升。
语音合成(Text-to-Speech, TTS)在智能家居、内容创作、人机交互领域有着广泛应用。百度研究院最近提出了语音合成领域首个全并行模型 (Parallel Neural Text-to-Speech)。该模型直接采用前馈神经网络 (Feedforward Neural Network),不依赖于任何自回归神经网络 (autoregressive neural network) 或者循环神经网络,从文本生成音频波形仅需一次前馈传递(feed-forward pass),大大提升了合成速度。
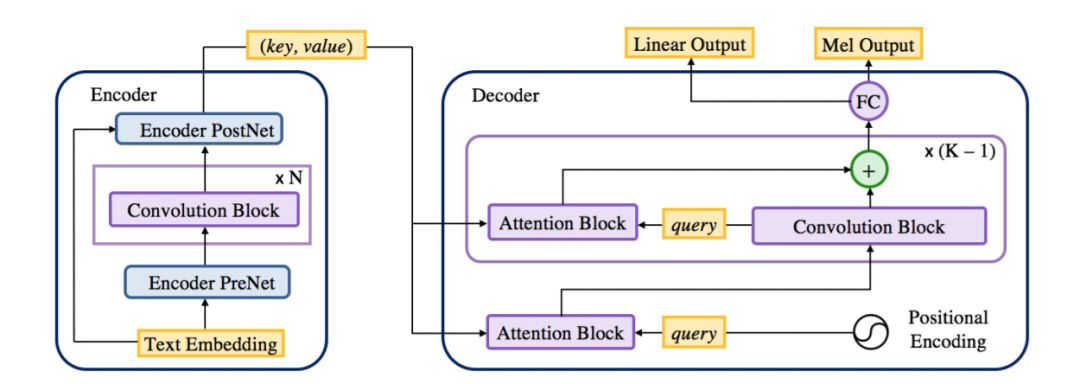
图 2:ParaNet 架构。它的编码器提供 key 和 value 作为文本表征。解码器中的第一个注意力模块将位置编码(positional encoding)作为查询,接下去是非因果卷积模块和注意力模块。
论文:Parallel Neural Text-to-Speech

论文地址:https://arxiv.org/pdf/1905.08459.pdf
基于自回归神经网络的 TTS 模型有哪些不足?
目前,所有基于神经网络的语音合成模型都依赖于自回归,或者循环神经网络。所谓自回归是指,要生成当前数据点,必须生成时间序列里前面的所有数据点作为模型输入。
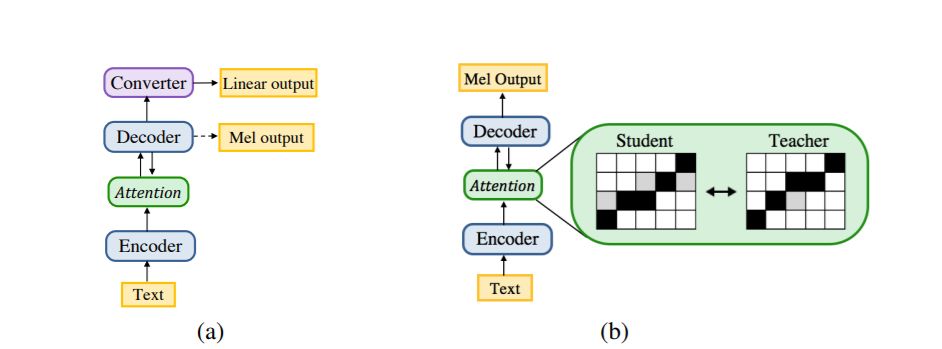
图 1:a) 自回归序列到序列模型。虚线描绘了推理时 mel 频谱的解码。b) 非自回归的 ParaNet 模型,它从预训练的自回归模型中提取注意力。
不论是 Google 提出的基于 RNN 的语音合成模型 Tacotron,还是百度之前提出的全卷积模型 Deep Voice 3,都是以自回归的方式将文本转换为频谱(spectrogram),然后再通过音频波形生成模型(声码器)从频谱生成音频原始波形(raw audio waveform)。这些模型只能按时间顺序逐帧生成频谱,导致其合成速度缓慢。
本文的全并行模型具有哪些优势?
百度研究院最新提出的全并行语音合成模型 ParaNet 打破了自回归合成的限制,一次前馈传导即可生成全部频谱。ParaNet 采用编码器-解码器(Encoder-Decoder)框架以及逐层优化的注意力机制,在保证合成语音自然度的前提下,合成速度较全卷积的自回归模型提升了 17.5 倍。
值得注意的是,在长难句的合成过程中,ParaNet 提供了更为稳定的文本与频谱之间的对齐关系(alignment),减少了重复词,跳词、以及错误发音,相比于自回归模型有更高的鲁棒性。
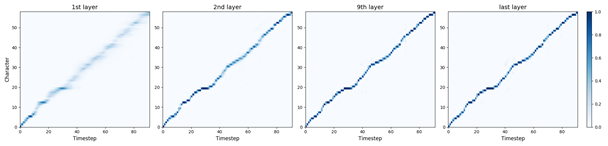
图 3:ParaNet 采用逐层优化的注意力机制,注意力对齐一层比一层更加精确
与此同时,该工作还提出了一种并行音频波形生成模型 WaveVAE。它基于变分自编码器框架,采用逆自回归流(inverse autoregressive flow, IAF)作为 VAE 的解码器,可以完全并行地合成频谱所对应的原始音频波形。
相比于传统的自回归的波形生成模型 WaveNet,WaveVAE 可以千倍的提升合成速度。相较于其他基于逆自回归流的并行波形生成模型,比如 Google DeepMind 提出的 Parallel WaveNet 和百度之前提出的 ClariNet,WaveVAE 的编码器-解码器模块无须进行任何预训练和概率分布蒸馏(probability density distillation),大大简化了训练难度。
本文主要贡献如下:
本文提出首个基于注意力的非自回归 TTS 架构 ParaNet,它是全卷积的,能够直接将文本转换为 mel 频谱。该模型以逐层的方式迭代地细化文本和频谱之间的注意力对齐。
本文在语音质量、合成速度和注意力稳定性方面将非自回归 ParaNet 和基于自回归的模型 (Ping et al., 2018) 进行了对比。在合成速度方面,该模型相比 Deep Voice 3 (DV3) 提高了 17.5 倍,同时使用 WaveNet 声码器保持了相当的语音质量。而且与 DV3 相比,非自回归 ParaNet 在具有挑战性的测试句子中产生的注意力误差更少。
本文通过结合非自回归 ParaNet 和基于神经声码器 (Ping et al., 2019) 的逆自回归流(IAF)(Kingma et al., 2016),构建了首个全并行模型。它通过一次前馈传递就能将文本转换为语音。
此外,本文还探索了另一种方法——WaveVAE,用来训练作为波形样本生成模型的 IAF。与概率密度蒸馏方法 (van den Oord et al., 2018; Ping et al., 2019) 相比,WaveVAE 可以在变分自编码器框架 (Kingma and Welling, 2014) 中使用 IAF 作为解码器从零开始训练。
本文方法:非自回归的序列到序列模型
本文提出的全并行模型由两部分组成:一个前馈文本-频谱模型和一个基于频谱的并行波形合成器。
非自回归架构
本文提出的非自回归 ParaNet 使用的编码器架构与自回归模型相同。ParaNet 的解码器仅依赖于编码器的隐藏表征,以前馈的方式预测对数 mel 频谱的整个序列。因此,它的训练与合成可以并行完成。具体来说,从自回归序列到序列模型至非自回归模型,研究者做了以下主要架构修改:
非自回归解码器:没有了自回归生成的约束,解码器可以使用非因果卷积块来利用未来的上下文信息并提升模型性能。除对数 mel 频谱外,它还用 l_1 函数预测对数-线性频谱,以获得更好的性能。
无转换器:由于用了非因果解码器,非自回归模型移除了非因果转换器。注意,在 DV3 中引入非因果转换器的主要目的是为了基于非因果卷积 (Ping et al., 2018) 提供的双向上下文信息来细化解码器预测。
注意力机制
对非自回归模型来说,学习输入文本和输出频谱之间的精确对齐有点难度。之前的非自回归解码器依赖于外部的对齐系统 (Gu et al., 2018),或者自回归的隐变量模型 (Kaiser et al., 2018)。
在本文中,研究者展示了几种简单但有效的技术方法,可以通过多步注意力 (Gehring et al., 2017) 获得精确而稳定的对齐。其非自回归解码器能够以逐层的方式迭代地细化文本和 mel 频谱之间的注意力对齐,如图 3 所示。
特别是,该非自回归解码器采用了点积注意力机制,包含 k 个注意力模块(见图 2),其中每个注意力模块使用来自卷积块的每步长查询向量和来自编码器的每步长关键向量来计算注意力权重 (Ping et al., 2018)。
然后,注意力块计算上下文向量作为来自编码器的值向量的加权平均值。解码器从注意力块开始,其中查询向量仅位置编码。接下来,第一个注意力块在下一个基于注意力的层上为卷积块提供输入。
实验
本文提出了几个实验来评估该方法。在实验中,研究者使用了一个内部英语语音数据集,该数据集包含来自一位女性说话者大约 20 个小时的语音数据,采样速率为 48 kHz。研究者把该音频将音频降采样为 24 kHz。
基于 IAF 的波形合成
研究者首先对比了两种基于 IAF 的波形合成训练方法:ClariNet 和 WaveVAE。他们在 ClariNet(Ping et al., 2019) 中使用了相同的 IAF 架构。它由 4 个堆叠的高斯 IAF 块(分别由 [10, 10, 10, 30] 层 WaveNet 参数化)、64 个 residual & skip 通道以及 3 个空洞卷积滤波器组成。
IAF 以对数 mel 频谱为条件,如 ClariNet 一样有两层转置的 2D 卷积。研究者使用与 ClariNet 相同的教师-学生设置,训练 20 层高斯自回归 WaveNet 作为教师模型。至于 WaveVAE 中的编码器,也使用了以对数 mel 频谱为条件的 20 层高斯 WaveNet。
需要注意的是,WaveNet 的编码器和解码器共享同一个调节器网络。对于两种方法,研究者都使用了 100 万步的 Adam 优化器。初始学习率设置为 0.001,每 20 万步退火一半。
TTS
接下来,研究者评估了文本到频谱的 ParaNet 模型、并行神经 TTS 系统以及基于 IAF 的声码器(包括 ClariNet 和 WaveVAE)。他们使用了 Ping 等人 (2018) 引入的字符和音素的混合表征。自回归模型和非自回归 ParaNet 模型的所有参数都在附录 A 中可见。
研究者发现,更大的内核宽度和更深的网络层通常有助于提升语音质量。在参数数量方面,其非自回归模型比自回归模型大了 2.57 倍,但它在合成语音方面有显著的加速。

表 2:附录 B 给出了文本到频谱模型在 100-sentence 测试集上的注意力误差统计。一个或多个错误发音、跳词和重复词被记为每次表达的单个错误。简单起见,所有模型使用 Griffin-Lim(Griffin and Lim, 1984) 作为声码器。在合成过程中,具有注意力掩码的非自回归 ParaNet 获得的注意力误差最少。非自回归的 ParaNet 获得的注意力误差最少。

表 3:平均意见得分(MOS),95% 置信区间用于比较。本文使用了 crowdMOS 工具包,如表 1 所示。

合成语音样例:https://parallel-neural-tts-demo.github.io/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


