数据集更大、训练速度更快,Facebook改善机器翻译的秘诀有哪些?
编者按:机器翻译是人工智能在实际应用中的一个重要领域。在这篇文章中,Facebook的研究人员们展示了他们是如何让机器翻译速度变快,同时又能扩展应用的方法。
我们希望,用户能用自己的母语体验他们的产品,从而将全世界各地的用户联系起来。为了这一目的,我们用神经机器翻译(NMT)自动翻译文章和评论的文字。此前有关这项工作的成果已经在fairseq上开源,这是一种序列到序列的学习库,可以让任何人训练NMT、进行文本摘要总结或者其他文本生成任务。
随着NMT在学习大型单一语种数据上的能力逐渐提高,追求更快的训练速度成为了研究重点。为了这一目的,我们必须找到一种方法能显著减少训练时间。直到目前,在一台机器上训练这种类型的NMT模型都需要好几周时间,这种速度显然比较慢。
现在,经过对模型精确度和训练设置的多种改变,我们可以在32分钟内训练一个强大的NMT模型,速度比之前快了45倍。论文地址:arxiv.org/abs/1808.09381

加速训练
首先,我们的重点在如何减少模型的训练时间,最终仅用了一个NVIDIA DGX-1和8个Volta GPUs就将之前将近24个小时的训练时间减少到了5小时以下。神经网络通常含有数百万个参数,可以在训练时进行调整。这些参数通常会储存在32位浮点数中。第一步,我们将训练从32位转换成16位,从而减少GPU内存,并且能使用经过优化的NVIDIA Tensor Cores。用精度降低的浮点训练有时会导致模型质量的降低,因为浮点的“溢出”。在我们的工作中,我们应用了一种常见的用于自动检测和放置过载的技术,将训练时间减少到了8.25个小时,速度快了2.9倍并且没有使模型质量损失。
接下来,我们通过所谓的“累积更新(cumulative upgrade)”来延迟模型的更新。我们对模型进行同步训练,从而每个GPU保留着和模型一样的副本,但处理训练数据不同的部分。处理需要反向传播,反向传播在网络上分为前向传递和后向传递,以计算训练模型所需的统计数据。处理完每个mini-batch后,GPU会将结果(梯度)同步互相传递。这种方法会导致潜在的低效:首先,在GPU之间传输数据会消耗时间;第二,速度快的单元要等待速度慢的单元才能继续训练。
后者是文本处理模型一个重要的挑战,不同长度的句子会让问题更严重,这一点在计算机视觉领域是体会不到的,因为训练的图像通常大小相同。针对上面提到的两个问题,我们的解决方法是拖延同步点,将多个mini-batch的结果聚集起来再传播到各个处理单元中。这将训练时间减少到了7.5个小时,没有损失模型质量。
累积更新同样增加了高效训练的量,或者用于每个步骤训练的数据。在我们的设置中,batch的大小增加了16倍,这是我们将学习率提高了一倍,从而让训练时间减少到了5.2小时。
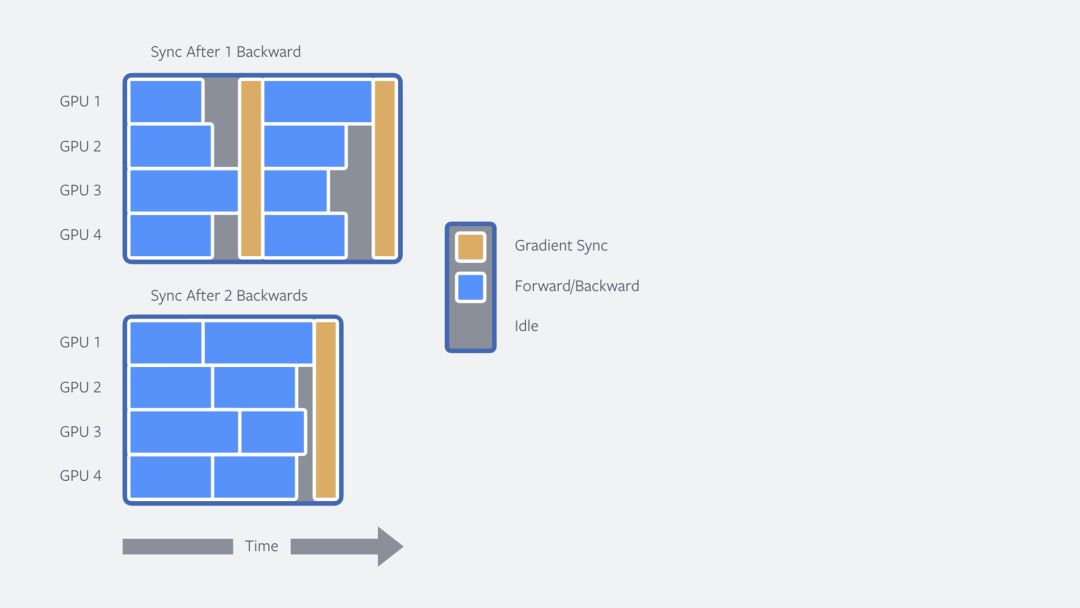
在多个步骤间进行梯度聚集
最终,我们用多余的GPU内存进一步扩大了batch的大小。通过将每个处理单元从原来的3500单词增加到5000个单词,我们能将整体的训练时间减少到4.9小时,是原来的4.9倍。
在多个机器上训练
我们在单一机器上的训练优化同样可以应用在多机器训练中(即分布式训练)。将原本在单独DGX-1机器上的训练扩展到16个机器上时(有128个GPU),我们发现只需37分钟就能训练相同的模型,这是原来的38.6倍。
在多个机器上训练时,另一种优化会使GPU交流和反向传递重叠。反向传递之后,我们获得了在其他处理单元中交流所需要的信息。通常来说,反向和交流是接连出现的,但是我们可以让二者重叠从而节省时间。特别的,我们可以当反向步骤一在某个神经网络的子集中完成,就在多个处理单元中对梯度进行同步。GPU交流之后就会和反向传递重合。这就进一步减少了训练时间,即达到了32分钟。
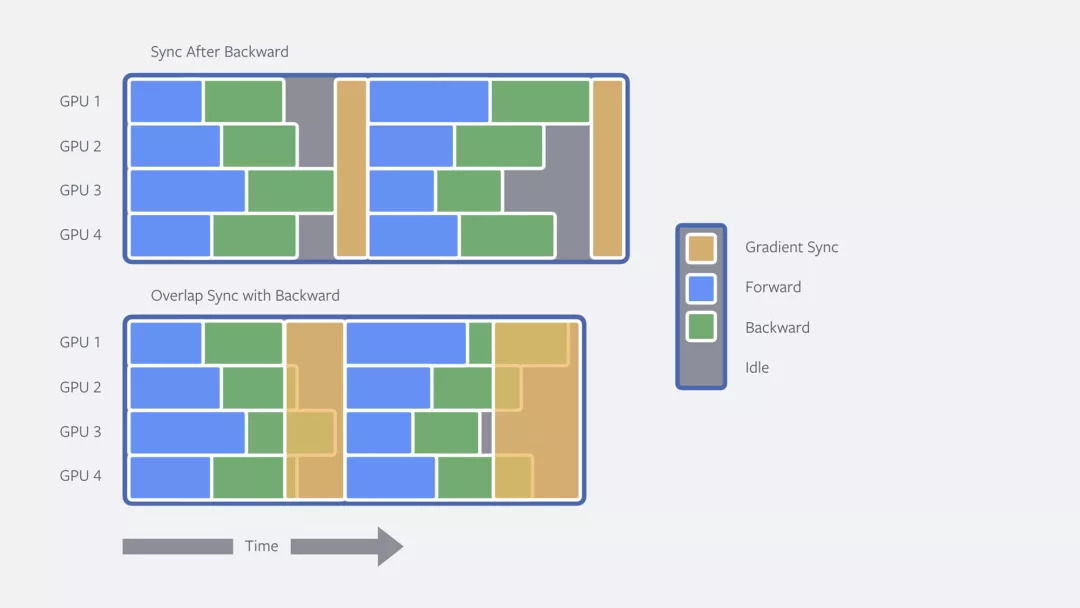
反向传播中的反向传递(back pass)可以和梯度同步重叠进行,从而提高训练速度
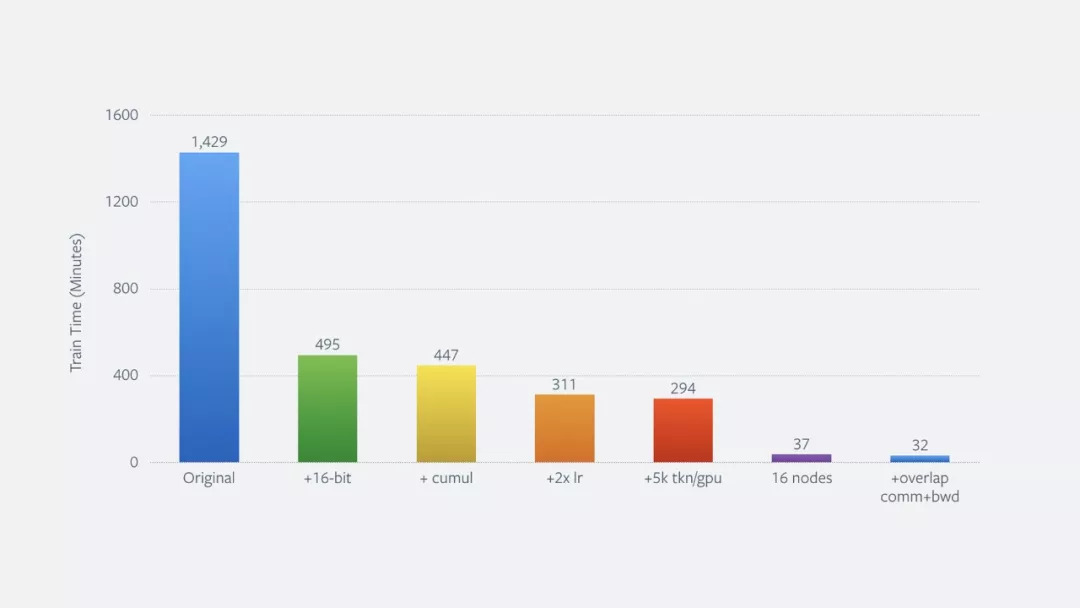
每次模型优化后训练时间的减少
在更多未翻译的数据上训练
将模型的训练时间缩短后,我们又开始研究如何训练模型在更大的数据集上工作。通常来讲,训练NMT模型需要有对应翻译版本的数据,即双语数据。但是这种资源十分有限,可用数据大多只有一种语言。在我们的第二篇论文中(地址:arxiv.org/abs/1808.09381),我们展示了如何让模型在这种情况下工作,同时用大量数据训练可以让精确度有所提升。
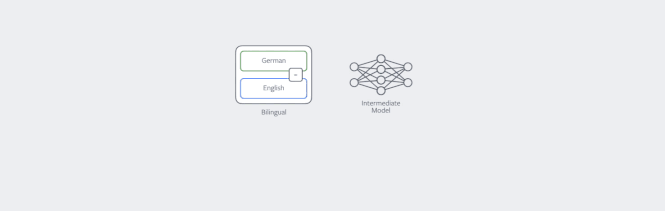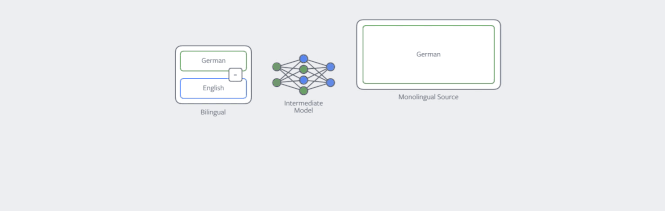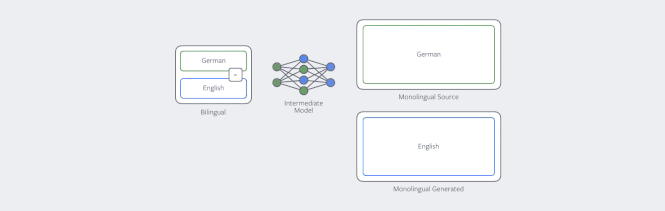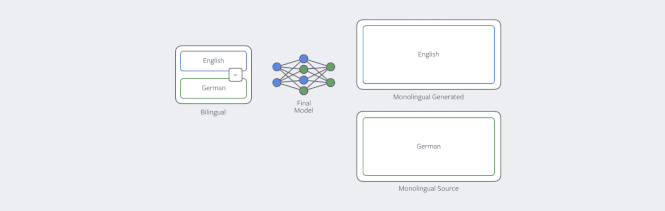
其中提高NMT在单一语言数据上效率的技术之一就是反向翻译(back-translation)。如果我们的目的是训练一个英译德的翻译模型,那么我们首先要训练一个德译英的模型,然后用它来训练所有单一德语的数据。之后把英译德模型在现有和新数据上进行训练。我们的论文表明,数据如何翻译是很重要的,在采样过程中并不总是选择最佳翻译版本是很有用的。
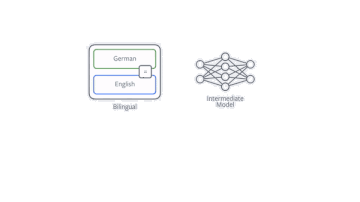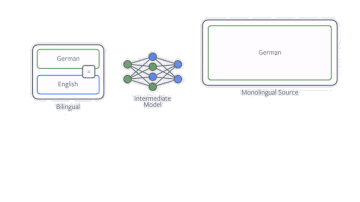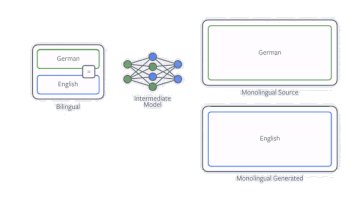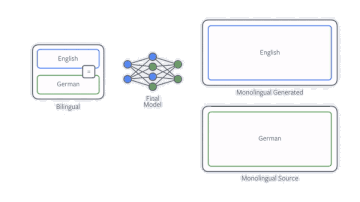
反向翻译过程
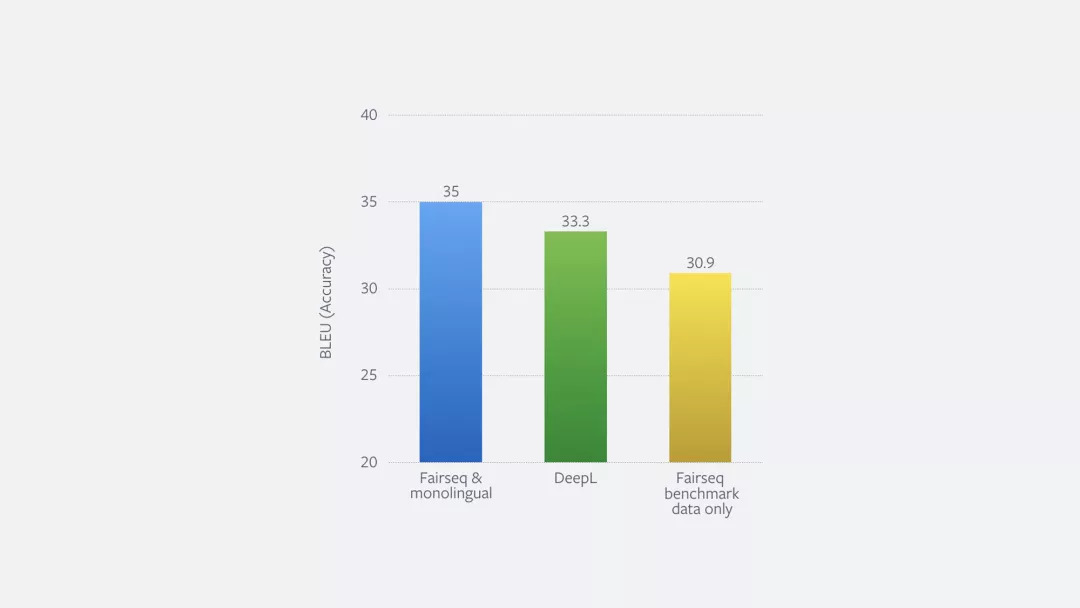
如果我们在现有的500万条句子中加入2.26亿条反向翻译的句子,那么模型翻译质量会得到显著提高。下方的表格就展示了系统的精确度在不同数据上的表现。
更快的翻译
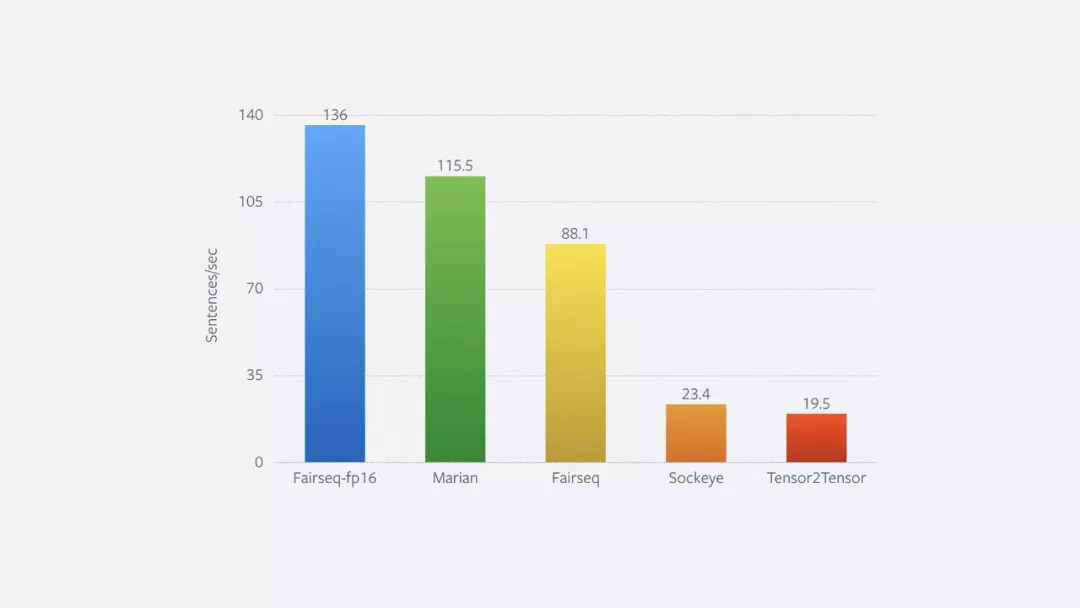
我们同样改善了翻译速度,模型一经训练好,fairseq就能翻译出来。尤其是我们使用了智能缓存,或者从计算中算出了一经完成的句子,并且分批处理单词数量而不是句子。这将翻译速度提高了将近60%。下方图表就展示了各种方法的对比。
结语
继续提升自动翻译技术仍然是我们的研究重点,希望未来有更多发现能让训练速度更快,这样就可以推动实验的迭代次数,让NMT模型的发展更快。我们还希望未来能用无标记数据解决翻译之外的问题,例如问答或文本总结。
地址:code.fb.com/ai-research/scaling-neural-machine-translation-to-bigger-data-sets-with-faster-training-and-inference/






