ACL 2018最佳论文公布!计算语言学最前沿研究都在这了

来源:acl2018.org、新智元
国际计算语言学协会 (ACL,The Association for Computational Linguistics),是世界上影响力最大、最具活力的国际学术组织之一,其会员遍布世界各地。ACL 会议是计算语言学领域的首要会议,广泛涉及自然语言的计算方法及其各类研究领域。计算语言学协会第56届年会,也即ACL 2018,将于7月15日至20日在澳大利亚墨尔本墨尔本会展中心举行。
昨天,ACL官网公布了本届大会的最佳论文,包括3篇长论文和2篇短论文。
Best Long Papers
Finding syntax in human encephalography with beam search. John Hale, Chris Dyer, Adhiguna Kuncoro and Jonathan Brennan.
Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information. Sudha Rao and Hal Daumé III.
Let’s do it “again”: A First Computational Approach to Detecting Adverbial Presupposition Triggers. Andre Cianflone, Yulan Feng, Jad Kabbara and Jackie Chi Kit Cheung.
Best Short Papers
Know What You Don’t Know: Unanswerable Questions for SQuAD. Pranav Rajpurkar, Robin Jia and Percy Liang
‘Lighter’ Can Still Be Dark: Modeling Comparative Color Descriptions. Olivia Winn and Smaranda Muresan
根据ACL官网,今年的会议竞争超级激烈:一共接受了1018份长文中的258篇和526篇短篇论文中的126篇,总体接受率为24.9%。
1. Finding syntax in human encephalography with beam search.
(使用beam search在人体脑电图中查找语法)
作者:John Hale, Chris Dyer, Adhiguna Kuncoro & Jonathan Brennan.
(论文内容尚未公布)
2. Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information.
(学习提问好问题:使用完美信息的神经期望值排列澄清性问题。)
作者:Sudha Rao & Hal Daumé III
论文地址:https://arxiv.org/pdf/1805.04655.pdf

论文摘要
提问(inquiry)是沟通的基础。除非能提出问题,机器无法有效地与人类合作。在这项工作中,我们建立了一个神经网络模型来排序澄清性问题。我们的模型受到完美信息期望值(expected value of perfect information)的启发:一个问题好不好在于其预期答案是否有用。我们使用来自StackExchange的数据来研究这个问题。StackExchange是一个丰富的在线资源,人们在上面提问一些澄清式的问题,以便更好地为原始的帖子提供帮助。我们创建一个由大约77k帖子组成的数据集,其中每个帖子包含一个问题和回答。我们在500个样本的数据集上对我们的模型进行了评估,并与人类专家的判断进行对比,证明了模型在控制基线上得到重大改进。

模型在测试时的行为

回答生成器的训练
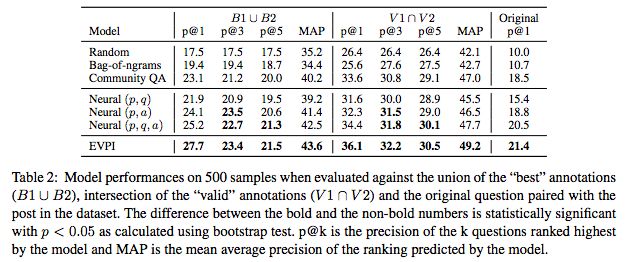
在500个样本数据集上测试的模型表现
3. Let’s do it “again”: A First Computational Approach to Detecting Adverbial Presupposition Triggers.
作者: Andre Cianflone, Yulan Feng, Jad Kabbara and Jackie Chi Kit Cheung.
论文地址:https://www.cs.mcgill.ca/~jkabba/acl2018paper.pdf

论文摘要
在这篇论文中,我们提出一个检测状语预设的触发器的任务,例如“also”或“again”这类词。解决个任务需要在话语语境中检测重复或类似的事件,可以应用在自然语言生成任务(例如总结和对话系统)任务。我们为该任务创建了两个新的数据集,数据来源于Penn Treebank和Annotated English Gigaword两个语料库,以及为此任务量身定制的新的注意力机制。我们的注意力机制增加了一个基线递归神经网络,而且不需要额外的可训练参数,从而最大限度地减少了计算成本。我们的工作证明,我们的模型在统计学上优于一些基线模型,包括基于LSTM的语言模型。

我们的数据集中一个包含预设触发器的样本
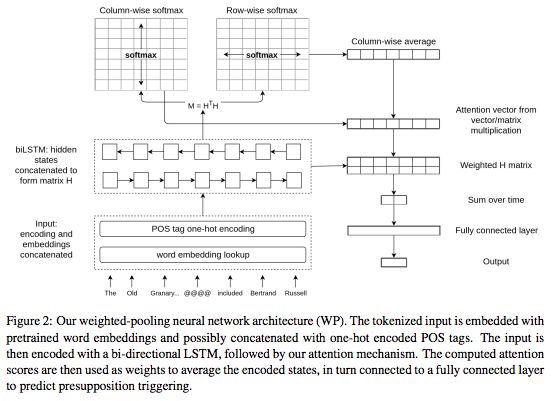
weighted-pooling神经网络架构
1. Know What You Don’t Know: Unanswerable Questions for SQuAD.
作者:Pranav Rajpurkar, Robin Jia and Percy Liang
(论文内容未公开)
2. ‘Lighter’ Can Still Be Dark: Modeling Comparative Color Descriptions.
作者:Olivia Winn and Smaranda Muresan
(论文内容未公开)
今年的ACL开设了一个“meta conference”环节,讨论双盲评审以及 ArXiv 预印版相关话题。许多研究表明,当工作的客观价值保持不变时,单盲评审会导致评审人更偏向于某些类型的研究人员。因此,所有 ACL 会议和大多数研讨会都使用双盲评审制度。而以 ArXiv 为代表的在线预印服务器的流行,在一定程度上威胁到了双盲评审过程。
上周,ACL更新了其会议论文的投稿、评审和引用政策。其中规定,为了双盲评审的有效性,禁止投稿论文在截止日期前的1个月时间内在 arXiv 等平台公开预印本。这些新要求引起一些质疑双盲评审有效性的声音,不过,多数研究人员表示支持新政。
因此,其他几篇最佳论文,可能需要等到7月份会议召开后公开。
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习





