结合符号与连接,斯坦福神经状态机冲刺视觉推理新SOTA
选自Arxiv
参与:一鸣、张倩、杜伟
符号主义和连接主义之争由来已久。尽管连接主义的代表——深度学习在近年来取得许多了重大成就,其解释性差、泛化能力低、依赖大量数据的问题广受诟病。近日,斯坦福大学研究人员提出一种结合符号主义和连接主义的模型——神经状态机(Neural State Machine),旨在抹平符号主义和连接主义之间的鸿沟,并对二者进行优势互补,从而更好地完成视觉推理任务。
在研究中,为了解决「看图问答」任务,研究人员将图像和问题同时转化为基于语义概念的表征,在一个抽象的隐空间中运行,增强了模型的透明性和模块性。

论文链接:https://arxiv.org/pdf/1907.03950.pdf
符号主义和连接主义优势互补
符号主义和连接主义是人工智能中的两大分支。符号主义 AI 也叫「基于规则的 AI」,其基本思想是将世界上的所有逻辑和知识转换为计算机编码。在符号主义 AI 中,每个问题都必须拆分为一系列的「if-else」规则或其他形式的高级软件结构。符号主义能够从丰富的感官体验中提取和传达有创意的新想法,因此这种系统的出现成为了智能进化中的一个重大转折点。
相对的,连接主义 AI 体现在机器学习和深度学习中,AI 模型通过统计比较和发现不同信息之间的关联来学习发展自己的行为。
人工智能发展早期,符号主义占据主要地位。而 20 世纪 90 年代后连接主义发展迅猛,逐渐取代了符号主义的地位。今天,连接主义的代表——深度学习取得了的很多成果。
然而,尽管利用深度学习的神经网络非常强大、灵活和鲁棒,但也有其自身的缺陷,如很难以系统化的方式实现泛化、过于依赖表面和具有潜在误导性的统计关联性而不学习真正的因果关系等。与此同时,这些鲁棒性和通用性兼备的神经网络模型具有庞大的规模和统计属性,但这些也阻碍了它们的可解释性、模块性和合理性。
因此,斯坦福大学的两位研究者提出了神经状态机(Neural State Machine),这是一种可微且基于图的模型,并且模拟自动机的操作行为。他们旨在抹平符号主义和连接主义之间的鸿沟,探索神经状态机模型在视觉推理和合成问题系统领域的应用。
神经状态机模型架构
神经状态机模型分为两个阶段:学习阶段和推理阶段。根据给定的图像,研究者首先生成了能够以紧凑结构捕获自身潜在语义知识的概率场景图。然后,他们将概率图看作状态机,并模拟其迭代计算,从而回答问题或者得出推论。
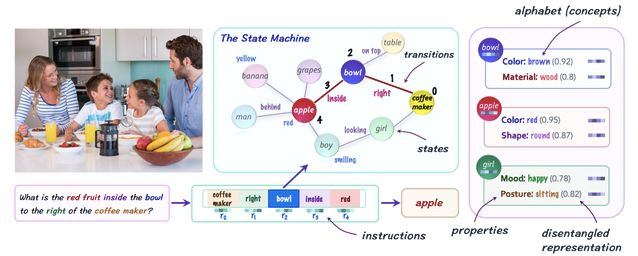
图 1:神经状态机是一个图网络模型,可以模拟机械计算。在 VQA 任务中,模型建立一个概率图,捕捉图像中的语义信息,按照问题的指导遍历其状态以执行顺序推理。
神经状态机建立分为两步:建模和推断。
建模过程中,研究人员将图像和语言建模为抽象表示。图像通过概率图表示其语义——包括图像中表示的目标、属性和关系。而问题则被转换为一个推理指令序列。
在推断阶段,研究人员将图视为状态机,节点代表图像中的目标,对应状态,而边代表目标之间的关系,对应转移(transitions)。研究人员之后启动序列计算,迭代地将从问题中提取的指示输入机器,并改变状态,使得模型可以进行语义-图像推理,并最终到达结果
概念词汇表
首先,研究者建立了状态机的嵌入概念词汇表。他们没有直接使用原始和密集的感官输入特征,而是根据建立的词汇表来表征视觉和语言输入,从而找出与它们最相关的概念。
状态和边过渡
研究者推理得出的场景图包含:(1)一组目标状态节点,每个节点附有边界框、掩码、密集视觉特征以及每一种目标属性的离散概率分布,并在概念词汇表中定义;(2)一组边,每个边与概念中的语义类型(如在... 之上、吃东西等)的概率分布相关联,并与状态机状态之间的有效过渡保持一致。接着,他们继续计算每个边的结构化嵌入表征。

图 2:推理场景图中目标掩码的可视化图。
推理指令
研究者将问题转化为一系列推理指令,这些指令之后由状态机读取并指导其计算。
研究者首先使用 GloVe(dimension d = 300)嵌入问题中的所有词(qustion word)。他们通过 tagger 函数来处理每个词,该函数要么将词转化为词汇表中最相关的概念,要么在不匹配词汇表中任何概念的情况下保持其完整性。
接下来,研究者将每个词转化为基于概念的表征。直观上看,apple 等实义词通常被认为与概念上的 apple 相似(基于它们的 GloVe 嵌入),所以它们会被该术语的嵌入取代。但是,who、are 和 how 等功能词则被认为与相应的语义概念不那么相似,所以它们会接近原始嵌入。
最后,研究者利用一个基于注意力的编码器-解码器处理归一化问题中的词。他们首先通过 LSTM 编码器传递这些词,随后推导出循环解码器,生成隐状态。此外,研究者又将问题中的每个词转化为相应的推理指令,这些指令在每个解码步骤上计算归一化问题中词的注意力。
模型模拟
首先,网络以状态(图像场景中的目标)上的统一初始分布开始,在每一个推断步骤上读取从问题中得出的指令,并利用该指令通过转移边(目标之间的关系)上的概率来重新分配在状态(目标)上的注意力。
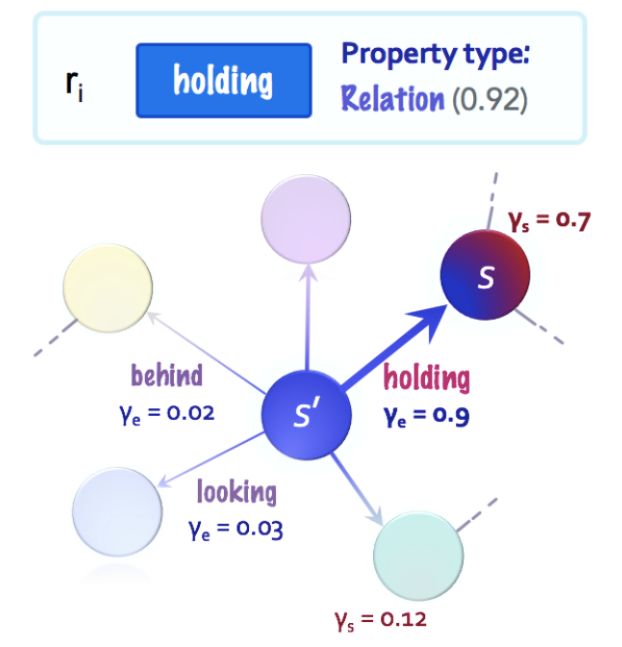
图 3:图遍历步骤的可视化,注意力正沿着最相关的边从一个节点转移到其临近节点。
研究者的目标是根据当前处理的状态确定下一个要遍历的状态。因此,首要目标是发现指令类型:与指令最相关的属性类型基本上就是找出指令的内容。
研究者还进一步为每条边分配了一个变量,该变量可以类似地表征其关系类型。一旦知道指令的内容,就能将该指令与所有的状态和边进行比较,为它们中的每个计算相关性得分(relevance score)。接下来,研究者得到了指令和每个变量之间的相关性得分。
有了节点和边的相关性得分之后,研究者将模型的注意力从现有节点(状态)转移到了与其最相关的临近节点,也就是接下来的状态。
为了预测答案,研究者使用一个标准的 2 层全连接 softmax 分类器,该分类器接收问题向量的连接以及一个额外的向量,该向量收集来自机器最终状态的信息。
实验
研究者在两个最近的 VQA 数据集——GQA 和 VQA-CP——上评估了神经状态机模型。GQA 数据集聚焦现实世界的视觉推理和组合问答;VQA-CP(version 2)专门用于测试模型在训练和测试集之间答案分布发生变化时的泛化能力。
神经状态机模型在 VQA-CP 和 GQA 的单一模型设置下都达到了当前最佳性能。
如表 1 所示,在单一模型设置下,神经状态机模型在多个指标上达到了 SOTA 性能,如准确率、一致性。
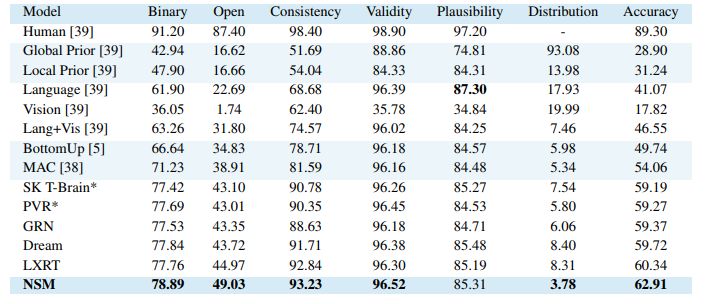
表 1:在单一模型设置下的 GQA 得分。
在 ensemble 设置下,神经状态机模型性能位列第三,如下表 2 所示。
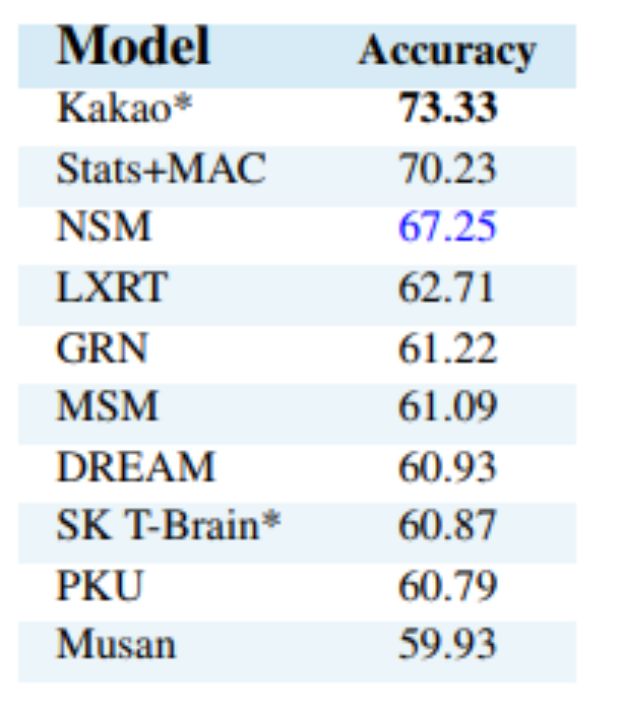
表 2:GQA ensemble
为了进一步探索神经状态机的泛化能力,研究者为 GQA 创建了两个子集,用于测试模型在问题内容和结构上的泛化能力,并基于这两个子集进行实验,展示了神经状态机模型在多个维度上强大的泛化能力。
研究者在三个维度上展开了实验:1)训练和测试集之间答案分布的变化;2)在单独学习的概念上的语境泛化;3)未见过的语法结构。
研究者首先在 VQA-CP 上测试了模型的性能,如下表 3 所示,神经状态机的性能比其他模型高出很多。
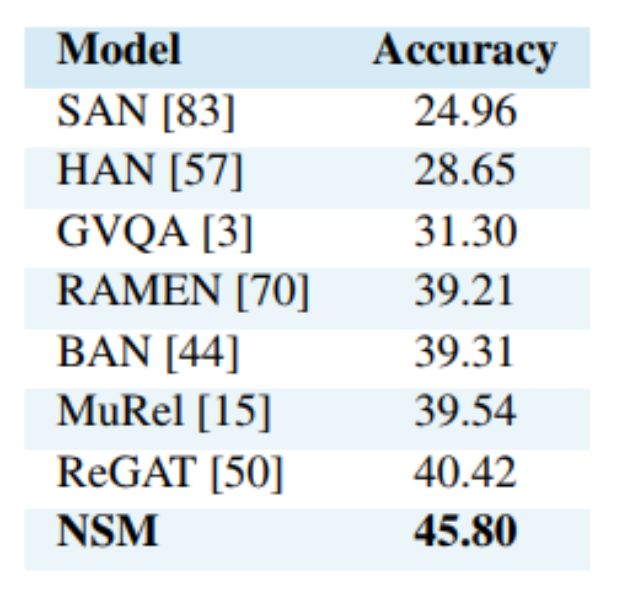
表 3: VQA-CPv2
鉴于 GQA 数据集可以提供问题中词的 grounding 注释,研究者在 GQA 上进行了进一步的泛化研究。这些注释可以让研究者将训练集分为两个有趣的方向——「内容」和「结构」,如下图 4 所示。

图 4:研究者将 GQA 数据集分为两部分,以评估模型在「内容」和「结构」上的泛化能力。「内容」:测试问题是关于新概念的;「结构」:测试问题有关未见过的语言模式。
下表 4 总结了模型在「内容」和「结构」两种设置下的结果,将神经状态机模型与已发布的 GQA 基线进行对比,所有模型都使用相同的训练方案和输入特征。
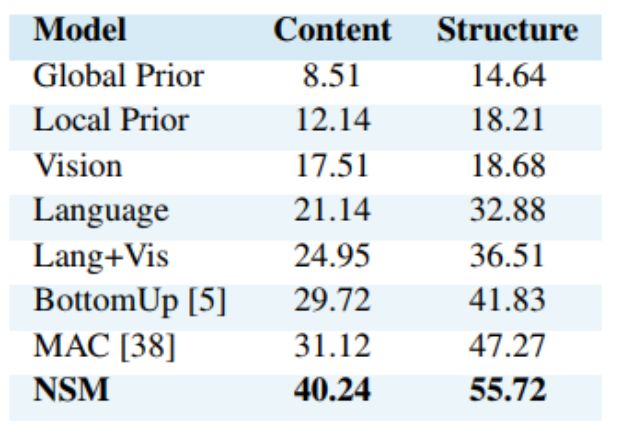
表 4:GQA 泛化。
本文为机器之心整理,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

