前沿|DeepMind:Distral新框架可用于多任务之间的同步强化学习!


在复杂的环境里,多数深度强化学习算法的数据使用效率并不高,限制了在很多场景之中的应用。解决这个问题的一个方向是通过共享神经网络参数实现多任务学习,借助关联任务之间的迁移提升数据使用的效率。实际上,这不容易被观察到,因为来自不同任务的梯度可以消极干预,使得学习不稳定,甚至效率更低。另一个问题是任务之间的不同奖励方案,这可以轻易导致一个任务主导共享模型的学习。我们提出了一种用于多任务的联合训练的新方法——Distral(提取&迁移学习)。我们没有共享不同工作站之间的参数,而是通过共享「提取的」策略捕捉任务之间的共同行为。每个工作站被训练以解决其自己的任务,同时被限制接近于共享策略,尽管共享策略是通过提取被训练从而成为所有任务策略的中心(centroid)。学习过程的两个方面都来自于优化一个联合目标函数。该方法支持复杂 3D 环境中的高效迁移,并优于多个相关方法。而且,该学习过程更鲁棒更稳定——这对深度强化学习非常关键。
新框架 Distral 可用于多任务之间的同步强化学习。图 1 是一个包含 4 个任务的图示。该方法聚焦于共享策略的理念上,它从具体任务的策略中提取(在 Bucila and Hinton et al. [5, 11] 的意义上)共同行为或表征。
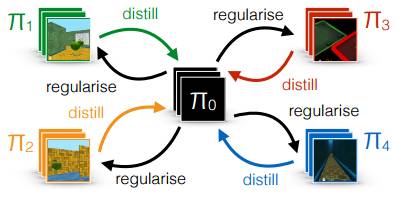
图 1: Distral 框架
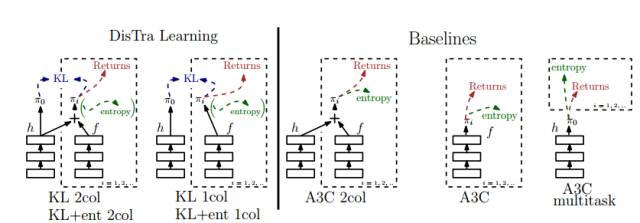
图 2: 不同算法和基线的描述。左侧是 Distral 算法中的两个,右侧是 3 个 A3C 基线。熵(entropy)在括号之内,因为它是可选择的,且只用于 KL+ent 2col 和 KL+ent 1col。
Distral 框架的算法:

表 1: 使用了 7 个不同的算法。每一列描述一个不同的架构,每列的标题指示任务策略的 logit。行定义 KL 与 熵正则化损失函数的相关量,第一行包括 A3C 基线(没有 KL 损失函数)。
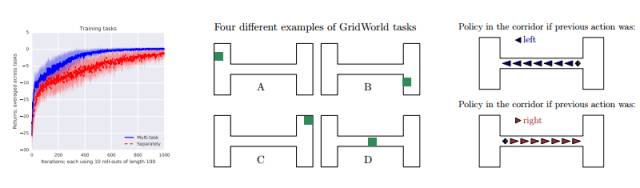
图 3: 左图:两个空间网格世界中的学习曲线。DisTraL 智能体(蓝色)学习的更快,并向更好的策略收敛,从整体上证明了更稳定的学习。中图:任务的实例。绿色代表目标位置,为了每一任务统一被采样。在每一个 episode 开始之时,开始位置统一被采样。右图:习得的提取策略 π0 只在走廊之中,并受限于之前向左/向右的行动,没有先前的奖励。箭头的大小描述行动的概率。注意向上/向下行动的概率可以忽略。模型在走廊中学习保持行进的方向。
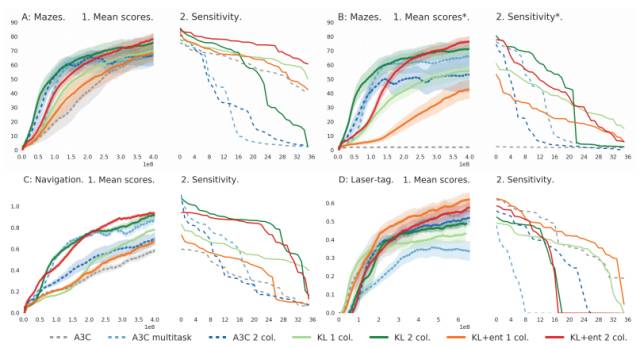
图 4:上图 A1、C1 和 D1 展示了任务具体型(分别为迷宫、导航和 laser-tag 任务)策略性能(所有任务的均值),其中这几幅图 x 轴代表每个任务训练环境步的总数。B1 图展示了由使用提取策略(distilled policies)所获得的均分值。对于每个算法,我们基于曲线下面积展示了最优超参数设定。A1、B1、C1 和 D1 中的粗线为四次运行的均值,而彩色的区域为每个任务的平均标准差。图 A2、B2、C2 和 D2 展示了每个算法 36 次运行的最终性能,并且从好到坏排序(9 个超参数设定,且运行了四次)。
实验结论
Distral:一种提取和迁移多任务强化学习中一般行为的通用框架。实验中,该算法不仅能更迅速地学习、产生更好的性能,同时还能更加稳健和鲁棒地设置超参数。我们发现 Distral 能显著地优于为多任务和迁移强化学习共享神经网络参数的标准方法。
论文:https://arxiv.org/pdf/1707.04175.pdf



