【IJCAI2020南大】上下文在神经机器翻译中的充分利用

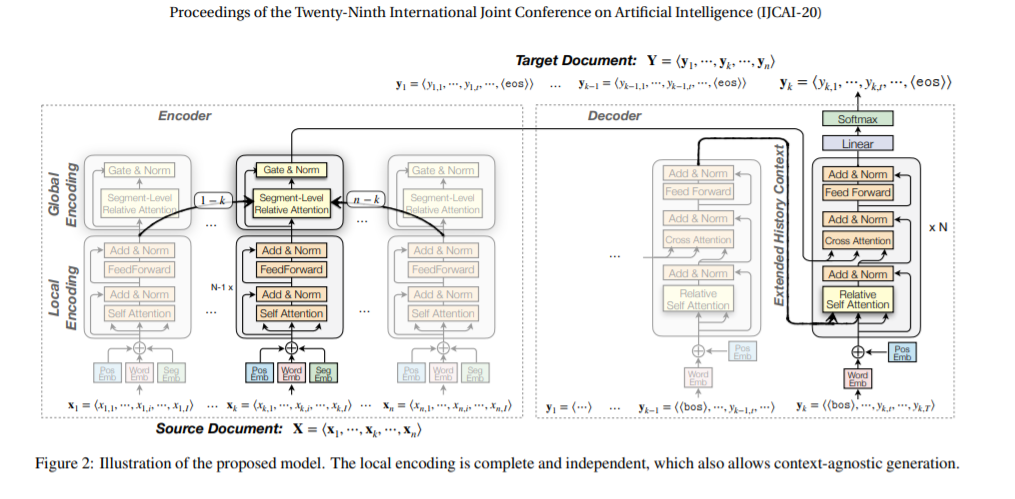
论文提出了一个文档级NMT框架,对每个句子的本地上下文、源语言和目标语言文档的全局上下文建模,能够处理包含任意数量的句子的文档,比sota baseline高2.1个BLEU score。传统文档级NMT的缺点有:不能完全利用上下文,深层使得模型对环境中的噪声更加敏感;由于深度混合hybrid需要全局文档上下文作为额外的输入,不能翻译单个句子。
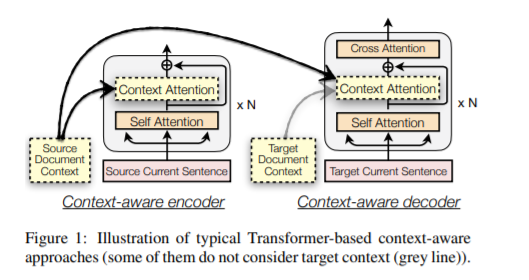
新框架在源语句中独立地编码本地上下文,而不是从一开始就将它与全局上下文混在一起,因此当全局上下文很大且有噪声时,这个框架是健壮的。此外,架构将部分生成的文档翻译作为目标全局上下文进行逐句翻译,从而允许本地上下文控制单句文档的翻译过程。
https://www.ijcai.org/Proceedings/2020/0551.pdf
参考链接:
https://blog.csdn.net/liuy9803/article/details/104654066
https://mp.weixin.qq.com/s/mRfyeHdlV5Y636jvQj5SAw
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CNMT” 可以获取《【IJCAI2020南大】上下文在神经机器翻译中的充分利用》专知下载链接索引


登录查看更多
相关内容





相关VIP内容
相关资讯