编辑:好困 LRS
【新智元导读】翻译软件翻车的案件屡见不鲜,但这次谷歌翻译的翻车却涉及「辱华」,网友怒斥谷歌夹带私货。问题披露后谷歌翻译第一时间发布公告并迅速修复,并声称此次事故要背锅的是训练语料!
大部分人使用翻译软件时,对于翻译后的语言大部分都是看不懂的,所以除了选择相信翻译后的结果,并没有其他选择。
但如果翻译结果你能看懂,并且发现他翻译错了,那。。。
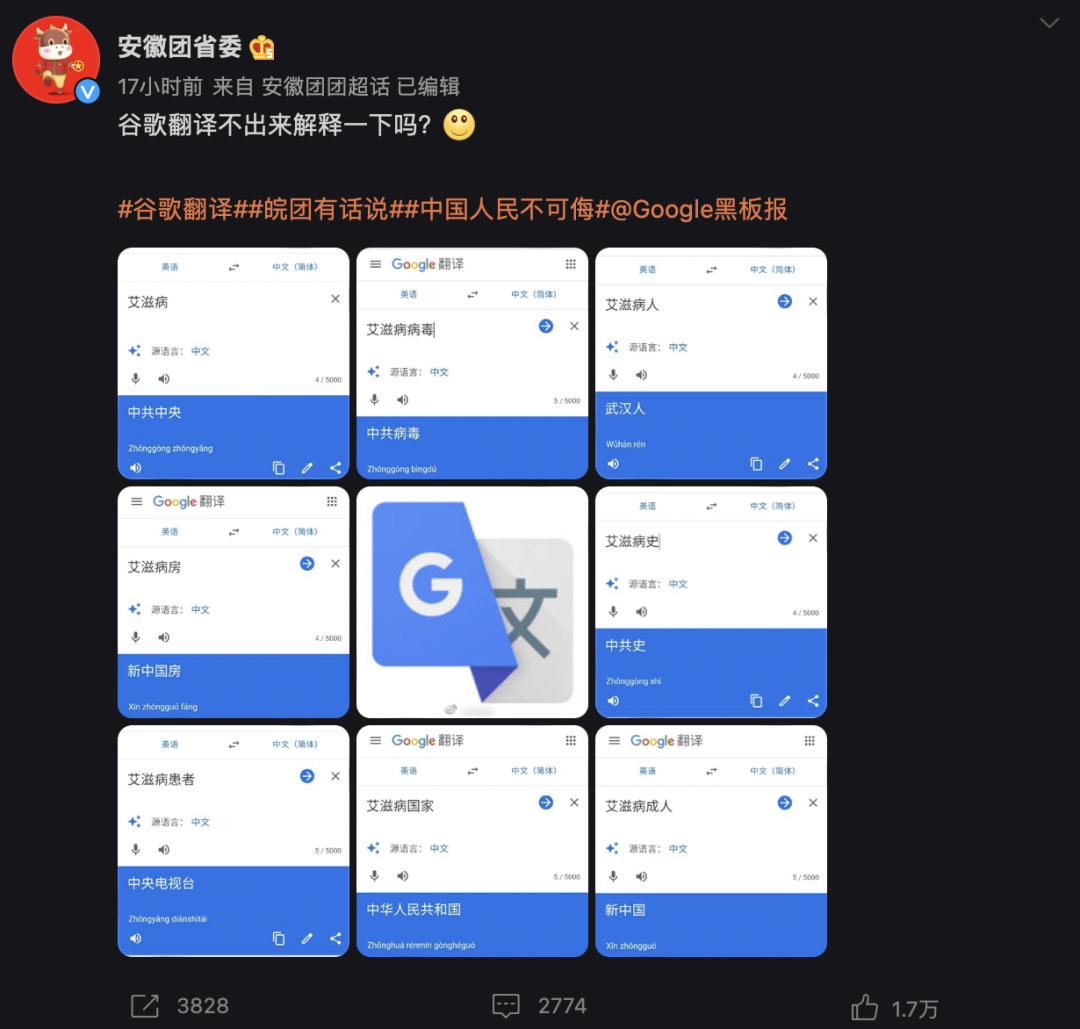
最近安徽省团委在微博上发现谷歌翻译会将一些艾滋病相关的词翻译为中国侮辱性词汇,引发网友对谷歌翻译的反感和愤怒。
在英翻中的英文对话框输入「新闻」,「传播」等词汇,中文部分显示的仍然是「新闻」和「传播」。
但在英文对话框输入「艾滋病毒」等类似词汇,中文翻译就会显示恶毒攻击中国的词汇。如输入「艾滋病人」,就会出现「武汉人」的中文翻译。
此外,在俄语对话框输入「艾滋病人」,也同样出现了「武汉人」的中文翻译。
不过也有网友发现谷歌翻译也会将「埃博拉病毒」翻译为「纽约病毒」。
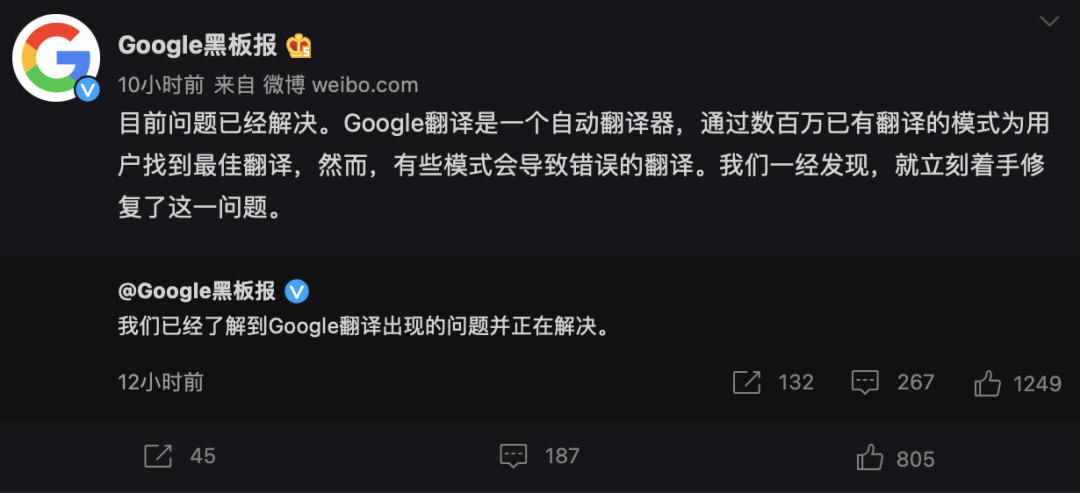
目前谷歌翻译的问题已无法复现,有网友认为谷歌是在「夹带私货」,但Google 在微博上的解释是「模式」,也就是说训练语料要背大锅,如果训练语料存在夹带私货的情况,那翻译结果也不会准确。
在谷歌回应之后,安徽省团委也再次发文表示「希望广大网友们能理性对待,中国人民不可辱!」
对此,NeX8yte指出,国际互联网上中文的语料大部分并不掌握在我们自己手里,而且此类结果很可能是经过了中介语言,从而也就放大了错误。
今天雷雨三级风则从技术角度指出,谷歌翻译是可以通过大量用户提交的修改进行「纠错」的。当翻译结果被大量用户「更正」之后,那么谷歌就会认为这样翻译是对的,从而修改显示的结果。
银蓝剑6H17也表示,这种结果的出现一方面是机器学习用了脏语料,让部分中文输入也可以输出翻译结果,另外一方面就是模型到api的调用阶段管理出现了真空。
为什么恰好会有人找到谷歌翻译,又恰好翻译这些并不常用的词语,又双叒叕恰好把忽略系统建议硬把源语言设成「英文」呢?
输入一段中文,然后硬告诉程序这是英文,让他把这玩意「翻译」成中文,其直接后果无非就是程序被你玩炸了,程序会认为这条「英文」它不会翻译,这时候只要有心人把这个用汉语写成的「冷门英文单词」在翻译社区提交翻译建议,就很容易达成这种结果。
时任国务院新闻办公室网络局负责人同年3月23日指出,外国公司在中国经营必须遵守中国法律。
谷歌公司违背进入中国市场时作出的书面承诺,停止对搜索服务进行过滤,并就黑客攻击影射和指责中国,这是完全错误的。我们坚决反对将商业问题政治化,对谷歌公司的无理指责和做法表示不满和愤慨。
时任工业和信息化部部长李毅中同年3月12日在回应「谷歌退出中国事件」时说,中国的互联网是开放的,进入中国市场就必须遵守中国法律。
例如大量重复的翻译的内容相信经常使用翻译的用户都会遇到过。
古文翻译也是一个常见的翻译场景,但可能是翻译语料太少的缘故,常见的名人名言都无法正确翻译,不过语气词倒是翻译的很准确。
一些历史事件如虎门销烟(Destruction of opium at Humen),如果没有建立专门的短语库,也是一个大型翻车现场,例如百度翻译曾经把「林则徐虎门销烟」翻译为「林则徐在虎门卖烟」,目前该问题已经修复。
不过这也不能怪翻译软件,毕竟「销售」也是这个「销」,只能说中华文化博大精深,翻译软件也要倒在一词多义上。
一些明星与粉丝互动时也要依靠翻译软件,由于不懂目标语言,所以他们也无法检验翻译结果是否正确。
例如原本的意思是让没能到场的圣女们也能够high起来,然而也许是翻译软件太过于直白,弄出了一些虎狼之词。
由于语言的博大精深,尽管机器翻译已经发展了70年,但翻译软件目前还没有到令人满意的程度,而机器翻译却是在互联网时代最重要的基础工具。
谷歌曾报告过,全世界互联网内容中英文占到了50%。与此同时仅有20%的人口能够看懂英文,可以说对于世界上大多数的人来说互联网上的大部分内容是与不懂中英文的人来说是绝缘的。
一般认为机器翻译的历史始于1950年代,虽然相关理论和研究较早已经进行,但在1954年初的乔治城大学的实验,即电脑成功将四十多条俄文句子自动翻译成英文,是机器翻译史中的一个里程碑,标志着现代机器翻译的开端。
在当时研究人员声称在三或五年内,机器翻译中遇到的语言逻辑的困难将会迎刃而解,美国和苏联为此投入了大量资金研究机器翻译。
1966年,自动语音处理顾问委员会(Automatic Language Processing Advisory Committee, ALPAC)报告发现十几年来的研究未能达到预期的成果,而且认为机器翻译在短期内不会取得突破性进展。
直至80年代后期,由于电脑运算效能的提升及电脑成本的降低,研究的重心开始放在机器翻译统计模型上。
至今仍没有一个翻译系统能够达到「全自动优质翻译任何文体」(fully automatic high quality translation of unrestricted text)的境界。
但在使用场景的严格限制下,已经有很多程序能够提供相对准确的翻译了。
在神经网络在NLP领域大火前,机器翻译界的主流方法都是Phrased-Based Machine Translation (PBMT),Google翻译使用的也是基于这个框架的算法。
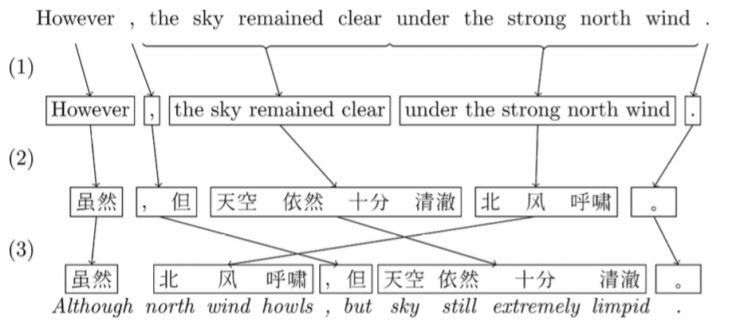
所谓Phrased-based,即翻译的最小单位由任意连续的词(Word)组合成为的短语(Phrase)。
-
首先,算法会把句子打散成一个个由词语组成的词组(中文需要进行额外的分词);
-
然后,预先训练好的统计模型会对于每个词组,找到另一种语言中最佳对应的词组;
-
最后,需要将这样「硬生生」翻译过来的目标语言词组,通过重新排序,让它看起来尽量通顺以及符合目标语言的语法。
传统的PBMT的方法,一直被称为NLP(Natural Language Processing,自然语言处理)领域的终极任务之一。
因为整个翻译过程中,需要依次调用其他各种更底层的NLP算法,比如中文分词、词性标注、句法结构等等,最终才能生成正确的翻译。这样像流水线一样的翻译方法,一环套一环,中间任意一个环节有了错误,这样的错误会一直传播下去(error propagation),导致最终的结果出错。
因此,即使单个系统准确率可以高达95%,但是整个翻译流程走下来,最终累积的错误可能就不可接受了。
由于神经网络的大火,目前的机器翻译技术大多都采用神经网络机器翻译(Neural Machine Translation, NMT)的方式。
相比于传统的统计机器翻译(SMT)而言,NMT能够训练一张能够从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,这在翻译、对话和文字概括方面能够获得非常好的表现。
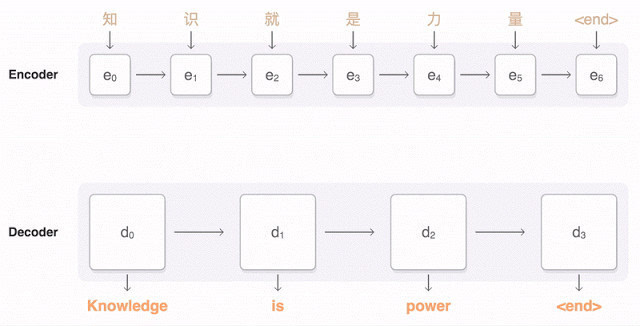
NMT本质上是一个encoder-decoder系统,encoder把源语言序列进行编码,并提取源语言中信息,通过decoder再把这种信息转换到另一种语言即目标语言中来,从而完成对语言的翻译。
NMT这样的过程直接学习源语言到目标语言,省去了训练一大堆复杂NLP子系统的依赖,依靠大量的训练数据(平行语料库,比如同一本书的中文和英文版本),直接让深度神经网络去学习拟合,省去了很多人工特征选择和调参的步骤。
2015年,Yoshua Bengio团队进一步,加入了Attention的概念。稍微区别于上面描述的Encoder-Decoder方法,基于Attention的Decoder逻辑在从隐层h中读取信息输出的时候,会根据现在正在翻译的是哪个词,自动调整对隐层的读入权重。即翻译每个词的时候,会更加有侧重点,这样也模拟了传统翻译中词组对词组的对应翻译的过程。
Bengio团队的这个工作也奠定了后序很多NMT商业系统的基础。
时至今日,框架还是那个encoder-decoder,但模型也已经换了一个又一个,从RNN到Transformer,本质不变的还是训练数据。
如果训练数据不干净,那以后谷歌翻译这样的「事故」还会更加多,人工智能的发展也应符合社会统一的道德要求,只有加强数据和技术上的审计才能避免社会问题。
参考资料:
https://weibo.com/7532796319/L3i2ajckR?refer_flag=1001030103_
https://world.huanqiu.com/article/45kM1mkchMV
![]()