多伦多大学朱子宁:一种选择语言探针的信息论观点

本文来源:AI Time论道

语言探针所解决的问题
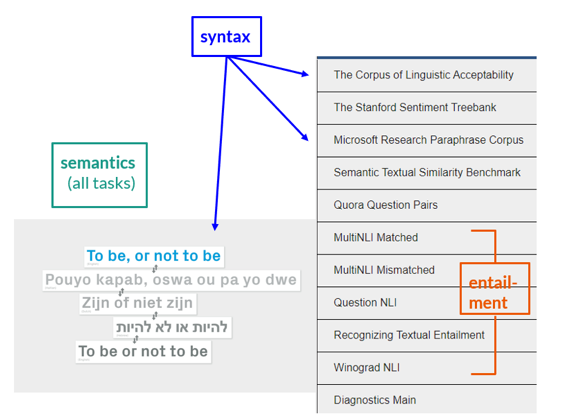

对于语言探针的探索


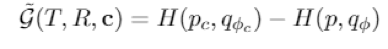
我们的分析


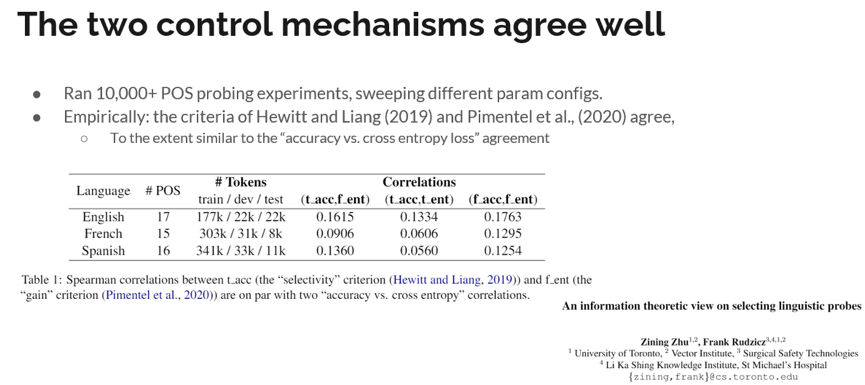
总结



点击阅读原文,直达AAAI小组!
登录查看更多
相关内容

Arxiv
3+阅读 · 2018年8月27日
Arxiv
3+阅读 · 2018年4月20日

相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年8月27日
Arxiv
3+阅读 · 2018年4月20日