

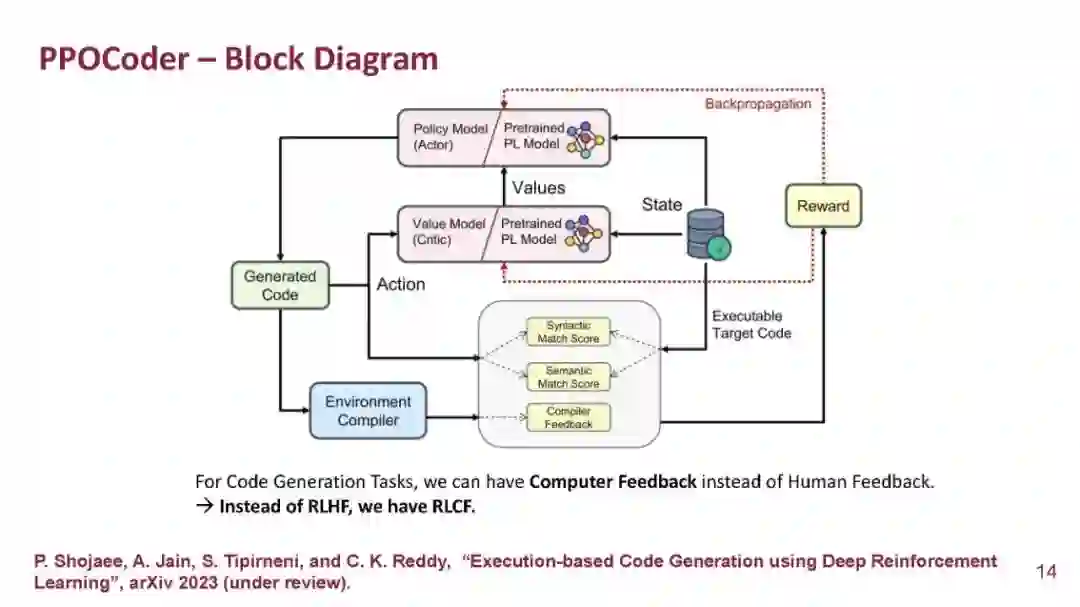
机器学习的最新进展提高了源代码的理解和生成,从而在各种软件工程任务中取得了更好的性能。在大规模代码库上进行预训练的编程语言模型(Programming language model, PLM)在代码摘要、代码翻译和程序合成等任务中显示出良好的效果。然而,目前的方法主要依赖于直接从文本生成文献中借鉴的有监督的微调目标,而忽略了代码特定的功能,如语法和功能正确性。在本次演讲中,我将介绍保留生成代码的语法和数据流的各种机制,然后描述我们的新框架PPOCoder,它将预训练代码PLM与深度强化学习相结合,并将执行反馈作为模型优化过程的外部知识来源。我将通过讨论CodeAttack框架来结束这次演讲,这是一个简单但有效的黑盒攻击模型,用于生成对抗代码样本,可以检测code PLM中的漏洞。
讲者:Chandan Reddy是弗吉尼亚理工大学计算机科学系的教授,他拥有康奈尔大学的博士学位和密歇根州立大学的硕士学位。他的主要研究兴趣是机器学习和自然语言处理及其在医疗保健、软件、交通和电子商务中的应用。他的研究得到了NSF、NIH、DOE、DOT和各种行业的资助。他在领先的会议和期刊上发表了160多篇同行评议的文章。他的研究工作获得了多个奖项,包括2010年ACM SIGKDD会议的最佳应用论文奖,2014年IEEE VAST会议的最佳海报奖,2016年IEEE ICDM会议的最佳学生论文奖,并在2011年INFORMS Franz Edelman Award竞赛中入围。他是ACM TKDD、ACM TIST和IEEE大数据期刊的编辑委员会成员。他是IEEE的高级成员和ACM的杰出成员。

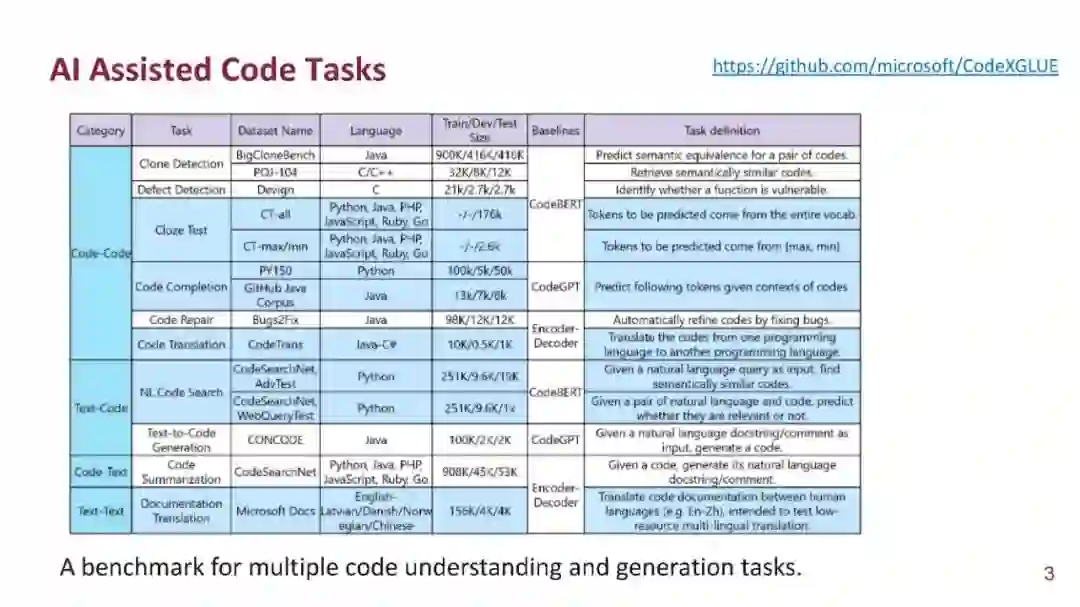
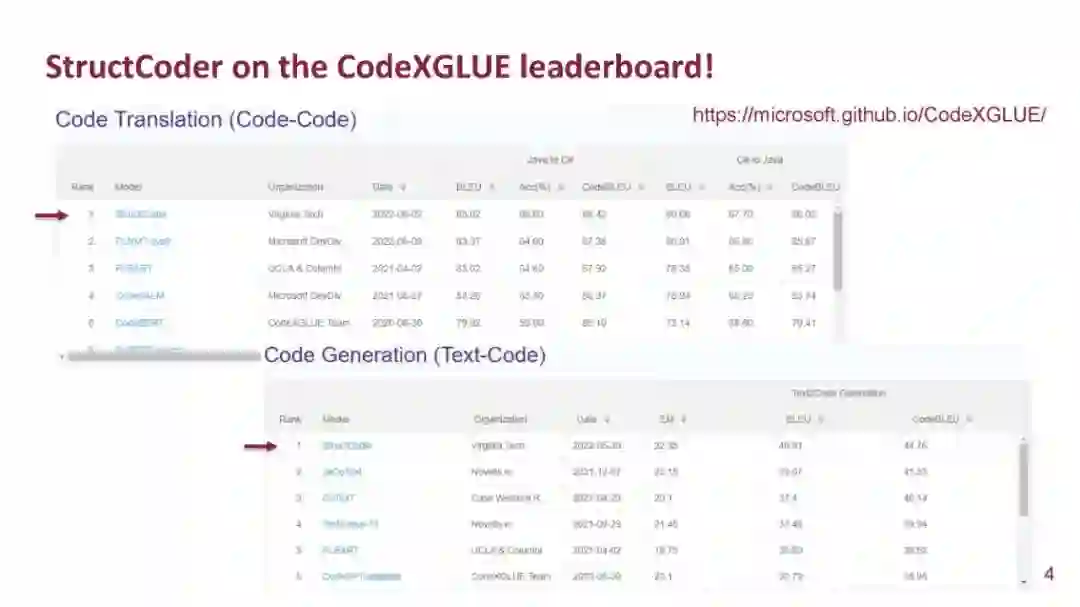
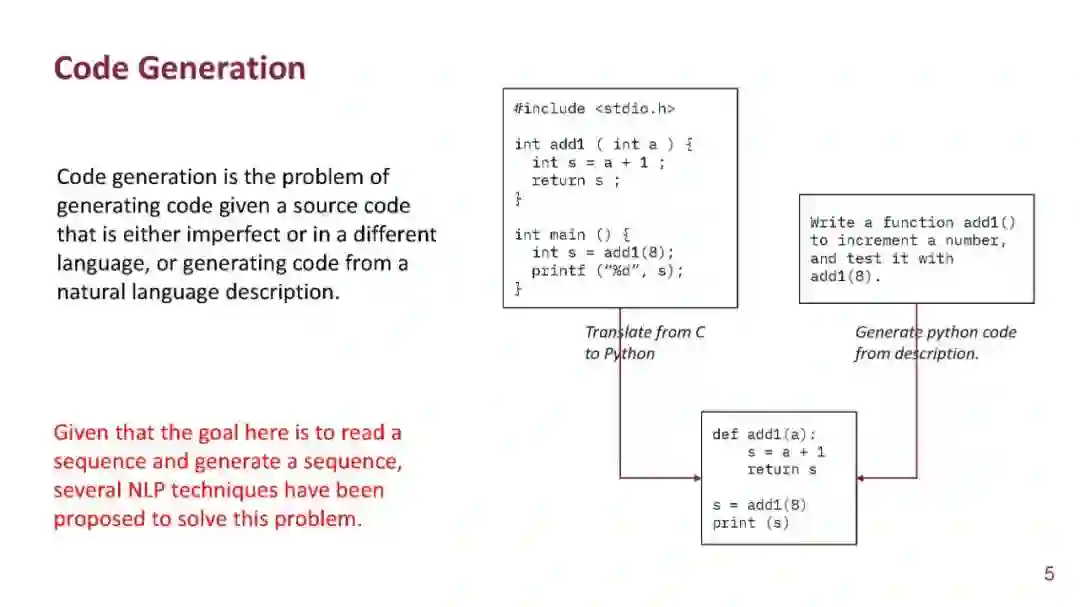
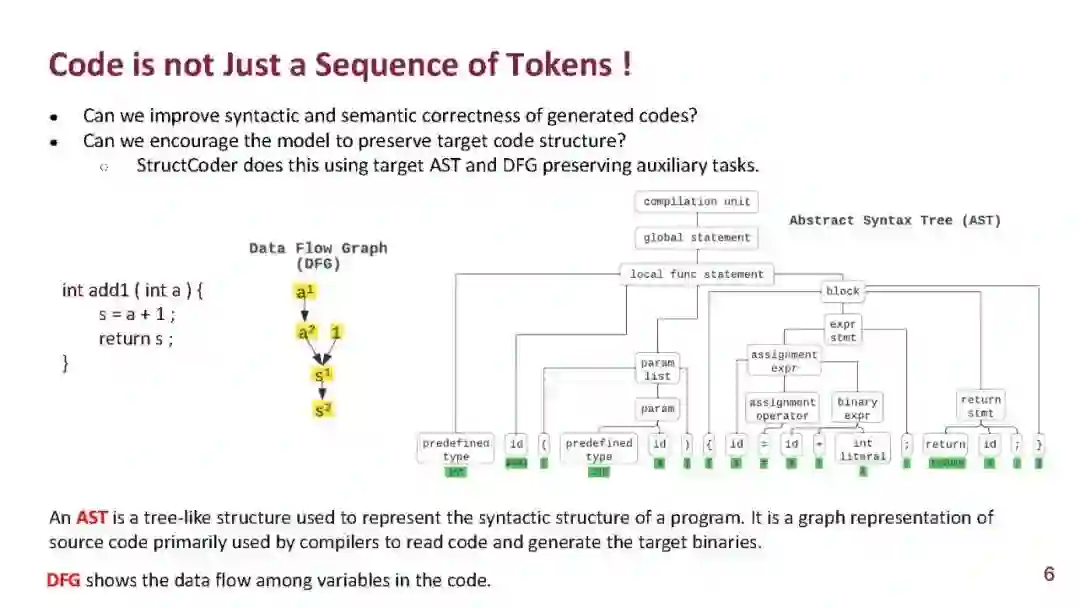





成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年4月10日
Arxiv
0+阅读 · 2023年4月4日

相关VIP内容
相关资讯