

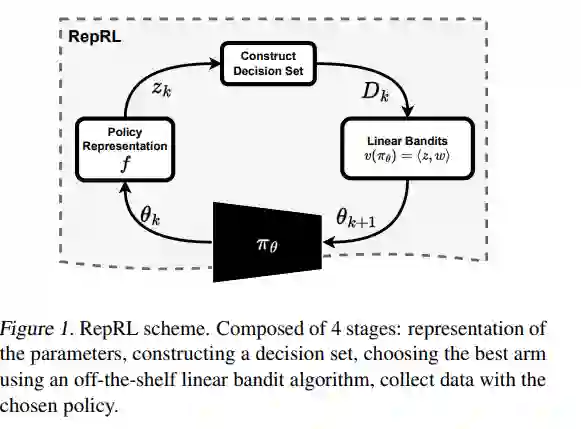
我们提出了一个由表示驱动的强化学习框架。通过将策略表示为它们预期值的估计,我们利用来自情境赌博机的技术来引导探索和利用。特别地,将策略网络嵌入到线性特征空间中,使我们能够将探索-利用问题重塑为表示-利用问题,其中良好的策略表示能够实现最优探索。我们通过将这个框架应用于进化和策略梯度方法来证明其有效性,这导致了与传统方法相比的显著性能提升。我们的框架为强化学习提供了新的视角,强调了策略表示在确定最优探索-利用策略中的重要性。
成为VIP会员查看完整内容
相关内容

强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。
强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。
该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。

相关VIP内容
相关资讯
相关论文