** ****新智元报道 **
编辑:编辑部**【新智元导读】为何Sora会掀起滔天巨浪?Sora的技术,就是机器模拟我们世界的下一步。而且今天有人扒出,Sora创新的核心秘密时空Patches,竟是来自谷歌DeepMind和谢赛宁的论文成果。**
OpenAI,永远快别人一步!像ChatGPT成功抢了Claude的头条一样,这一次,谷歌核弹级大杀器Gemini 1.5才推出没几个小时,全世界的目光就被OpenAI的Sora抢了去。100万token的上下文,仅靠一本语法书就学会了一门全新的语言,如此震撼的技术进步,在Sora的荣光下被衬得暗淡无光,着实令人唏嘘。这次,不过也是之前历史的重演。

Sora一出,马斯克直接大呼:人类彻底完蛋了!



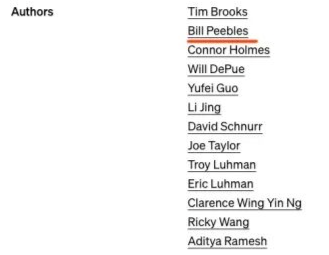
谢赛宁:Sora很厉害,不过好像是用了我的论文成果
AI大神谢赛宁,针对Sora的技术报告谈了自己的看法。 


AI究竟如何将静态图形转换为动态、逼真的视频?Sora的一大创新,就是创新性地使用了时空patch。通过底层训练和patch,Sora能够理解和开发近乎完美的视觉模拟,比如Minecraft这样的数字世界。这样,它就会为未来的AI创造出训练内容。有了数据和系统,AI就能更好地理解世界。
Sora的独特方法如何改变视频生成
以往,生成模型的方法包括GAN、自回归、扩散模型。它们都有各自的优势和局限性。而Sora引入的,是一种全新的范式转变——新的建模技术和灵活性,可以处理各种时间、纵横比和分辨率。Sora所做的,是把Diffusion和Transformer架构结合在一起,创建了diffusion transformer模型。于是,以下功能应运而生——文字转视频:将文字内容变成视频 图片转视频:赋予静止图像动态生命 视频风格转换:改变原有视频的风格 视频时间延展:可以将视频向前或向后延长 创造无缝循环视频:制作出看起来永无止境的循环视频 生成单帧图像视频:将静态图像转化为最高2048 x 2048分辨率的单帧视频 生成各种格式的视频:支持从1920 x 1080到1080 x 1920之间各种分辨率格式 模拟虚拟世界:创造出类似于Minecraft等游戏的虚拟世界 创作短视频:制作最长达一分钟的视频,包含多个短片这就好比,我们正在厨房里。传统的视频生成模型,比如Pika和RunwayML,就像照着食谱做饭的厨师一样。他们可以做出好吃的菜肴(视频),但会受到他们所知的食谱(算法)所限。使用特定的成分(数据格式)和技术(模型架构),它们只擅长烘焙蛋糕(短片)或烹饪意大利面(特定类型的视频)。
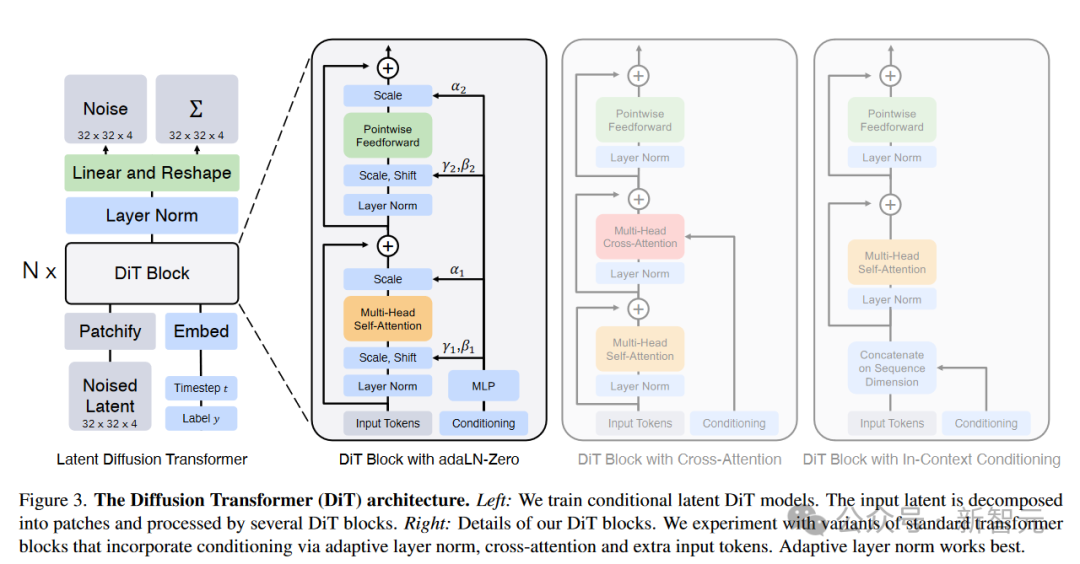
探寻Sora秘密成分的核心:时空patch
时空patch,是Sora创新的核心。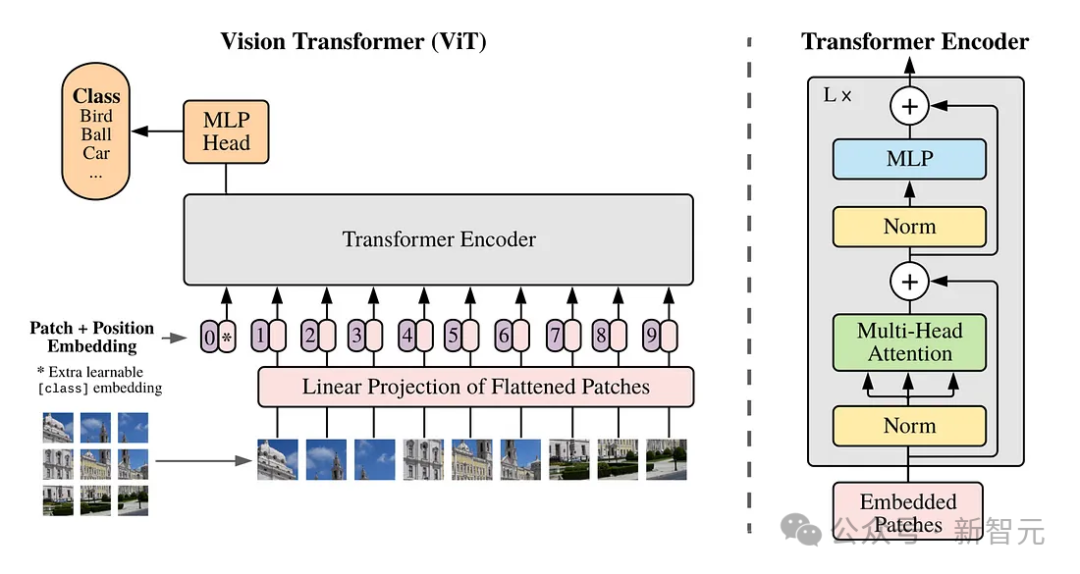




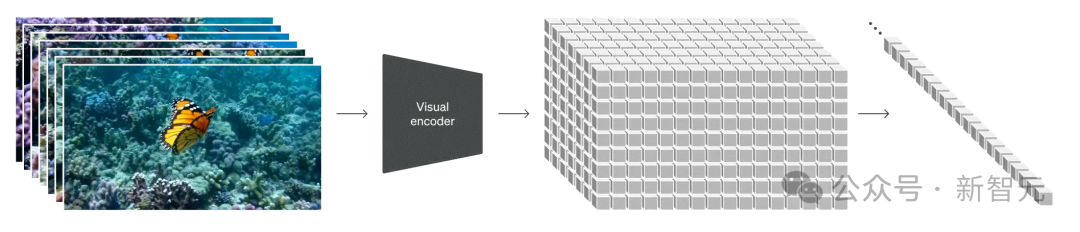
多样化数据在训练中的作用
训练数据的质量和多样性,对于模型的性能至关重要。传统的视频模型,是在限制性更强的数据集、更短的长度和更窄的目标上进行训练的。而Sora利用了庞大而多样的数据集,包括不同持续时间、分辨率和纵横比的视频和图像。它能够重新创建像Minecraft这样的数字世界,以及来自Unreal或Unity等系统的模拟世界镜头,以捕捉视频内容的所有角度和各种风格。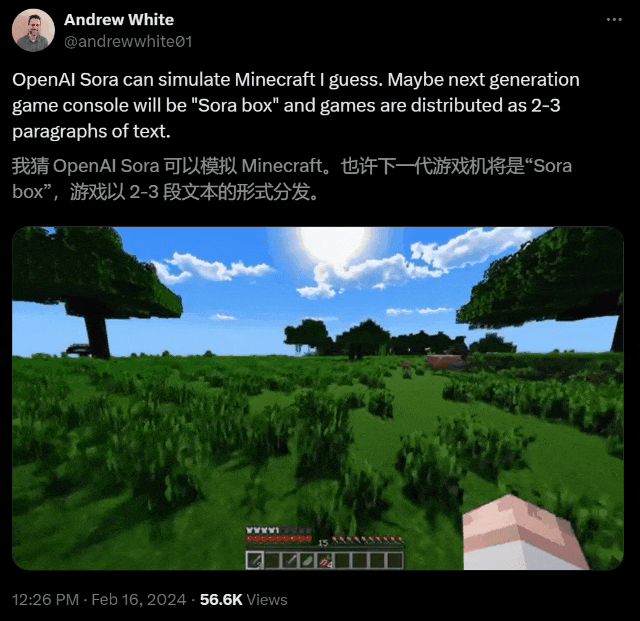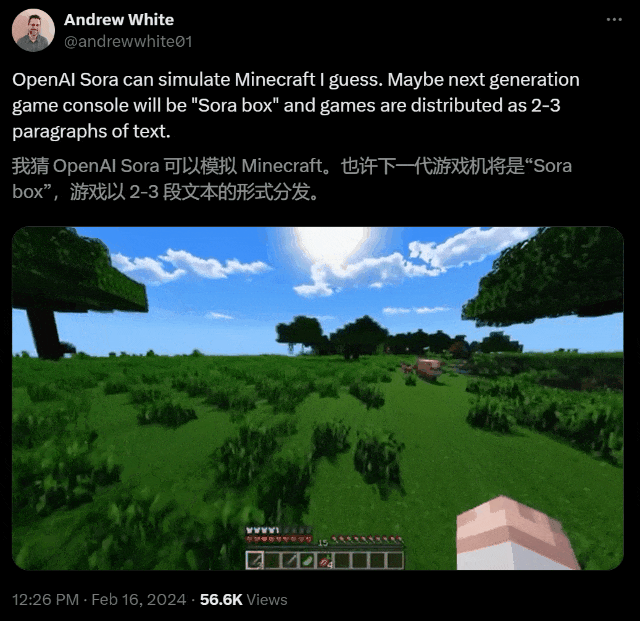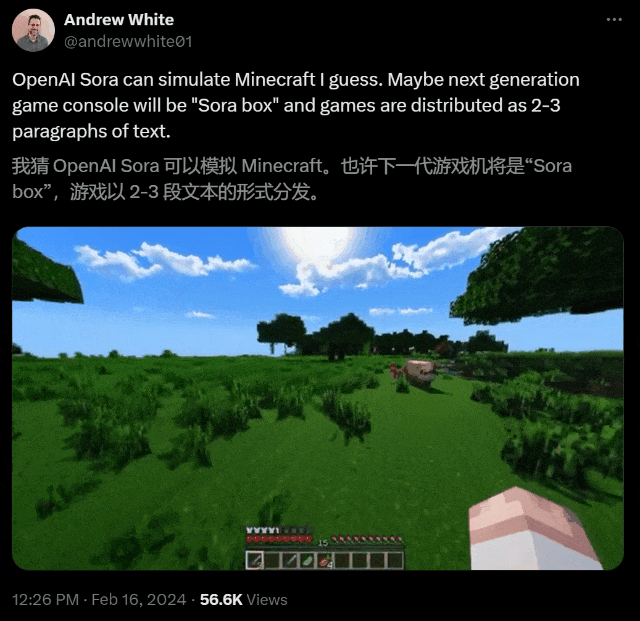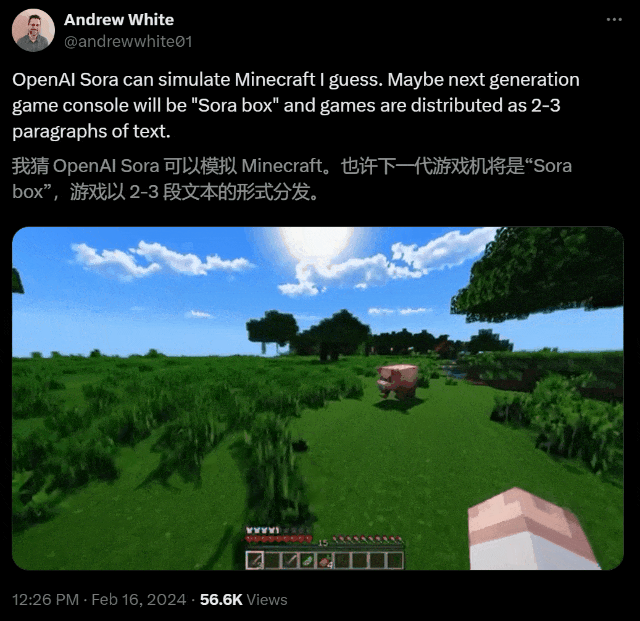

让物理世界栩栩如生:Sora对3D和连续性的掌握
3D空间和物体的一致性,是Sora演示中的关键亮点。通过对各种视频数据进行训练,无需对视频进行调整或预处理,Sora就学会了以令人印象深刻的精度对物理世界进行建模,原因就在于,它能够以原始形式使用训练数据。在Sora生成的视频中,物体和角色在三维空间中令人信服地移动和交互,即使它们被遮挡或离开框架,也能保持连贯性。从此,现实不存在了,创造力和现实主义的界限被突破。并且,Sora为模型的可能性设立了全新的标准,开源社区很可能会掀起视觉模型的全新革命。而现在,Sora的旅程才刚刚开始呢,正如OpenAI所说,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的道路。前方,就是AGI和世界模型了。不过好在,OpenAI员工透露说,Sora短期内不会面世。