

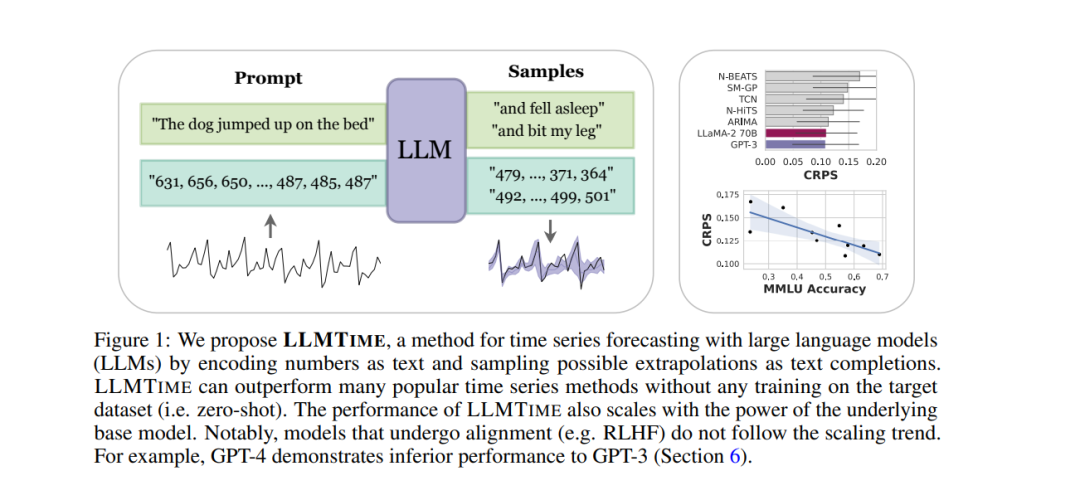
通过将时间序列编码为一串数字字符,我们可以将时间序列预测视为文本中的下一个标记预测。发展这种方法,我们发现大型语言模型 (LLMs) 如 GPT-3 和 LLaMA-2 可以令人惊讶地零次推断时间序列,其水平与或超过专门为下游任务训练的时间序列模型的性能。为了促进这种性能,我们提出了有效标记化时间序列数据的程序,并将标记上的离散分布转化为连续值上的高度灵活密度。我们认为LLMs在时间序列中的成功来源于它们能够自然地表示多模态分布,与简单性、重复性的偏见相结合,这与许多时间序列中的突出特征,如重复的季节性趋势,是一致的。我们还展示了LLMs如何能够通过非数字文本自然处理缺失数据而不需要估计,适应文本的边际信息,并回答问题以帮助解释预测。虽然我们发现增加模型大小通常会提高时间序列的性能,但我们显示GPT-4在如何标记数字和较差的不确定性校准方面可能比GPT-3表现得更差,这可能是对齐干预如RLHF的结果。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日