

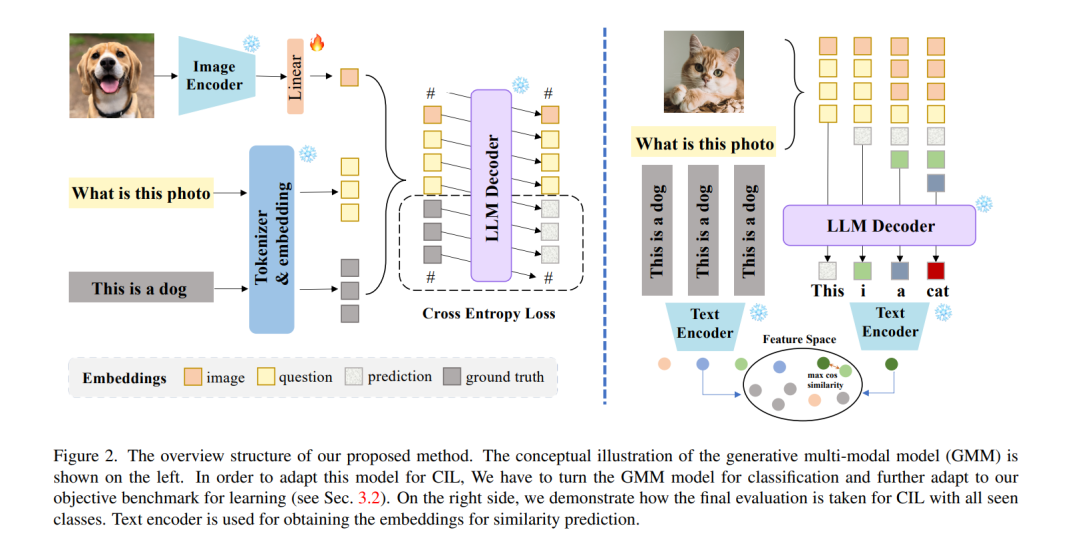
在类增量学习(CIL)场景中,分类器对当前任务的偏好引起的灾难性遗忘现象长期以来一直是一个重大挑战。这主要是由判别模型的特性所引起的。随着生成式多模态模型的日益流行,我们将探索用生成模型替换判别模型以用于CIL。然而,从判别模型转向生成模型需要解决两个关键挑战。主要挑战在于将生成的文本信息转换为不同类别的分类。此外,它还需要在生成框架内制定CIL的任务。为此,我们提出了一种新颖的生成式多模态模型(GMM)框架用于类增量学习。我们的方法直接使用适配的生成模型为图像生成标签。获取详细文本后,我们使用文本编码器提取文本特征,并采用特征匹配来确定最相似的标签作为分类预测。在传统的CIL设置中,我们在长序列任务场景中取得了显著更好的结果。在少量样本CIL设置下,我们的准确度至少提高了14%,相比所有当前最先进的方法有显著更少的遗忘。我们的代码可在 https://github.com/DoubleClass/GMM 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日