
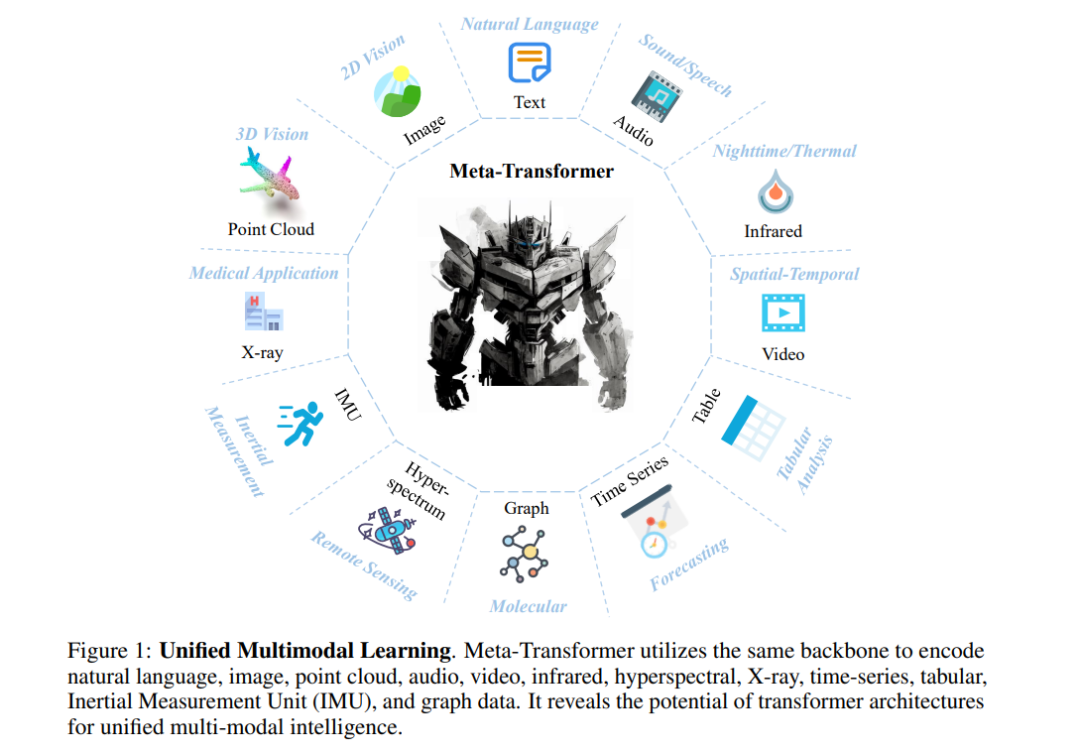
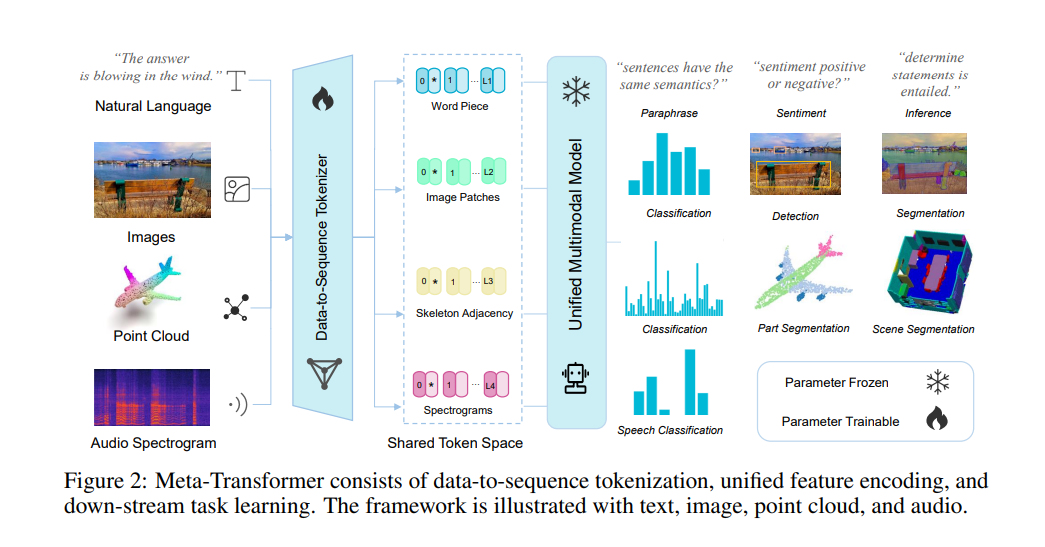
但由于它们之间固有的差距,设计一个用于处理各种模态(例如自然语言、2D图像、3D点云、音频、视频、时间序列、表格数据)的统一网络仍然具有挑战性。在这项工作中,我们提出了一个名为Meta-Transformer的框架,它利用一个固定的编码器在没有任何成对的多模态训练数据的情况下执行多模态感知。在Meta-Transformer中,来自各种模态的原始输入数据被映射到一个共享的令牌空间,允许一个具有固定参数的后续编码器提取输入数据的高级语义特征。Meta-Transformer由三个主要组件组成:一个统一的数据令牌化器、一个模态共享的编码器和用于下游任务的任务特定头部。Meta-Transformer是第一个能够在12种模态上执行统一学习并使用非配对数据的框架。在不同基准上的实验显示,Meta-Transformer可以处理包括基本感知(文本、图像、点云、音频、视频)、实际应用(X射线、红外、超光谱和IMU)和数据挖掘(图、表格和时间序列)在内的广泛任务。Meta-Transformer为使用变换器开发统一的多模态智能展示了一个有前景的未来。代码将在 https://github.com/invictus717/MetaTransformer 上提供。
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日