

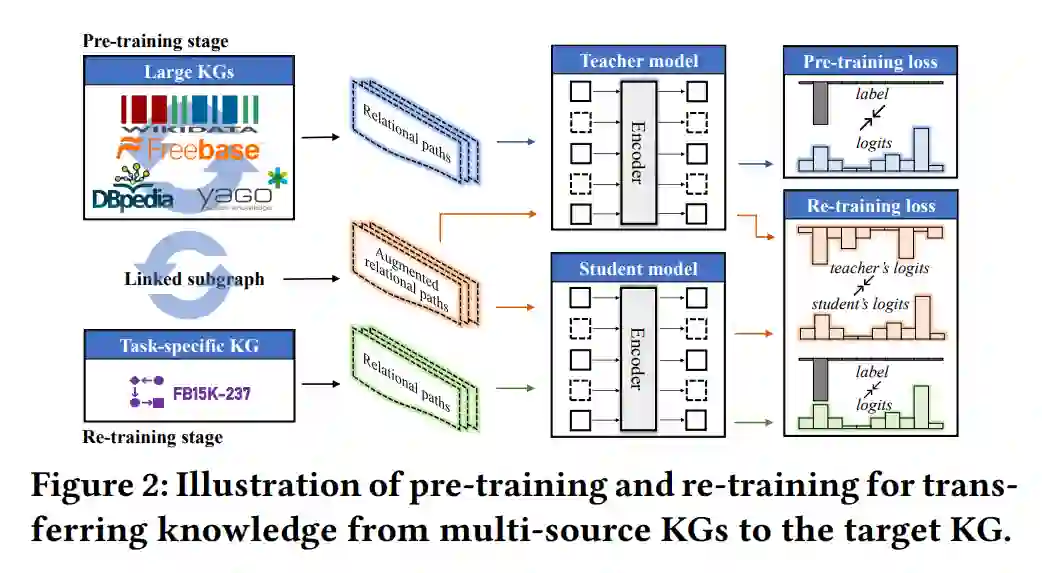
在这篇论文中,我们提出了用于学习和应用多源知识图谱(KG)嵌入的“联合预训练和局部重训”框架。我们的动机是,不同的KG包含可以改进KG嵌入和下游任务的互补信息。我们在链接的多源KG上预训练一个大型的教师KG嵌入模型,并将知识蒸馏到针对特定任务的KG的学生模型中。为了实现不同KG之间的知识转移,我们使用实体对齐来构建一个连接预训练KG和目标KG的链接子图。这个链接子图被重新训练,进行从教师到学生的三级知识蒸馏,即特征知识蒸馏,网络知识蒸馏和预测知识蒸馏,以生成更有表现力的嵌入。教师模型可以被重复用于不同的目标KG和任务,无需从头开始训练。我们进行了大量的实验来展示我们的框架的有效性和效率。
https://www.zhuanzhi.ai/paper/7c51aae482b4dfe47e2d387915dbcf24
成为VIP会员查看完整内容
相关内容
Arxiv
11+阅读 · 2019年6月13日

相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年6月13日