TPAMI 2022|程明明团队提出LUSS:大规模无监督语义分割和ImageNet-S数据集

极市导读
针对大规模无监督语义分割,程明明团队提出了一个用于LUSS 任务的大规模像素级语义分割数据集 ImageNet-S。在移除了部分不可分割的类别后,ImageNet-S含有 ImageNet中的919 个类别和约120 万张训练图片。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
引言
语义分割是计算机视觉领域中被广泛关注的一个研究方向,其旨在针对图像中每一个像素进行分类。由于语义分割的固有挑战,目前大多数工作都关注于多样性受限(例如几十类)且数据规模受限场景的语义分割。尽管许多方法在这些受限的场景中取得了显著的效果,但是面对现实世界中常用的几百上千类物体规模带来的新挑战时,现有方法难以解决。这促使我们思考一个更具有挑战性的问题:语义分割是否可能用于多样性更强且规模更大的现实世界场景呢?
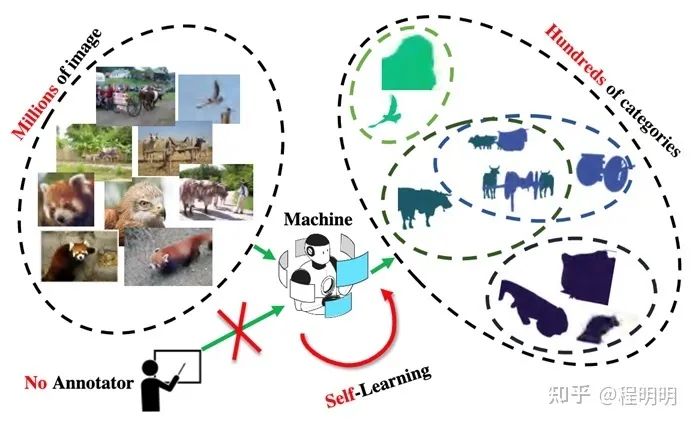
由于巨大的数据规模和隐私问题,为现实世界场景的海量图像进行像素级标注是十分昂贵的。缺乏足够的标注数据限制了大规模语义分割任务的发展。另一方面,用数百万张甚至数十亿张图片(例如ImageNet, JFT-300M, 和Instagram-1B)进行无监督/自监督训练得到的分类模型已经展现出与有监督学习相当的分类能力。这促使我们考虑是否可以通过无监督学习的方式实现真实世界场景语义分割的目标。为此我们提出了一个新的问题:大规模无监督语义分割(Large-scale Unsupervised Semantic Segmentation,LUSS)。如图1所示,LUSS 任务的目标是在没有人工标注监督的情况下,通过模型自我学习从大规模图像数据中总结出多样化的语义类别,并将成百上千个类别分配给数百万以上的图像中的每个像素。
挑战
实现LUSS这一目标面临许多挑战,例如需要同时解决大规模数据下的形状相关的表征学习,类别相关的表征学习以及无监督的语义聚类。具体而言,模型需要提取类别相关的表征来区分大量类别,并利用物体形状、纹理和边界等像素级表征实现对物体的分割。两种表征在不冲突的情况下相互配合对实现 LUSS 至关重要。基于相关表征,模型需要利用鲁棒且高效的聚类算法从大规模数据中生成语义类别。同时,对像素进行分割需要准确地区分语义相关和无关的区域。
前景
实现LUSS任务使在现实世界场景下实现语义分割成为可能。同时,解决LUSS的挑战也能进一步提升许多相关任务的性能。例如,在LUSS任务中学习到的形状、类别相关的表征使LUSS模型可以被用作语义分割和实例分割等像素级下游任务的预训练模型。此外,利用小部分人工标注数据微调LUSS模型的半监督学习策略能够使LUSS 模型快速得到实际应用。
LUSS Benchmark和ImageNet-S数据集
为了方便评测对比,我们提出了一个LUSS benchmark,包括一个具有高度多样性的大规模数据集ImageNet-S和侧重不同角度的多种评价指标。
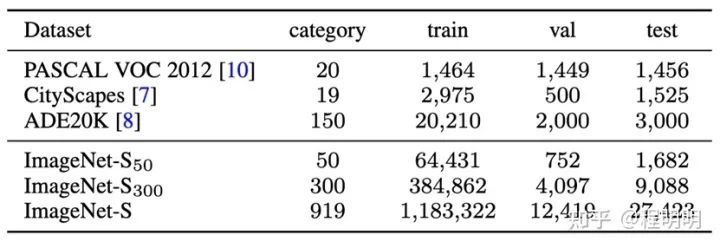
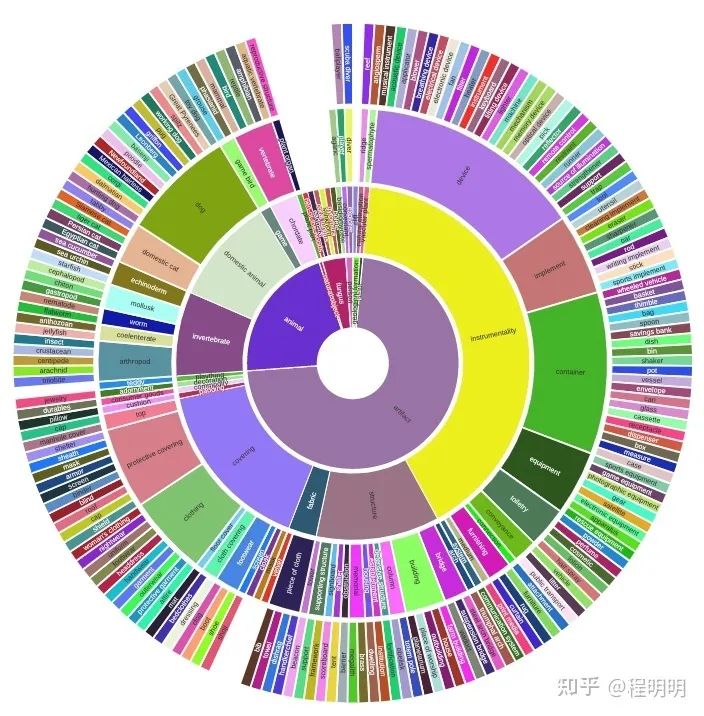
ImageNet-S数据集: 基于广泛使用的ImageNet[1]数据集中的精确像素级标签[1,2],我们提出了一个用于LUSS 任务的大规模像素级语义分割数据集 ImageNet-S。在移除了部分不可分割的类别后,ImageNet-S含有 ImageNet中的919 个类别和约120 万张训练图片。为更加全面地评测LUSS 任务并且探索未来的应用,我们为4万余张测试图片和约1%的训练图片(约9千张)提供了像素级语义分割标注。ImageNet-S 数据集为LUSS任务提供了多样性强的大规模数据,在充分展示LUSS任务的挑战性的同时也为模型获取丰富的表征信息提供了数据支持。如图表2所示,ImageNet-S在数量规模和类别多样性上远高于常用的语义分割数据集。且得益于ImageNet的WordTree结构,ImageNet-S具有层次化的多粒度类别分级(图3)。为方便在计算资源有限的情况下进行研究,我们也划分了包含300类和50类的子集。ImageNet-S可在https://github.com/LUSSeg/ImageNet-S下载使用。
ImageNet-S数据集除了可支持LUSS任务外,也可通过部分的训练集像素级标注实现半监督的大规模语义分割,从而对backbone模型的表征能力和自监督模型的表征能力进行评估。我们开源了一个用于半监督大规模语义分割的代码库,正在集成常见的backbone模型和自监督模型:
半监督大规模语义分割代码库github.com/LUSSeg/ImageNetSegModel
https://github.com/LUSSeg/ImageNetSegModel
LUSS的丰富评测指标:
由于在训练过程中没有人工标注的类别监督,LUSS模型不能像有监督模型一样进行直接评测。为此,我们为LUSS提出了三个评估方案,包括完全无监督评测,半监督评测以及基于距离匹配的评测。完全无监督评测将GT类别与模型生成的类别相匹配实现评测;半监督评测通过利用ImageNet-S的部分训练集语义分割标注来微调模型实现评测;基于距离匹配的评测通过对比训练集和测试集的表征距离实现评测。我们提供了测试集在线评测网站以供大家公平对比:
在线评测网站:
https://lusseg.github.io/
LUSS 基线方法
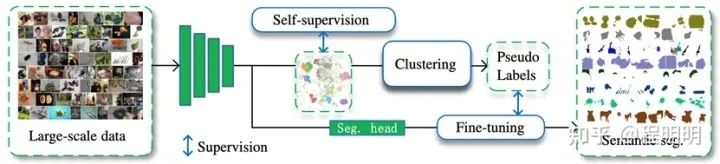
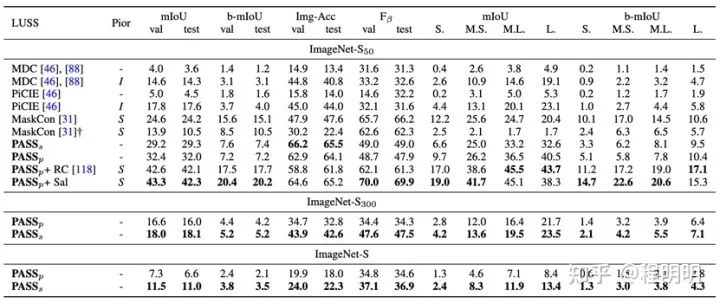
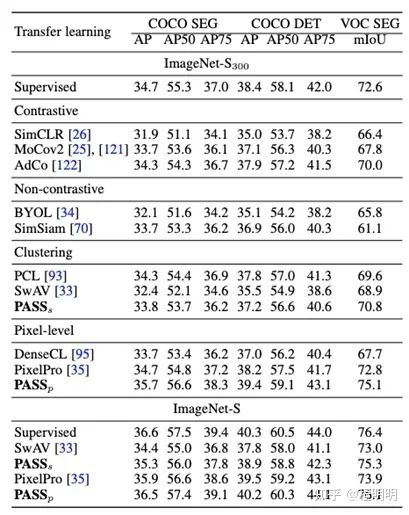
如图表4所示,我们提出了一个用于 LUSS 任务的基线方法(名为PASS),包含自监督表征学习,伪标签生成和微调三个步骤。对于自监督表征学习,我们提出了1) 一种非对比的像素级表征对齐策略,以在不损害类别表征的情况下增强像素级的表征。2) 一个提高网络中间层表征质量的自深到浅的监督策略。以上两种策略保证模型学到高质量且可共存的形状和类别表征信息。在标签生成阶段,我们提出了一种像素注意力机制来突出对类别贡献大的语义区域,以实现在大数据量下高效的像素级伪标签生成和微调。PASS方法首次实现大规模的无监督语义分割(可视化结果见图表5),且相较于针对小规模数据设计的无监督语义分割方法有明显优势(见图表6)。此外如图表7所示,针对LUSS任务训练的PASS模型可以作为预训练模型提升下游有监督分割任务的性能。
PASS方法开源链接:
PASS方法开源代码github.com/LUSSeg/PASS
https://github.com/LUSSeg/PASS
展望
LUSS任务与模型预训练、半监督学习、语义聚类、高效网络结构设计等方向密切相关。即使在算力有限的情况下,依然可以基于现有的自监督预训练模型来设计更强的大规模无监督语义分割算法。研究者也可使用ImageNet-S 300/50类的子集用较少算力进行包括自监督预训练在内LUSS算法的研究,例如只需要2张GPU用十几小时即可完成50类子集上无监督语义分割的完整训练。此外,得益于ImageNet-S的部分训练集像素级标注,可以用极低的计算开销进行半监督训练,例如只用单张GPU只需约1小时即可完成近千类语义分割任务的finetune训练。

[1] Deng, et al. "Imagenet: A large-scale hierarchical image database." IEEE CVPR 2009.
[2] Beyer, et al. "Are we done with ImageNet?." arXiv 2020.
[3] Gao, et al. "Large-scale Unsupervised Semantic Segmentation", IEEE TPAMI 2022.
公众号后台回复“直播”获取极市直播系列PPT下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
极市&深大CV技术交流群已创建,欢迎深大校友加入,在群内自由交流学术心得,分享学术讯息,共建良好的技术交流氛围。
“
点击阅读原文进入CV社区
收获更多技术干货



