

近年来,从社交媒体平台、医学图像和机器人等各个领域产生和分享了大量的视觉内容。大量的内容创造和分享带来了新的挑战。特别是,对相似内容的数据库进行搜索,即基于内容的图像检索(CBIR),是一个长期存在的研究领域,需要更有效和准确的方法来实现实时检索。人工智能在CBIR方面取得了很大进展,极大地促进了智能搜索的进程。在本综述论文中,我们组织和回顾了基于深度学习算法和技术的CBIR研究,包括来自近期论文的见解和技术。我们识别并呈现了该领域常用的数据库、基准和评估方法。我们收集共同的挑战,并提出有希望的未来方向。更具体地说,我们关注深度学习的图像检索,并根据深度网络结构的类型、深度特征、特征增强方法和网络微调策略来组织目前最先进的方法。我们的综述论文查考虑了各种各样的最新方法,旨在促进基于类别的信息检索领域的全部视角。
https://www.zhuanzhi.ai/paper/01b0e04eb5d1eeb53be30aa761b7cd12
基于内容的图像检索(CBIR)是通过分析大型图库中的可视内容来搜索语义匹配或相似图像的问题,给定描述用户需求的查询图像,如图1(a)所示。CBIR是计算机视觉和多媒体领域长期存在的研究课题[1,2]。随着当前图像和视频数据的指数级增长,迫切需要开发一种合适的信息系统来有效地管理这样的大型图像集合,图像搜索是与可视化集合交互的最不可或缺的技术之一。因此,CBIR的应用潜力几乎是无限的,如人员再识别[3]、遥感[4]、医学图像搜索[5]、在线市场购物推荐[6]等。
CBIR可以大致分为实例级检索和类别级检索,如图1(b)所示。在实例级图像检索中,给定一个特定对象或场景(如埃菲尔铁塔)的查询图像,目标是找到包含相同对象或场景的图像,这些图像可能在不同的视点、光照条件或受遮挡情况下捕获[7,8]。相反,对于类别级别的图像检索,目标是找到与查询相同类的图像(例如,狗、汽车等)。实例级检索更有挑战性,也更有前景,因为它满足许多应用程序的特定目标。请注意,我们将本文的重点限制在实例级的图像检索上,如果没有进一步指定,则认为“图像检索”和“实例检索”是等价的,可以互换使用。
要找到想要的图像,可能需要在数千张、数百万张甚至数十亿张图像中搜索。因此,高效搜索与准确搜索同等重要,并为此不断付出努力[7,8,9,10,11]。为了实现对海量图像的准确高效检索,紧凑而丰富的特征表示是CBIR的核心。
近二十年来,图像特征表示取得了显著进展,主要包括两个重要阶段: 特征工程和特征学习(特别是深度学习)。在特征工程时代(即前深度学习时代),该领域被具有里程碑意义的手工工程特征描述符所主导,如尺度不变特征变换(SIFT)[19]。特征学习阶段,即自2012年开始的深度学习时代,从人工神经网络开始,特别是ImageNet和深度卷积神经网络(DCNN) AlexNet[20]的突破。从那以后,深度学习技术影响了广泛的研究领域,因为DCNNs可以直接从数据中学习具有多层抽象的强大特征表示,绕过了传统特征工程中的多个步骤。深度学习技术引起了人们的极大关注,并在许多计算机视觉任务中取得了长足的突破,包括图像分类[20,21,22]、目标检测[23]、语义分割[24]、图像检索[10,13,14]。
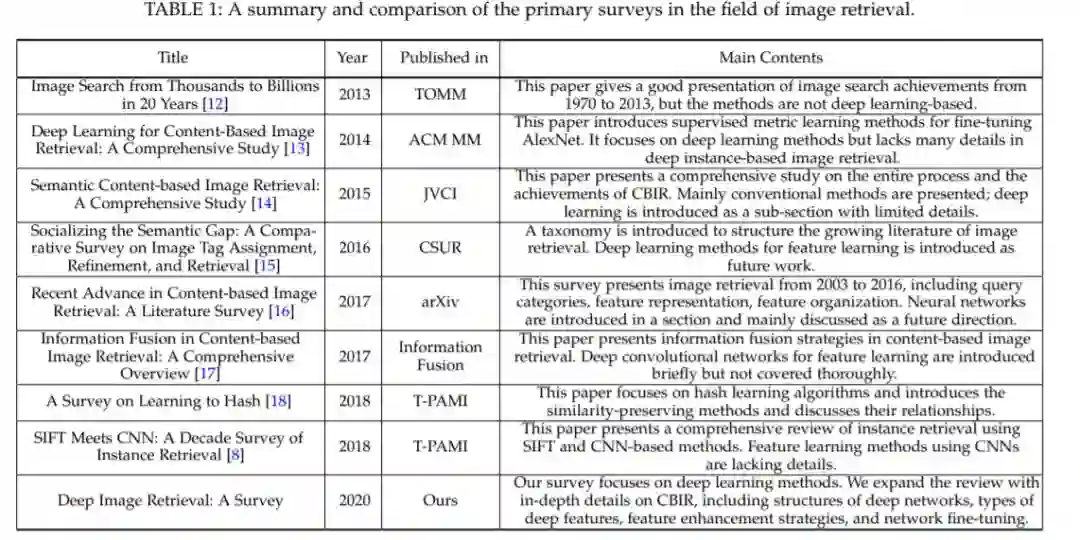
[1, 2, 8]对传统图像检索方法进行了优秀的研究。相比之下,本文侧重于基于深度学习的方法,我们的工作与其他发表的综述[8,14,15,16]比较如表1所示。图像检索的深度学习包含了如图2所示的关键阶段,为了提高检索的准确性和效率,已经提出了针对一个或多个阶段的多种方法。在本综述中,我们对这些方法进行了全面的详细介绍,包括深度网络的结构、特征融合、特征增强方法和网络微调策略,动机是以下问题一直在推动这一领域的研究:
1)通过只使用现成的模型,深度特征如何胜过手工制作特征?
2)在跨训练数据集的领域迁移的情况下,我们如何适应现成的模型来维持甚至提高检索性能?
3)由于深度特征通常是高维的,我们如何有效地利用它们进行高效的图像检索,特别是针对大规模数据集?
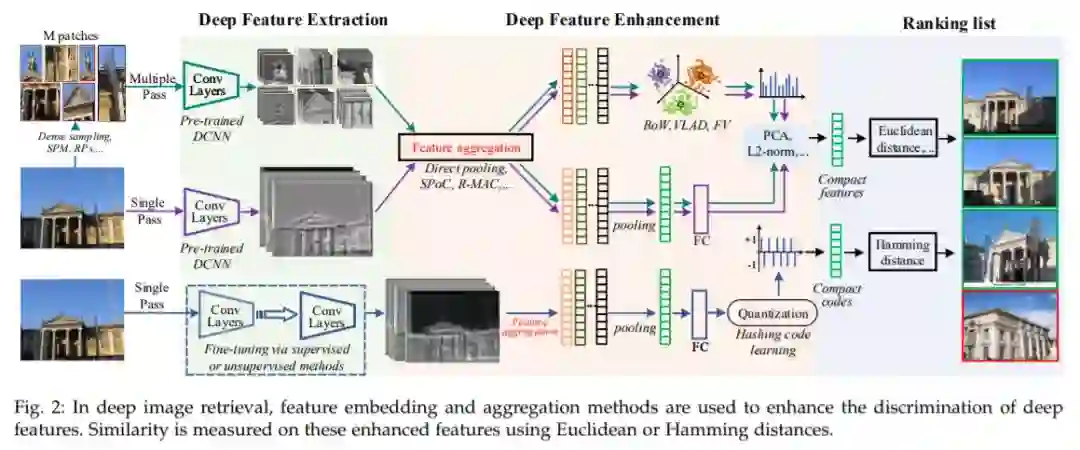
在基于AlexNet[20]的图像检索实现非常成功之后,对检索任务的DCNNs进行了重要的探索,大致沿循了上述三个问题。也就是说,DCNN方法被分为(1)现成的模型和(2)经过微调的模型,如图3所示,并并行处理(3)有效的特征。DCNN是现成的还是微调的,取决于DCNN的参数是[25]更新还是基于参数固定的DCNN[25,26,27]。对于特征图,研究人员提出了R-MAC[28]、CroW[10]、SPoC[7]等编码和聚合方法。
最近在改进图像检索方面的进展可以分为网络级和特征级两类,图4给出了详细的分类。这项综述大致包括以下四个范畴:
(1) 网络架构的改进 (第2节)
利用堆叠线性滤波器(如卷积)和非线性激活函数(ReLU等),不同深度的深度网络获得不同层次的特征。层次越深的网络能够提供更强大的学习能力,从而提取高层次的抽象和语义感知特征[21,46]。并行地连接多尺度特性是可能的,例如GoogLeNet [47]中的Inception模块,我们将其称为“扩展”。
(2) 深度特征提取(3.1节)
FC层和卷积层的神经元具有不同的接受域,这提供了三种提取特征的方法:卷积层的局部特征[7,59],FC层的全局特征[32,60],以及两种特征的融合[61,62],融合方案包括层级和模型级方法。深度特征可以从整幅图像中提取,也可以从图像小块中提取,分别对应于单通道和多通道的前馈方案。
(3) 深度特征增强
通过特征增强来提高深度特征的判别能力。直接使用深度网络[17]同时训练聚合特征;另外,特征嵌入方法包括BoW[63]、VLAD[64]和FV[65]将局部特征嵌入到全局特征中。这些方法分别使用深度网络(基于codebook)或联合(无codebook)进行训练。另外,采用哈希方法[18]将实值特征编码为二进制码,提高检索效率。特征增强策略会显著影响图像检索的效率。
(4) 学习表示的网络微调(第4节)
在源数据集上预先训练的用于图像分类的深度网络被转移到新的数据集上进行检索任务。然而,检索性能受到数据集之间的域转移的影响。因此,有必要对深度网络进行微调到特定的领域[34,56,66],这可以通过有监督的微调方法来实现。然而,在大多数情况下,图像标记或标注是耗时和困难的,因此有必要开发无监督的方法进行网络微调。
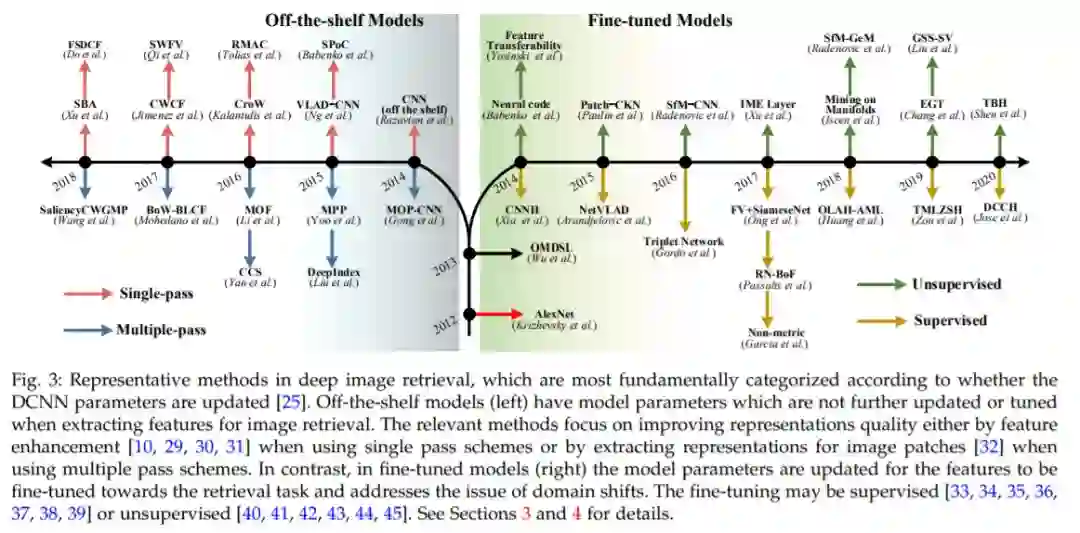
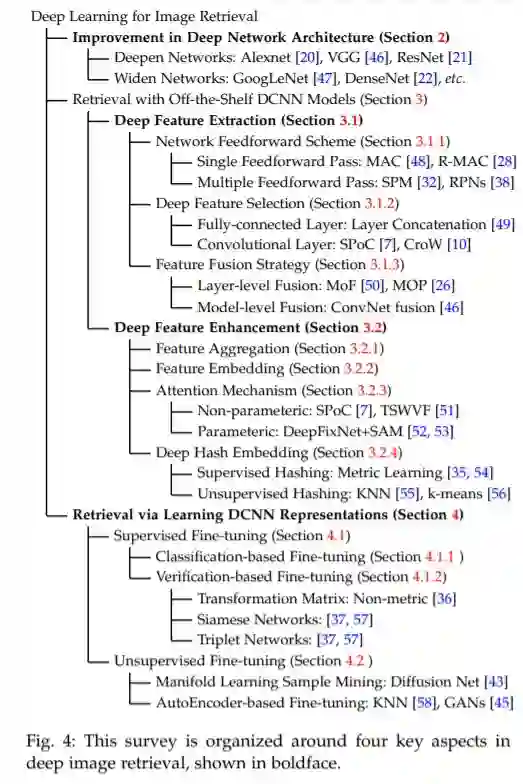
本文综述了近年来用于图像检索的深度学习方法的研究进展,并根据深度网络的参数更新,将其分为现成的深度图像检索模型和微调模型。

