

像学术文章和商业报告这样的长文档已经成为了详述需要额外关注的重要问题和复杂主题的标准格式。自动摘要系统可以有效地将长文档压缩成短小精悍的文本,从而浓缩最重要的信息,对帮助读者理解具有重要意义。近年来,随着神经体系结构的出现,人们对自动文本摘要系统进行了大量的研究,并对将这些系统扩展到长文档领域的挑战进行了大量的研究。在这项综述中,我们对长文档摘要的研究进行了全面的概述,并对其研究设置的三个主要组成部分: 基准数据集、摘要模型和评估指标进行了系统的评估。对于每个组成部分,我们在长文档总结的背景下组织文献,并进行实证分析,以拓宽当前研究进展的视角。实证分析包括基准数据集的内在特征研究、总结模型的多维分析和总结评价指标的综述。在此基础上,我们提出了这一快速发展的领域未来可能的探索方向。
文本信息的汇总对人类来说是一项艰巨的任务,大数据时代的信息增长速度使得大多数信息的手工汇总变得不切实际和不可能。当涉及到长形式的文本文档时,这种现象更加严重,因为处理和总结它所需的知识和人力劳动随着文档的长度呈指数级增长。不可避免地,大量宝贵的信息和知识被忽视了,成为社会和经济发展进步的一个重要瓶颈。因此,对自动长文档摘要领域的详尽研究有着强烈的需求[2,20,25,77,104]。
自动文本摘要包括有效地缩短源文本,同时保持主旨不变的过程,这有助于减少处理信息所需的时间,有助于更快地搜索信息,并使学习一个主题更容易[71,73]。虽然开发一种有效的自动文本摘要系统的潜力已经引起了研究团体的极大兴趣和关注,但自动文本摘要仍然是一项具有挑战性的任务,并没有在日常生活中得到广泛的实际应用,尤其是在长文档摘要方面[8,61,62,81]。从直观上看,由于长短文档在词汇标记量和内容广度上存在显著差异,长文档摘要比短文档摘要更难。随着长度的增加,被认为是重要的内容也会增加,这使得自动摘要模型在有限的输出长度[37]中捕获所有显著信息的任务更具挑战性。此外,短文档通常是通用文本,如新闻文章[43,84,87,102],而长文档通常是领域特定的文章,如包含更复杂的公式和术语的科学论文[20,49,59]。加上本综述将探讨的其他原因,长文档摘要比短文档摘要具有更大的挑战性。
通常情况下,自动文本摘要可以被定义为三种方法:提取法、抽象法和混合法[62]。抽取式方法直接从源文档中复制显著的句子并组合成输出[15,38],而抽象式方法模仿人理解源文档并根据源文档的突出概念编写摘要输出[101,103]。混合方法试图结合两种方法的优点,基于从源文档[36,47,73]提取的显著内容子集重写摘要。每种方法都有其优点和局限性,可能更适合某些汇总任务。例如,在总结某些新闻文章[15,128]时,提取式摘要可能是足够的,但在重要内容分布稀疏的长对话中,提取式摘要就不够了[131]。这是因为虽然提取摘要方法总是与源文档在事实上保持一致,但它不修改原始文本,因此缺乏生成流畅、简洁的摘要的能力[120]。
历史上,为了衡量不同摘要体系结构的性能,ROUGE评分[70]一直是摘要研究领域的研究者比较和研究不同候选摘要质量的方法。ROUGE评分的核心思想是衡量候选摘要与真实摘要之间的词语、短语等词汇重叠程度。虽然它是有效的,但最近的研究表明,ROUGE评分与人类如何评估候选摘要的质量并不相关[3,11,44,61]。因此,在改进我们衡量候选摘要质量和摘要体系结构性能的方法方面,我们付出了大量的努力[62,80,81,126,130]。不幸的是,这些工作完全集中在短文档领域,在衡量长文档摘要方法的质量方面一直缺乏进展[3,41,48,89,93]。然而,长文献综述研究领域已经取得了相当大的进展,该领域缺乏一个全面的综述[5,28,32,105]。我们的论文通过对长文档摘要研究的全面概述,以及对其研究设置的三个主要组成部分(基准数据集、摘要模型和评估指标)进行系统评估,填补了这一空白。本文的贡献如下: 全面综述。对长篇文献进行综合综述总结研究文献。
摘要研究综述。文本总结文献主要探讨了研究设置的三个关键方面: 开发先进的模型,发布新的数据集,并提出替代评估指标。我们以经验为基础,在长文档摘要的背景下提供了对所有三个关键组件的详细综述。实证研究与深入分析。为了确保对新兴趋势的广泛覆盖,我们通过细粒度的人的分析和专门的实验对长文档摘要研究设置的每个组件进行了实证分析。未来的方向。讨论了长文档摘要的研究进展,分析了现有方法的局限性,并从模型设计、数据集的质量和多样性、评价指标的实用性以及长文档摘要技术在实际应用中的可行性等方面提出了未来的研究方向。
本研究的组织形式如下: 首先,在第2节对长文档摘要的基本原理进行概述。第三部分对10个摘要基准数据集进行了详细的研究。在第4节中,对专门设计的或有能力总结长文档的摘要模型的全面调查。然后,在第5节中,我们通过专门的实验来分析研究人员常用的不同类型架构的代表模型的性能。在第6节中,我们总结了评估指标及其在长文档摘要领域中的适用性的进展。第7节介绍了长文献摘要模型的应用,第8节讨论了该领域未来的研究方向。最后,第9部分总结了这一综述。
长文档数据集
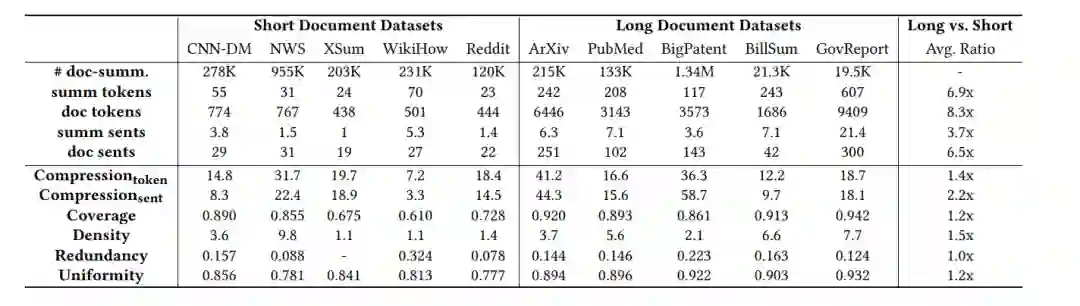
长短文档摘要数据集的比较。内在特征是根据测试样本的平均结果计算的。平均比率是根据长文档相对短文档的平均统计数据计算的。
长文档摘要模型
**
**
表2总结了上面讨论的长文档摘要模型的趋势和发展。在长文档文摘领域中使用的两种典型的基本架构是基于图的无监督抽取模型排序算法和预训练的监督抽象模型Transformer。虽然这两种架构最初都是在较短的文档上提出并测试的,但在合并了新的机制后,它们可以有效地用于总结较长的文档。
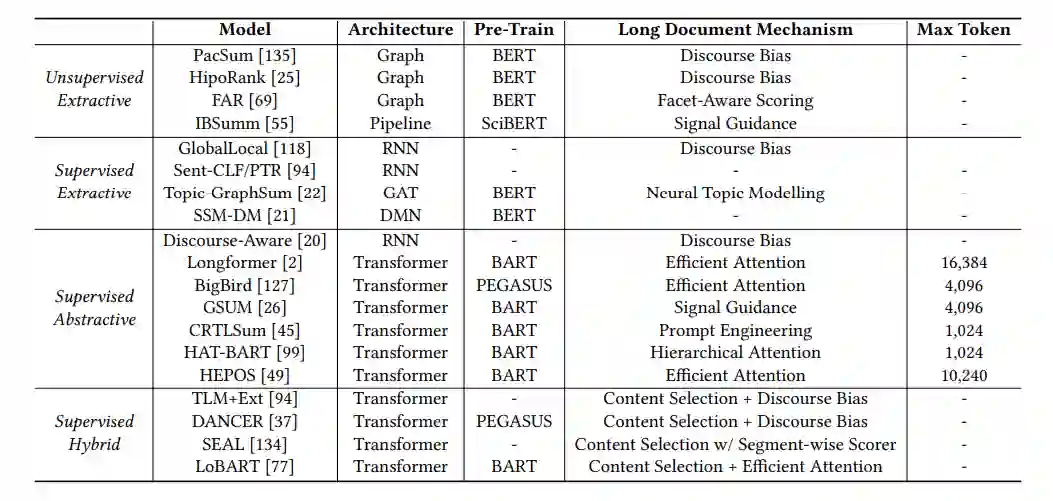
按时间顺序排列的长文档摘要模型。Max token表示模型可以处理的最大输入序列长度,任何超过这个截止点的文本都将被截断。
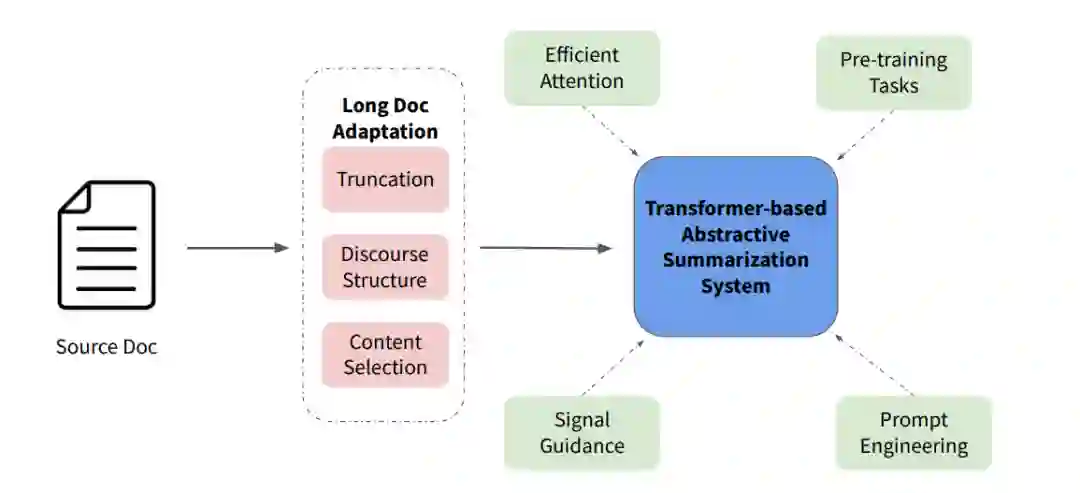
长文档摘要的多维分析
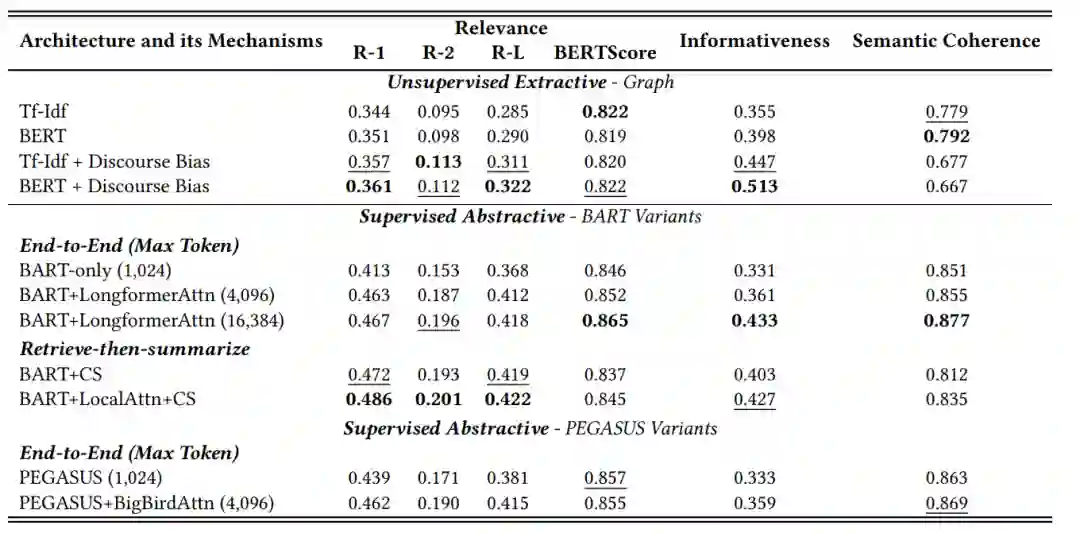
基于图的无监督抽取和基于Transformer的监督抽象的实验结果。最好的结果用黑体字表示,第二高分的结果用下划线表示。Max令牌表示最大输入长度,超过此截止点的文本将被截断。LocalAttn表示本地关注,其中每个令牌只关注其相邻的1024个令牌。LongformerAttn和BigBirdAttn代表Longformer[2]和BigBird提出的有效注意力变体[127]。



