中科院计算所发布首篇「面向第一阶段检索的语义检索模型」综述论文,43页pdf242篇文献

摘要
现代的信息检索系统一般都采用多阶段排序的架构来平衡系统对于效率和性能的需求,其中第一阶段检索重在快速从大规模文档库中返回少量的候选文档,而后续的排序阶段则对这些候选文档进行多轮精排提高系统的性能。在过去的几十年间,研究人员提出了大量的方法来改进重排序阶段模型的性能。然而,第一阶段检索长期以来一直依赖基于词项的传统模型,这类模型通常都面临着词语义失配的问题,使得整个系统在一开始就阻断了潜在相关文档进入后续重排序阶段。近年来,研究人员开始关注面向第一阶段的语义检索模型,并取得了显著的进展。为此,本文对近年来提出的语义检索模型通过一个统一的框架进行了全面的综述,在总结先前工作的同时也对未来的研究方向与挑战性问题进行了探讨,希望能够激发更多关于语义检索模型的研究。
论文地址:https://www.zhuanzhi.ai/paper/bc346fdcd6e47ecc064899a442a21a65
Github地址:https://github.com/caiyinqiong/Semantic-Retrieval-Models (持续更新ing...)
引言
为了平衡搜索的效率和准确性,现代检索系统通常采用多级排序架构:第一阶段检索采用一些计算快捷的排序模型以及专门设计的索引结构从大型文本库中快速返回相关文档的候选集合;之后,多个重排序阶段采用更复杂和有效的排序模型来提升前一阶段输出的相关文档列表。
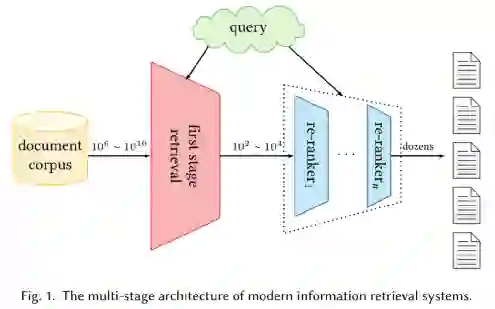
除了多级排序架构,为了实现高效的检索,系统需要对查询和文档进行深入理解,以便能够返回符合用户信息需求的文档。因此,在整个排序架构中都需要构建语义模型,但在不同阶段有不同的需求和目标。对于第一阶段检索,其目标是从整个集合中召回所有可能相关的文档。因此,需要构建能够实现高召回率的高效语义模型,即在短时间内返回尽可能多的相关文档。对于重排序阶段,只有少量文档被输入到排序模型中。因此,用于重排序的语义模型可以采用更复杂的结构来实现高准确度,即将尽可能多的相关文档排在列表的最前面。
在过去几十年,重排序阶段经历了快速的技术转变,排序模型的准确率在变得越来越高的同时,模型复杂度也越来越大。因此,这些模型的计算成本通常都非常高,这使得它们无法被直接应用于第一阶段检索去处理具有大量候选文档的高吞吐量查询。相反,第一阶段检索长期以来一直由基于词项的传统模型所主导。由于其简单的逻辑和强大的索引结构,这种基于词项的模型非常有效,在实践中也取得了良好的召回性能。然而,这种基于词项的模型存在一些明显的缺陷:1)由于词独立性假设,它们容易遭受词汇不匹配问题;2)由于忽略词序信息,它们可能无法很好地捕捉文档语义。由于这些限制,基于词项的检索模型可能会成为整个排序系统的瓶颈,在一开始就阻止相关文档进入重排序阶段。
为了解决这个问题,研究人员提出了一些早期的语义检索模型,如查询扩展、文档扩展、词项依赖模型、主题模型和翻译模型,旨在通过从外部资源或集合本身提取语义单元来改进传统的词袋表示。它们大多仍然遵循基于词项的方法,即在符号空间用高维稀疏向量表示文本,从而能够与倒排索引结合以支持高效检索。然而,这些方法总是依赖手工提取的特征来构建表示函数,只能捕捉较浅的语法和语义信息。尽管如此,这些早期的探索至关重要,因为它们初步验证了对第一阶段检索有利的因素,从而当深度学习技术出现时,可以激发一系列新的语义检索模型,并随之取得令人振奋的研究进展。
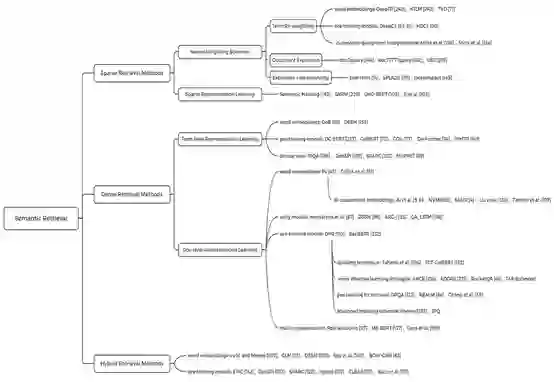
近年来,随着表达学习方法在信息检索领域的发展,研究人员对第一阶段语义检索模型的研究兴趣呈爆炸式增长。自2013年以来,词汇嵌入技术的兴起激发了大量的工作来改进基于词项的检索模型。与离散的符号表示不同,词汇嵌入是一种稠密表示方法,可以在一定程度上缓解词汇不匹配问题。2016年后,将深度学习方法应用于第一阶段检索的技术逐渐成熟,形成了一类神经语义检索模型。神经语义检索方法利用深度学习技术学习表示函数和评分函数。根据表示的计算和存储方式,我们将神经语义检索方法归纳为三种范式,即稀疏检索方法、稠密检索方法和混合检索方法:
稀疏检索方法使用上下文语义重新评估词项权重或将文本映射到“隐词项”空间来改进传统的基于词项的方法。现有实验结果表明,稀疏检索方法确实可以提高第一阶段检索的性能,并且可以很容易地与现有的倒排索引相结合以实现高效检索。此外,这些方法通常表现出良好的可解释性,因为表示的每个维度对应于一个具体的词项或一个隐词项。
稠密检索方法采用双编码器结构来独立地学习查询和文档的低维稠密向量表示,旨在捕获输入文本的全局语义。为了支持在线检索服务,这类方法通常需要借助近似最近邻算法对学习到的表示进行索引和检索。这些方法在几个基准数据集上都取得了显著的结果,并吸引了越来越多的研究人员的注意。
混合检索方法为查询和文档定义多个表示函数,同时获取它们的稀疏表示和稠密表示进行相关性计算。这类方法易于在稀疏检索方法的判别性和稠密检索方法的泛化性之间取得平衡,因此在实际应用中通常表现出更好的性能,但同时也需要更高的空间占用率和检索复杂度。
对于神经语义检索模型的学习,负采样策略是学习高质量检索模型的决定性因素。目前,已经有持续的工作在探索更好的负采样方法,但如何挖掘负文档以实现高效的语义模型学习仍然是一个有待解决的问题。
总结而言,在本文中,我们定义了一个统一的框架来对第一阶段检索方法进行综述,以阐明传统的基于词项的检索方法、早期语义检索方法和神经语义检索方法之间的联系。特别地,我们关注最近的神经语义检索方法,并从模型结构的角度将其归纳为三种范式,即稀疏检索方法、稠密检索方法和混合检索方法。此外,我们还讨论了有关神经语义检索模型学习的关键问题。最后,我们探讨了该领域中尚未解决的挑战,并提出了未来工作的方向。

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SMFR” 就可以获取《中科院计算所发布首篇「面向第一阶段检索的语义检索模型」综述论文,43页pdf242篇文献》专知下载链接






