

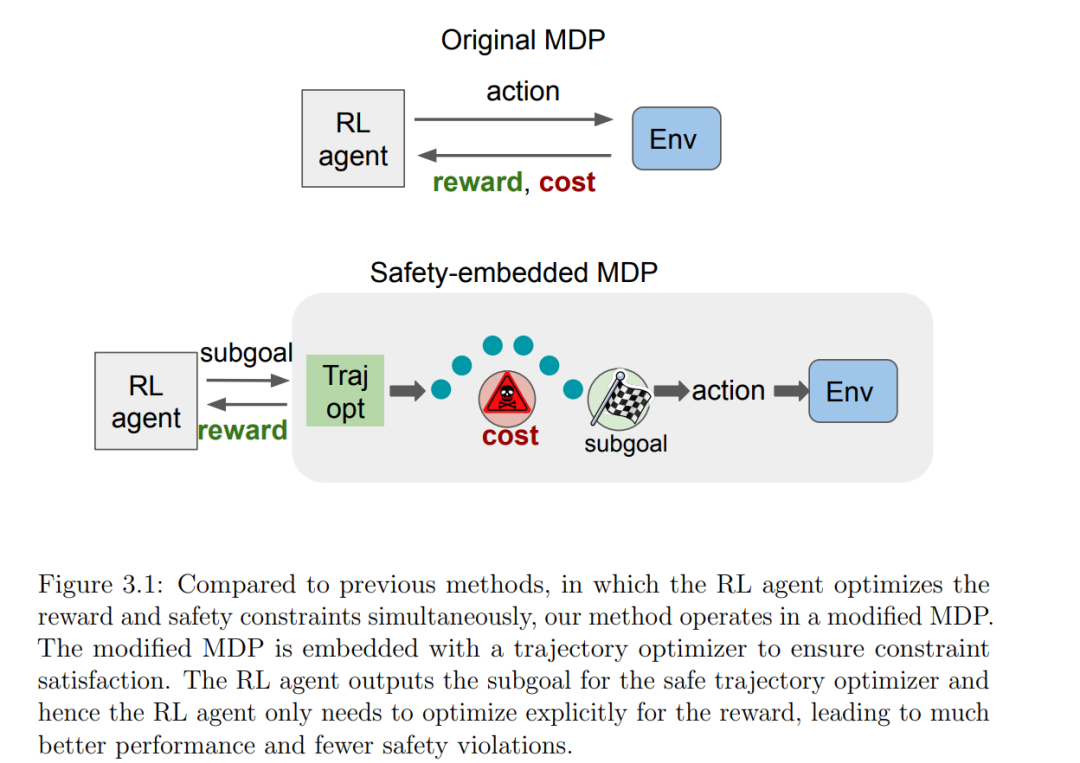
安全强化学习(RL)专注于训练策略以最大化奖励,同时确保安全性。这是将 RL 应用于关乎安全的实际应用的重要步骤。然而,由于需要在最大化奖励和满足安全约束之间取得平衡,安全 RL 存在挑战,这可能导致训练不稳定和过于保守的行为。在这篇论文中,我们提出了两种解决上述安全 RL 问题的方法: (1)我们提出了自我节奏的安全强化学习,它将自我节奏的课程与基础的安全 RL 算法 PPO-Lagrangian 结合在一起。在训练过程中,策略从简单的安全约束开始,逐渐增加约束的难度,直到满足所需的约束。我们在 Safety Gym 基准上评估了我们的算法,并证明了课程有助于底层安全 RL 算法避免局部最优,提高了奖励和安全目标的性能。 (2)我们提出在一个修改过的 MDP 中学习策略,在这个"嵌入了安全性约束的 MDP"中,RL 代理的输出被转换成一系列的动作,这些动作通过一个轨迹优化器进行转换,确保在机器人当前处于安全和准静态配置的情况下是安全的。我们在 Safety Gym 基准上评估了我们的方法,并展示了我们在训练期间获得的奖励显著高于以前的工作,同时也少有安全性违规;而且,我们在推理期间没有任何安全性违规。我们还在真实的机器人推箱子任务上评估了我们的方法,并证明了我们的方法可以在现实世界中安全地部署。


成为VIP会员查看完整内容
相关内容
Arxiv
21+阅读 · 2023年5月22日
Arxiv
42+阅读 · 2023年4月19日
相关VIP内容
相关资讯
相关论文
Arxiv
21+阅读 · 2023年5月22日
Arxiv
42+阅读 · 2023年4月19日