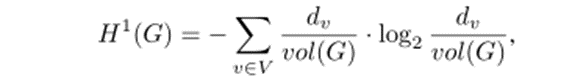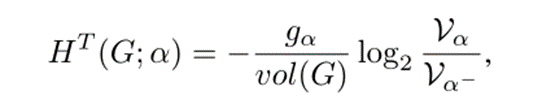来源|北京航空航天大学-李昂生、彭浩老师团队
排版|OpenDeepRL
**
**
结构信息原理指导的基于角色发现的高效稳定多智能体协作
多智能体强化学习(MARL)目前广泛应用于各种复杂决策,如游戏对抗、传感器网络、社交网络、紧急工具使用等。而协作MARL则面临两个重大挑战:联合状态动作空间随着智能体数量呈指数级增长的可扩展性局限,以及由于通信限制导致的部分可观察性,这均需要基于局部动作观察历史的去中心化智能体决策。近日,来自北京航空航天大学的曾祥华、彭浩、李昂生研究团队,基于结构信息原理,提出了一种更加高效稳定的多智能体协作框架,该框架利用最优编码树实现自适应、无监督的角色发现,SIRD,且该过程不需要任何的人工协助,并将整个MARL框架命名为SR-MARL。不同于已有的平面聚类方法(RODE),其核心思想在于,将多智能体之间角色发现建模为联合动作空间的层次化结构发现问题,并使用最优编码树实现了决策过程中的角色结构的层次化表示,包含角色、子角色及个体等。 成果发表在国际会议AAAI2023上,论文地址:https://doi.org/10.48550/arXiv.2304.00755
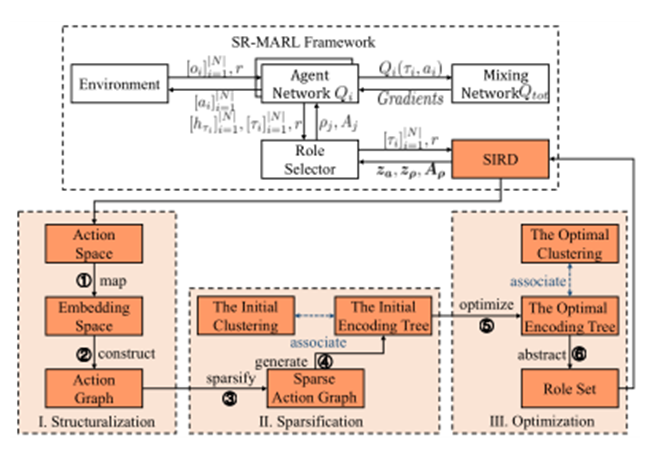
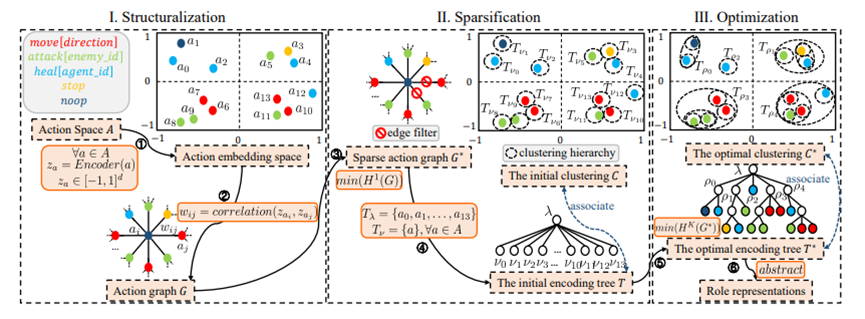
SR-MARL框架图
摘要
角色学习多智能体强化学习(MARL)是提高决策性能的一种有效的方法,然而,如果没有人工协助,当前方法无法保证稳定地发现角色来有效实现复杂任务分解,因为其对于预定义的角色结构或相关超参数设置依赖实际经验。因此,该项工作提出了一种基于结构信息原理的角色发现方法,即SIRD,将其应用于多智能体协作场景并提出了框架SR-MARL。其中,SIRD方法将角色发现转换为联合动作空间的层次化结构发现问题,并由结构化、稀疏化和优化三大模块组成,最终生成最优编码树,在树节点上定义动作抽象函数以完成角色发现。此外,SR-MARL是一种通用性框架,并可以与各种值函数分解的MARL算法灵活集成,以显著提升原始算法的决策性能。在星际争霸II场景下的大量经验评估表明,与最先进的MARL算法相比,在简单、困难和超困难的任务设置下,SR-MARL框架将平均测试获胜率分别提高了0.17%、6.08%和3.24%,并将偏差分别降低了16.67%、30.80%和66.30%。
介绍
协作MARL算法面临两个重大挑战:联合状态动作空间随着智能体数量呈指数级增长的可扩展性局限,以及由于通信限制的部分可观察性,这需要基于局部行动观察历史的去中心化决策。因此,中心化训练与去中心化执行的范式被提出,旨在应对上述挑战。然而,中心化训练依然需要在联合状态动作空间中搜索智能体策略,并未从根本上解决上述问题。一个有效的解决方案是集成角色学习以分解多智能体系统中的总体任务,其中每个角色都与一个特定的子任务和一个限制在状态动作子空间中的角色策略相关联。其关键在于如何提出一组角色来有效地分解协作任务。预先定义任务分解或角色等先验结构的典型方法需要实践中无法获得的先验知识,因此实用性较差。而从零开始自动学习一组合适的角色也是不切实际的,这等价于在联合状态动作空间中进行大量探索。取代从零开始的角色学习,RODE算法利用DBSCAN对联合动作空间进行聚类,将每个动作类定义为一种角色,从而实现角色发现。然而,其性能高度依赖于聚类参数,导致稳定性表现不佳。综上所述,由于实际的任务分解结构并不总是事先定义好的或是随时间动态变化的,因此当前基于角色学习的方法在缺少人工协助的前提下无法保证复杂决策人物中角色发现的有效性。
结构信息原理
利用一维结构熵最小化原理来稀疏动作图,以生成初始编码树。最小化稀疏图的K维结构熵以获得最优编码树,从而实现分层动作空间聚类。此外,将最优编码树上的分层聚类作为角色发现操作的分层抽象。SIRD独立于手动辅助,并与各种值函数分解方法灵活集成。
①结构熵
在结构信息原理中,结构熵在分层划分策略下动态测量复杂图的不确定性,并通过最小化结构熵,生成目标图的最优层次结构,即最优编码树。假设给定一个加权无向图G=(V,E,W),V是顶点集,E是边集,W是权重函数。设n=|V|为顶点数,m=|E|为边数。对于每个顶点v∈V,其度dv被定义为其连接边的权重之和。则加权无向图G的编码树、一维和K维结构熵的定义如下。``` 编码树: 图G的编码树是一个有根树,定义如下: 1)对于每个节点α∈T,G中存在一个顶点子集Tα对应于α,Tα⊆V。 2)对于根节点λ,设置Tλ=V。 3)对于每个节点α∈T,将其子节点标记为α∧⟨i⟩,随着i的增加从左到右排序,并且α∧-=α。 4) 对于每个节点α∈T,L假定为其子节点的数量;则所有顶点子集Tα∧⟨i⟩是不相交的,并且Tα=ULi=1Tα∧。 5) 对于每一个叶节点v,Tv是一个包含图顶点的单例子集。
**一维结构熵**
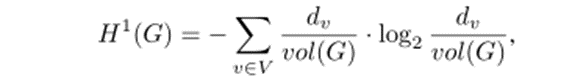
**K维结构熵** 对于每个节点α∈T,α̸≠λ,其分配的结构熵定义为:
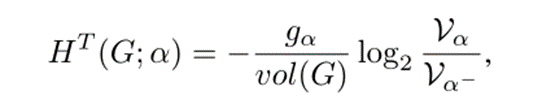
给定编码树T,G的K维结构熵定义为:

基于结构信息原理的角色发现
### ②由SIRD方法优化的MARL框架SR-MARL
SR-MARL由五个模块组成,包括环境、代理网络Qi、混合网络Qtot、角色选择器和角色发现模块SIRD。在总体框架中,每个智能体ni基于个体网络Qi做出决策,该网络Qi将部分观测oi和联合奖励r作为输入,并由QPLEX混合网络Qtot更新。混合网络Otot可以获得全局观测信息以对所有智能体进行集中训练。除了做出决策外,个体网络Qi还将局部动作观测历史τi编码为d维嵌入向量hτi∈Rd,然后将其输入角色选择器。角色发现模块SIRD则将所有智能体的动作观察历史和联合奖励作为输入,并向角色选择器输出动作表示za、角色表示zρ和受限动作空间Aρ,用于学习角色策略。受RODE的启发,角色选择器基于角色表示zρ和隐藏向量hτi之间的点积,将角色ρj∈Ψ及其对应的动作子空间Aj∈Aρ分配给智能体ni。
## 角色发现模块SIRD
SIRD包括结构化、稀疏化和优化等模块。在结构化中,动作空间被映射到一个固定维度的嵌入空间,并基于动作功能相关性构造一个完全动作图。在稀疏化中,对动作图进行稀疏化,并生成稀疏图的初始编码树。在优化中,对编码树进行优化,以发现联合动作空间的层次化结构,即最优编码树,并在最优编码树上定义抽象函数以实现角色发现。
### 结构化:
与现有的基于角色的方法不同,SIRD利用动作功能相关性来构建动作图,以提高角色发现的有效性。为此,对于每个动作,借助编解码结构来学习其对于实现团队目标功能性表示,测量动作表示之间的皮尔逊相关系数,进而构建一个加权、无向的完全图。
### 稀疏化:
为了降低整个过程的计算成本并消除完全图中无效动作关系的负面干扰,需要对动作图进行稀疏化,最小化完全图的一维结构熵,将其转化为k最近邻图,即对于每个动作仅选择与其功能性相似度最高的k个动作进行保留,作为其邻居图节点,具体过程如算法1所示。

**优化:** 为了获得联合动作空间A的最优层次化结构C,需要将稀疏动作图G的编码树T从1层优化到K层。首先,从deDoc中引入了两个算子,合并算子和组合算子,设计一种迭代贪心算法,以最小化稀疏图G*的K维结构熵,从而优化T。具体优化算法如算法2所示。

## 实 验
### 数据集
在星际争霸II(SMAC)基准上评估了SR-MARL,包括五个简单地图、四个困难地图和五个超困难地图,其中困难地图和超困难地图通常是需要智能体学习复杂协作策略的探索任务
### 基线和变量
为了使实验对比结果更具说服力,我们将SR-MARL与最先进的MARL算法进行了比较,包括QMIX、QPLEX、QTRAN、RODE等。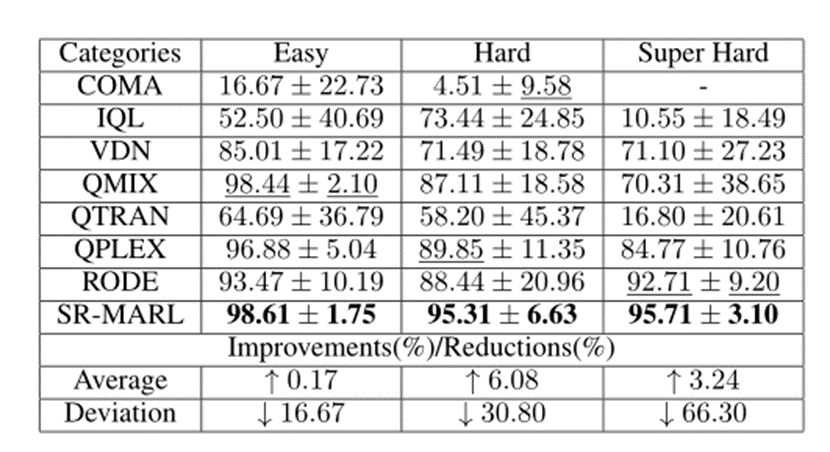
不同地图类别下的测试胜率汇总
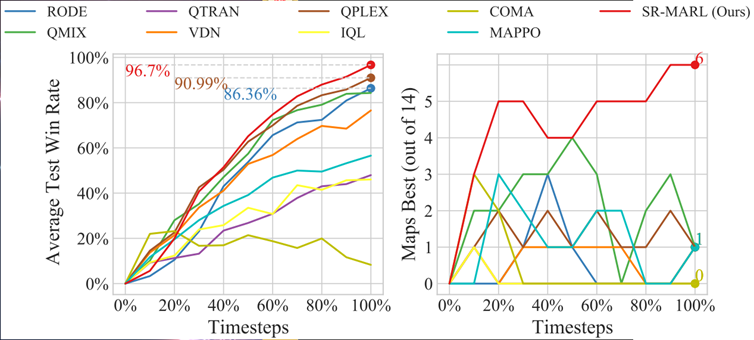
所有14个平均测试获胜率与算法平均测试获胜率最高的地图数量
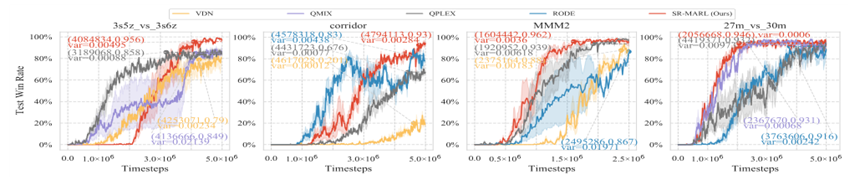
四张SMAC超难地图的平均测试获胜率
###
### 通用性能力
SR-MARL对是一种通用性框架,并且可以通过替换其中混合网络Qtot来与各种值函数分解的MARL算法相结合。我们将SR-MARL分别与QMIX和QPLEX算法结合,获得SR-QMIX和SR-QPLEX模型,并测试它们的性能。
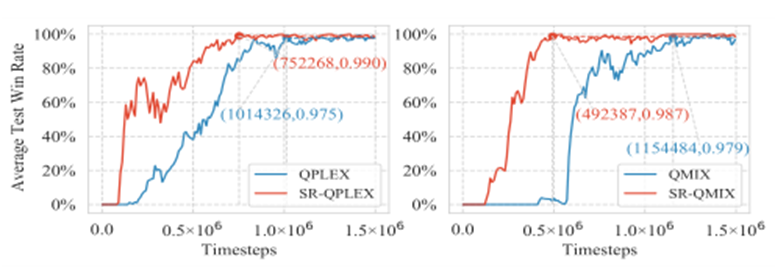
与价值分解方法QMIX和QPLEX集成的SR-MARL的平均测试获胜率
## 结 论
该项工作提出了一种基于结构信息原理的角色发现方法SIRD,以及一个用于多智能体协作的MARL框架SR-MARL。在SMAC基准中挑战性任务的评估表明,SR-MARL在有效性和稳定性方面均明显优于最先进MARL算法,并具有优秀的通用性。