

大规模语言模型(LLM)已彻底改变了人工智能领域,并成为许多任务的事实标准工具。目前,LLM的主流技术是基于标记级别处理输入并生成输出。这与人类的处理方式截然不同,人类在多个抽象层次上操作,远远超出了单词层级,以分析信息并生成创造性内容。本文提出了一种尝试,设计了一种在显式更高层次语义表示上操作的架构,我们将其命名为“概念”。概念是语言和模态无关的,表示流中的一个更高层次的思想或动作。因此,我们构建了一个“大型概念模型”(Large Concept Model)。 在本研究中,作为可行性证明,我们假设一个概念对应于一个句子,并使用现有的句子嵌入空间——SONAR,该空间支持多达200种语言,包括文本和语音模态。大型概念模型被训练为在嵌入空间中执行自回归句子预测。我们探索了多种方法,包括均方误差(MSE)回归、扩散生成模型的变种以及在量化SONAR空间中操作的模型。这些探索使用了16亿参数的模型和大约1.3万亿标记的训练数据。随后,我们将一种架构扩展到具有70亿参数的模型,并使用大约2.7万亿标记的训练数据。我们在几个生成任务上进行了实验评估,主要包括摘要生成和一种新的任务——摘要扩展。最后,我们展示了我们的模型在零-shot泛化性能上展现出令人印象深刻的表现,超越了同等规模的现有LLM。我们的模型训练代码是开放的。
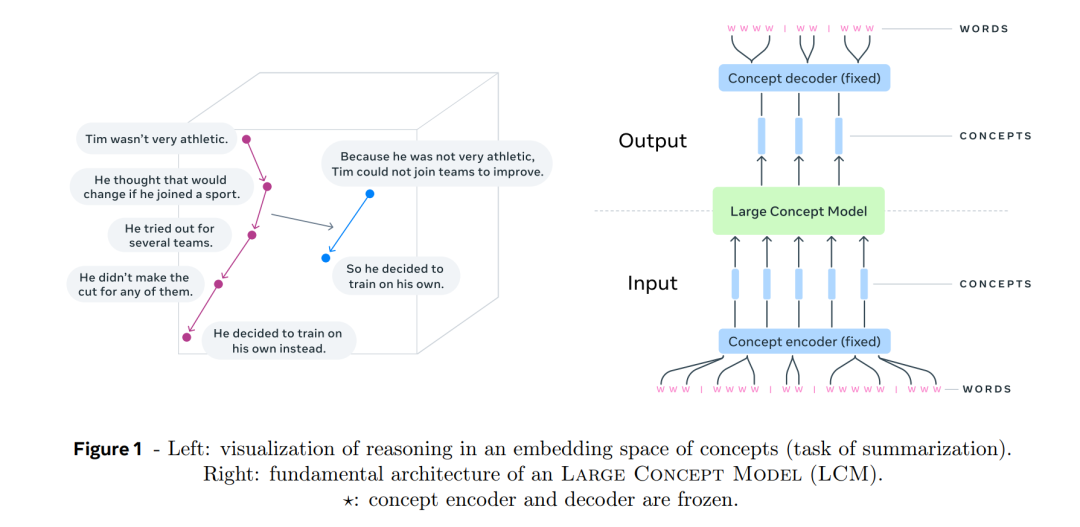
大规模语言模型(LLM)正在主导当前的自然语言处理研究,并且随着它们最近扩展到更多模态,如图像、视频和语音,它们似乎被视为接近人类智能的事实标准技术。LLM在各种任务上取得了令人印象深刻的表现,例如提供详细的常识问题答案、帮助进行长文档分析、撰写不同类型的消息或编写和调试代码。从零开始构建一个LLM需要巨大的计算资源,以处理越来越大量的数据并训练参数超过四千亿的模型。LLM的知识获取高度依赖数据,扩展到更多语言或模态通常需要注入额外的(合成)数据来涵盖它们。 目前可用的LLM可以分为开放模型(如Llama(Llama团队,2024)、Mistral(Jiang等,2024)、Bloom(BigScience Workshop,2023)或Falcon(Almazrouei等,2023))和封闭模型(如Gemini(Gemini Team Google,2024)、GPT(OpenAI,2024)或Claude(Anthropic,2024))。值得注意的是,所有这些模型都基于相同的基础架构:一种基于Transformer的解码器语言模型,经过预训练以根据前面的上下文预测下一个标记。尽管LLM取得了不可否认的成功并持续进展,但当前所有的LLM都缺少人类智能的一个关键特征:在多个抽象层次上的显式推理和规划。人脑并不是仅仅在单词层面操作。我们通常有一个自上而下的过程来解决复杂任务或撰写长文档:我们首先在更高的层次上规划整体结构,然后一步步在更低的抽象层次上添加细节。可以说,LLM隐式地在学习一种层次化表示,但我们认为具有显式层次化架构的模型更适合生成连贯的长篇输出。 想象一下,研究人员正在做一个十五分钟的演讲。在这种情况下,研究人员通常不会通过写出每一个将要说的字来准备详细的演讲稿。相反,他们会概述他们想要传达的更高层次的想法。如果他们多次进行相同的演讲,实际说出的词语可能会有所不同,演讲甚至可以用不同的语言进行,但更高层次的抽象想法的流程将保持不变。类似地,当撰写关于某一特定主题的研究论文或文章时,人类通常会首先准备一个大纲,将整篇文章分成若干部分,然后逐步细化。在处理和分析信息时,人类很少会逐字考虑一篇长文档中的每个单词。相反,我们使用一种层次化的方法:我们记住应该在哪个部分查找特定信息。 据我们所知,这种在抽象层次上、独立于特定语言或模态的显式层次结构在当前的LLM中并不存在。在这项工作中,我们提出了一种新的方法,摆脱了在标记级别处理的方式,转而更接近于在抽象嵌入空间中的(层次化)推理。这个抽象嵌入空间的设计目标是独立于内容所表达的语言或模态;换句话说,我们旨在在纯粹的语义层面建模潜在的推理过程,而不是它在特定语言中的实例化。为了验证我们的方法,我们将研究限制在两个抽象层次:子词标记和概念。我们将概念定义为一个抽象的原子思想。在实践中,概念通常对应于文本文档中的一个句子,或等效的语音表述。我们认为,句子是实现语言独立性的合适单位,而不是单个词。这与当前的LLM技术形成鲜明对比,后者严重依赖英语和标记。 我们的基本思路可以基于任何固定大小的句子嵌入空间,只要该空间有编码器和解码器可用。特别是,我们可以目标训练一个专门优化为我们推理架构的新的嵌入空间。在这项工作中,我们选择了一个现有的、免费提供的句子嵌入——SONAR(Duquenne等,2023b)。SONAR支持200种语言的文本输入和输出,支持76种语言的语音输入,并且支持英语的语音输出。我们在第2.1节讨论了这一选择的约束和影响,并在第6节分享了一些关于替代嵌入空间的思路。 图1左侧展示了在嵌入空间中的推理,举了一个摘要任务的例子,该任务通过嵌入空间中的函数实现,将五个概念表示映射为两个。图1右侧总结了整体架构和处理流程。输入首先被分割成句子,并使用SONAR对每个句子进行编码,从而得到一系列概念,即句子嵌入。然后,这一系列概念通过大型概念模型(LCM)处理,在输出端生成新的概念序列。最后,生成的概念通过SONAR解码成一个子词序列。编码器和解码器是固定的,并且不进行训练。需要强调的是,LCM输出端不变的概念序列可以解码成其他语言或模态,而无需重新进行整个推理过程。本着同样的理念,像摘要这样的推理操作可以在零-shot设置下对任何语言或模态的输入进行处理,因为它仅仅操作概念。总之,LCM既不具有输入语言或模态的信息,也不生成特定语言或模态的输出。我们探索了多种架构来训练LCM,特别是多种扩散变体。最后,我们设想在概念之上可能存在的另一个抽象层次,这可能对应于对一段或小节的简短描述。在第4.3节中,我们报告了关于如何调整和预测更高层次表示来提高LCM生成输出一致性的一些初步想法。 在某种程度上,LCM架构类似于Jepa方法(LeCun,2022),该方法也旨在预测嵌入空间中下一个观测的表示。然而,不同于Jepa更侧重于以自监督方式学习表示空间,LCM专注于在现有嵌入空间中的准确预测。我们的通用大型概念模型方法的主要特点如下:
-
在超越标记的抽象语言和模态无关层次上的推理:
-
我们建模的是潜在的推理过程,而不是它在特定语言中的实例化。
-
LCM可以在所有语言和模态上同时进行训练,即获取知识,承诺在无偏的方式下具有可扩展性。
-
显式层次结构:
-
提高长篇输出的可读性。
-
便于用户进行本地交互编辑。
-
处理长上下文和长篇输出:
-
基本的Transformer模型的复杂度随着序列长度的增加呈二次增长,这使得处理大上下文窗口具有挑战性,因此开发了多种技术来缓解这一问题,如稀疏注意力(Child等,2019)或LSH注意力(Kitaev等,2020)。我们的LCM处理的序列至少比传统方法短一个数量级。
-
无与伦比的零-shot泛化能力:
-
无论LCM是在何种语言或模态上预训练和微调,它都可以应用于SONAR编码器支持的任何语言和模态,而无需额外的数据或微调。我们报告了多种语言文本模态下的结果。
-
模块化和可扩展性:
-
与可能会受到模态竞争影响的多模态LLM不同(Aghajanyan等,2023;Chameleon团队,2024),概念编码器和解码器可以独立开发和优化,避免任何竞争或干扰。
-
新的语言或模态可以轻松添加到现有系统中。
本文的目标是提供这一高层愿景的概念验证,作为当前语言建模最佳实践的替代架构。在接下来的部分中,我们将介绍我们模型的主要设计原则,并讨论构建和训练大型概念模型的几种变体。我们将讨论实现扩散方法的几种设计,并仔细研究噪声调度。本节最后,我们将与基于标记的LLM进行计算复杂度的比较。第3节专门讨论一个更大规模的70亿参数模型。我们讨论了在多个生成任务上对该模型进行指令微调时遇到的挑战,并提供了与同规模现有LLM的比较。文章最后讨论了相关工作、我们方法的当前局限性和展望。 为了促进该领域的研究,我们将公开LCM训练代码以及SONAR编码器和解码器,支持最多200种语言和多种模态。
