
摘要: 超大预训练模型(Pre-trained model, PTM)是人工智能领域近年来迅速崛起的研究方向, 在自然语言处理和计算机视觉等多种任务中达到了有史以来的最佳性能, 促进了人工智能生成内容的发展和落地. ChatGPT作为当下最火热的PTM, 更是以优异的表现获得各界的广泛关注. 本文围绕ChatGPT展开. 首先概括了PTM的基本思想并对其发展历程进行了梳理; 接着, 详细探讨了ChatGPT的技术细节, 并以平行智能的视角阐述了ChatGPT; 最后, 从技术、范式以及应用等多个方面对PTM的发展趋势进行了展望.
2022年底, 一款名为ChatGPT (Chat generative pre-trained Transformer)的人工智能聊天程序引爆全球, 成为了各行业关注的焦点. ChatGPT火热之余, 不禁让众人思考: ChatGPT有何奥秘? “ChatGPT是一种基于人工智能的自然语言处理技术, 能够根据给定的问题和语境生成符合语言习惯和逻辑的回答. 这种技术可以应用于各种领域, 如客服、智能助手、教育、医疗等, 能够帮助人们更方便、高效地获取所需信息. 当前, ChatGPT在各个领域的应用越来越广泛, 因为它可以实现智能化、个性化、高效化的服务, 得到了广大用户的认可和喜爱. 随着技术的不断进步和完善, ChatGPT在处理语言难度、语境理解、知识获取和表达等方面都得到了不断的提升, 使得它在应用领域的效果和准确度都越来越好. 因此, 当下ChatGPT的火热现象主要是因为它能够提供高效便捷的智能服务, 并且在技术上不断突破和进步, 能够越来越好地满足人们的需求. 同时, 随着ChatGPT技术的发展, 它还将继续在各个领域发挥重要作用, 成为人们生活中不可或缺的一部分.”①就这些问题, ChatGPT自己如是说道. 由ChatGPT的回答, 我们不难发现ChatGPT的论述条理清晰、井然有序, 更难得的是符合大众日常的语言习惯, 这让上述问题的答案不言而喻. ChatGPT的横空出世势必会给各行业带来巨大的冲击和挑战, 同时也意味着新机遇的诞生. 因此, 人们需对ChatGPT有全面且深刻的认识.
ChatGPT属于自然语言处理(Natural language processing, NLP)领域的超大预训练模型(Pre-trained model, PTM)[1-2], 这类超大PTM也称基石模型(Foundation model)[3, 4]、大模型(Large/big model)[5-7]. 简单来说, 超大PTM旨在设计具有超大参数量的深度神经网络(Deep neural network, DNN), 在海量未标记的数据上对其进行训练. 利用超大参数量DNN强大的函数近似能力, 预训练可使超大PTM在这些海量数据上提取共性特征. 再根据下游任务, 对超大PTM进行微调(Fine-tune)或上下文学习(In-context learning), 使最终的模型可在具有一定相关度但不同的任务中获得优异的表现. 目前, 国内外众多科研机构、公司研发的超大PTM已在各领域取得了巨大的突破, 引领了新一轮的人工智能科技竞赛.
为进一步推进以ChatGPT为代表的超大PTM技术的发展和应用, 加速人工智能生成内容(Artificial intelligence-generated content, AIGC)落地, 本文首先梳理了超大PTM的经典模型, 并进行简要介绍. 其次, 详细地介绍了ChatGPT中的关键技术——Transformer, 探讨了ChatGPT的设计与实现, 同时以平行智能的视角解读了ChatGPT. 在综合分析ChatGPT和其他PTM的基础上, 我们进一步从技术、生态、范式以及应用等多个方面探讨了超大PTM的发展趋势.
ChatGPT的设计与实现
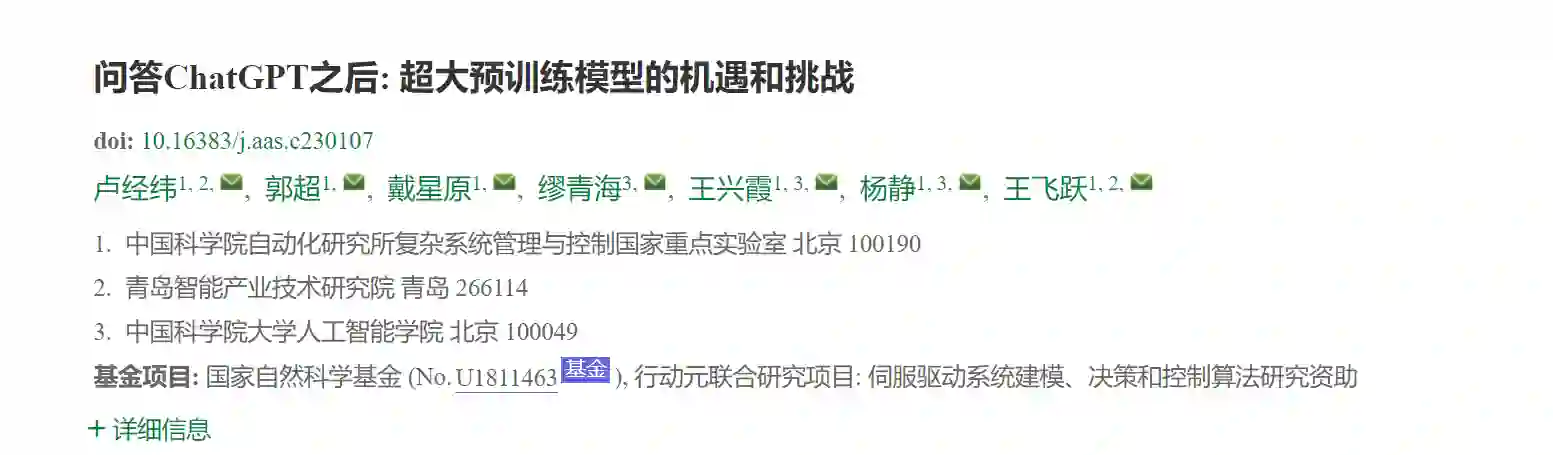
如前所述, ChatGPT的出色表现得益于其成功地引入了人类的价值偏好. 不同于其他PTM, ChatGPT采用RLHF的方式将人类的语言习惯引入模型中, ChatGPT实现的基本流程如图4所示, 可大致分为如下4步:
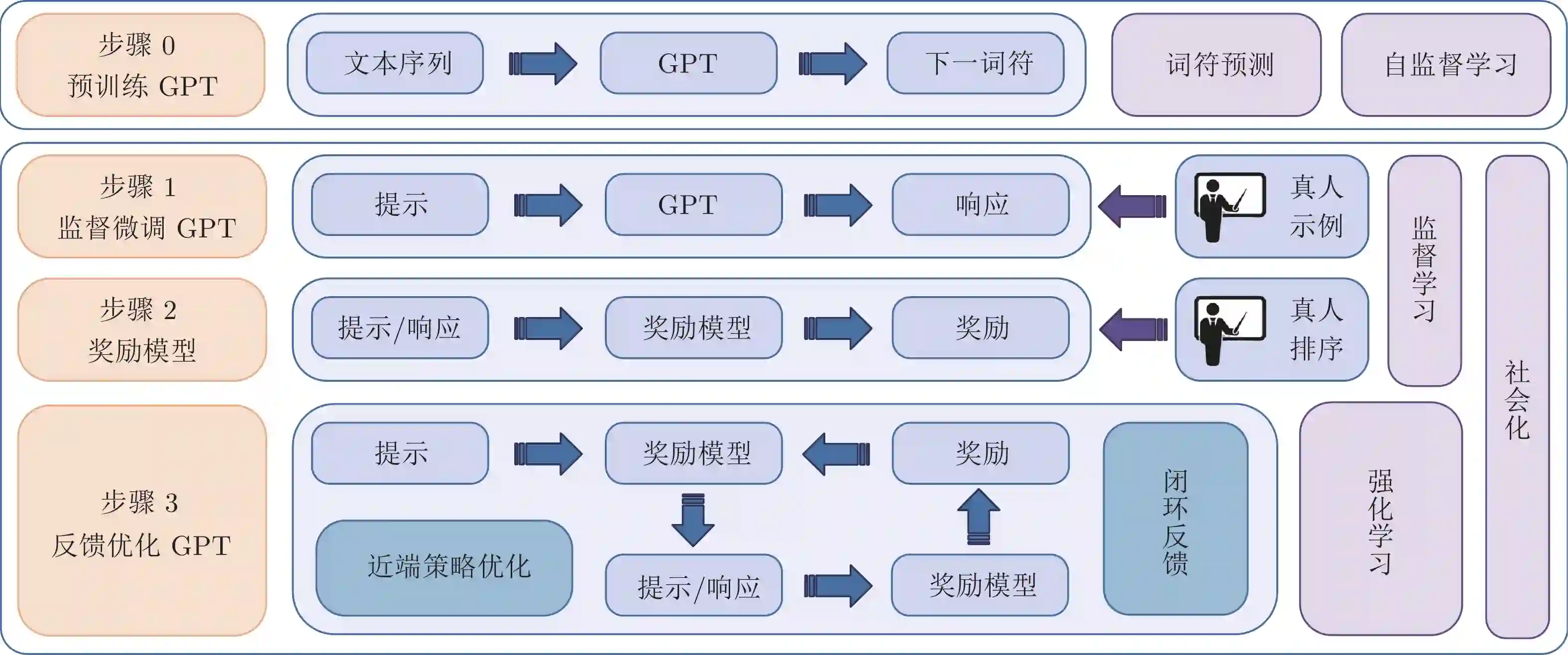
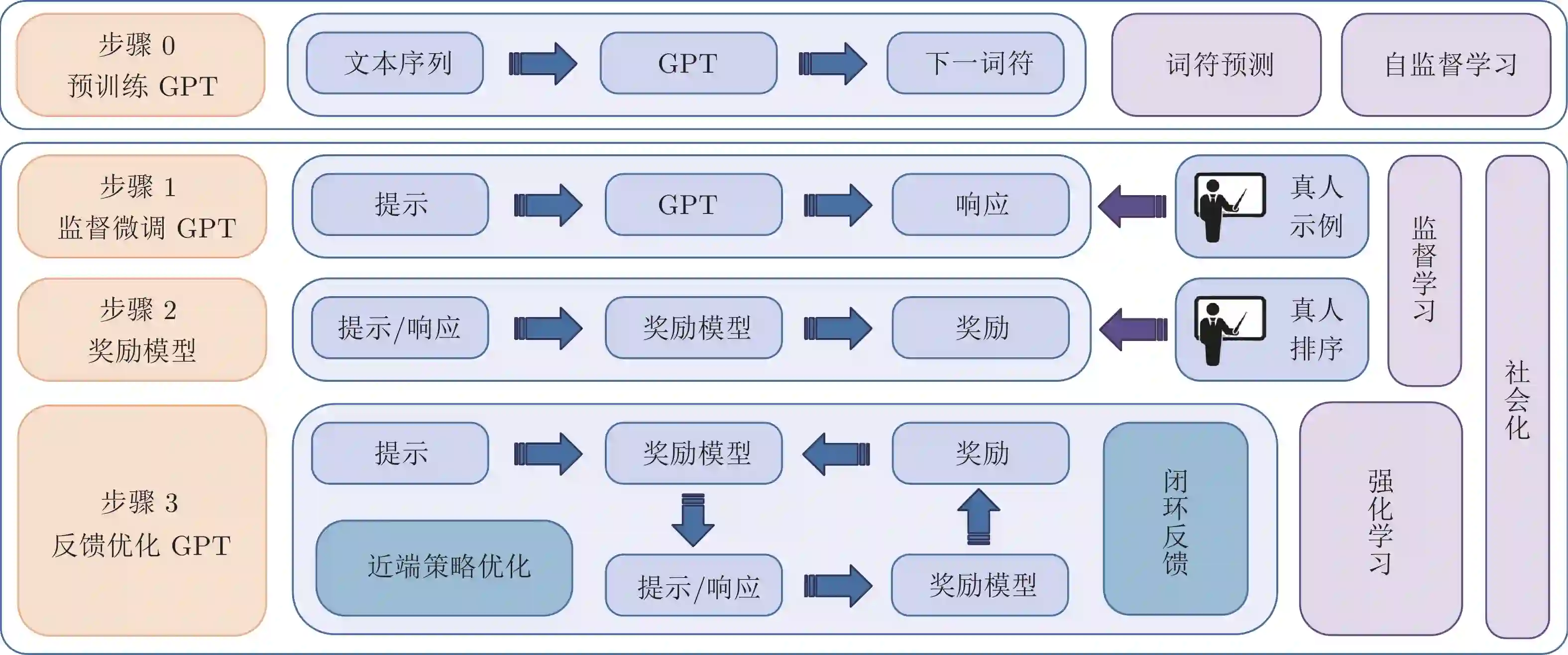
步骤0: 预训练GPT. 基于大规模语料库, 以自监督学习的方式预训练GPT模型. 使GPT在大规模语料库上提取自然语言共性特征.
步骤1: 监督微调(Supervised fine-tuning) GPT. 基于真人标注偏好的答案初步引入真人价值偏好, 根据人工示例监督微调GPT.
步骤2: 奖励模型(Reward model)设计. 基于真人对模型输出排序的数据, 监督训练获得奖励模型, 使奖励模型学习到真人的价值偏好.
步骤3: RL反馈优化GPT. 基于奖励模型并采用近端策略优化(Proximal policy optimization, PPO)算法[38], 闭环反馈优化监督微调后的GPT, 获得ChatGPT.
经步骤0后的GPT, 在具体任务上表现并不一定出色, 但已具备相当潜力, 通过微调或者上下文学习的模式即可在多种任务中获得优异表现. 步骤0的介绍可参考上一节. 而步骤1至步骤3是ChatGPT的关键步骤, 这些步骤成功地将人类因素引入了GPT中. 换一个角度来看, 步骤1至步骤3也是RL的标准流程.

