

深度神经网络(DNNs)使计算机能够在许多不同的应用中脱颖而出,如图像分类、语音识别和机器人控制。为了加快DNN的训练和服务,并行计算被广泛采用。向外扩展时,系统效率是一个大问题。在这次演讲中,我将对分布式DNN训练和服务中更好的系统效率提出三个论点。
首先,对于模型同步,Ring All-Reduce不是最优的,但Blink是。通过打包生成树而不是形成环,Blink可以在任意网络环境中实现更高的灵活性,并提供近乎最优的网络吞吐量。Blink是一项美国专利,目前正在被微软使用。Blink获得了许多业内人士的关注,比如Facebook(分布式PyTorch团队)、字节跳动(TikTok应用的母公司)。Blink还登上了英伟达GTC中国2019以及百度、腾讯等的新闻。
其次,通过sensAI的类并行性可以消除通信。sensAI将多任务模型解耦到断开的子网中,每个子网负责单个任务的决策。sensAI的低延迟、实时模式服务吸引了湾区的几家风险投资公司。
第三,小波变换比分组调度更有效。通过有意地增加任务启动延迟,小波变换在加速器上不同训练波的内存使用峰值之间交错,从而提高了计算和设备上的内存使用。
【伯克利Guanhua Wang博士论文】分布式机器学习系统的颠覆性研究





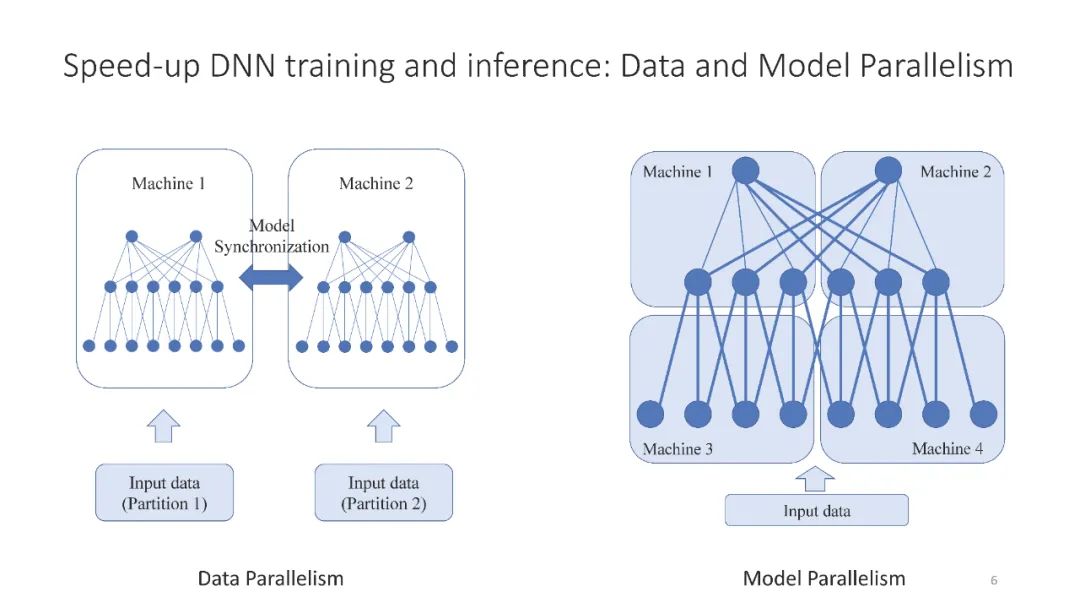
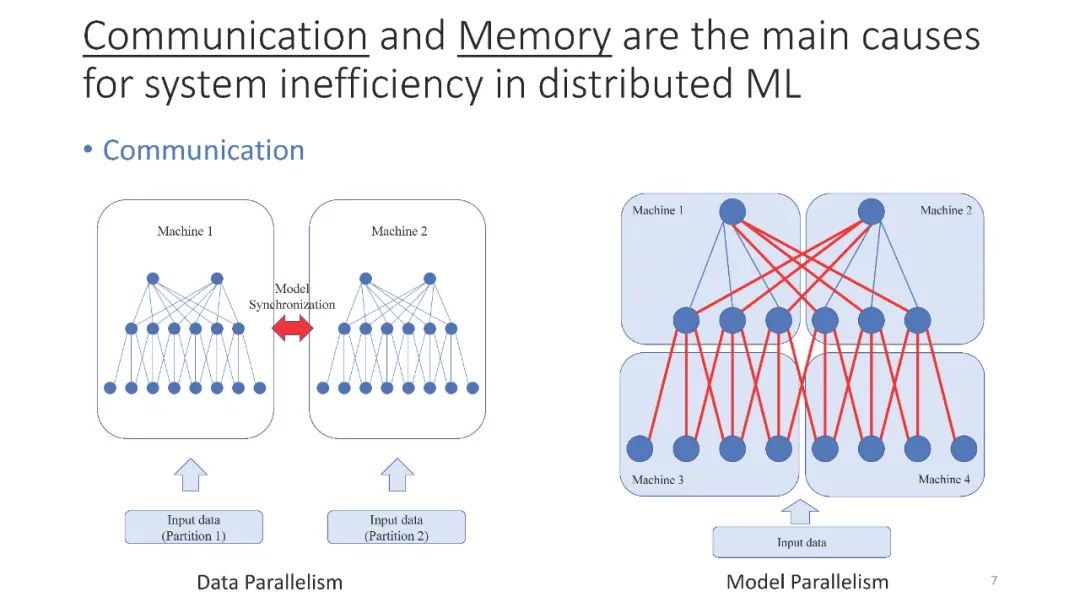
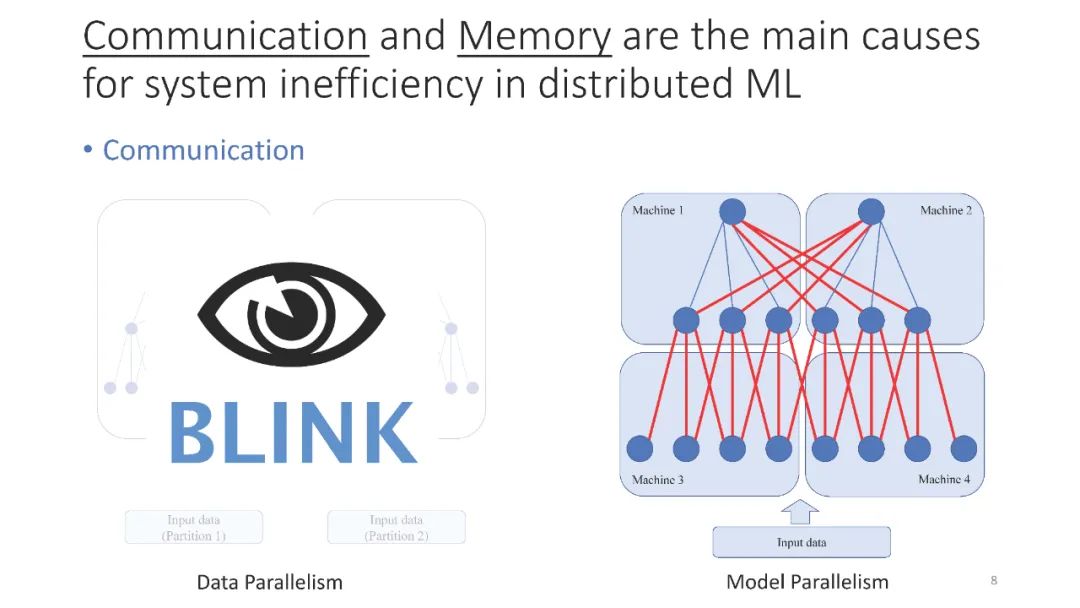

成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年8月25日
Arxiv
10+阅读 · 2018年3月20日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年8月25日
Arxiv
10+阅读 · 2018年3月20日