干货:手把手教你在音频分类DCASE2017比赛中夺冠
“全球人工智能”拥有十多万AI产业用户,10000多名AI技术专家。主要来自:北大,清华,中科院,麻省理工,卡内基梅隆,斯坦福,哈佛,牛津,剑桥...以及谷歌,腾讯,百度,脸谱,微软,阿里,海康威视,英伟达......等全球名校和名企。
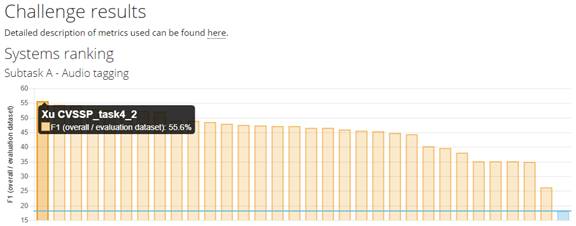
最新消息:来自英国萨里大学的团队徐勇博士等夺得DCASE2017 challenge比赛冠军。战胜来自CMU, New York University, Bosch, USC, TUT, Singapore A* Star, KoreanAdvanced Institute of Science and Technology, Seoul National University andNational Taiwan University等学校的竞争对手有。下面手把手教你在音频分类DCASE2017比赛中夺冠:
随着人工智能和深度神经网络在图像,视频,和语音等领域的大火,AI在音频领域,包括场景分类,音频事件检测,网络音视频的应用需求也越来越多。DCASE是音频场景,音频事件的分类与检测的简称。DCASE的应用场景十分广泛,如智能家居,无人驾驶,复杂场景中的语音识别等。DCASE比赛是目前世界范围内最大规模的音频分类与检测比赛[1],地位如同图像分类领域的ImageNet。本团队此次斩获音频标签第一名和弱监督声学事件检测第二名。下面就上夺冠历程的“干货”,包括模型的选择,trick的重要性。并发布可以一键run的代码。

DCASE (Detection and Classification ofAcoustic Scenes and Events)是由IEEE AASP授权的比赛,今年已举办第三届,由CMU,法国INRIA,芬兰Tampere科技大学共同举办。Google和Audio Analytic(位于英国剑桥的音频处理公司)共同赞助。
本次比赛有四个任务:声音场景分类,稀有事件检测,现实场景中的声学事件检测,和无人驾驶中的大规模弱监督声学事件检测。本团队参与了第四个任务:无人驾驶中的大规模弱监督声学事件检测,其中包含(a) 音频标签和 (b)弱监督声学事件检测两个子任务。此任务的数据集全部来自YouTube真实的视频,是Google发布的AudioSet以及youtube-8m [3]数据库的子集。

难点:1. 数据不均衡。如汽车出现的样本数远远大于滑板车出现的样本数。这种不均衡数据会极大影响网络的训练。2. 训练数据只有句子级的标签而没有帧级的标签,却要在测试集上给出帧级标签。弱标签是大规模音频处理领域中的一个难点。
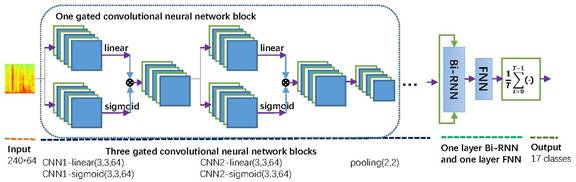
模型
先上系统框架图,我们的基线是卷积循环神经网络Convolutional recurrent neural network (CRNN)。输入的是整个对数梅尔语谱图,最大的创新点是彻底摒弃sigmoid,ReLU等常见激活函数,而采用可以学习的gated linear units (GLU) [4]。所以某个CNN,都有两个模块:一个线性输出和一个GLU的sigmoid输出,该sigmoid输出可看作介于0和1之间的门,即为时频点上的attention,如果该时频点上的值是接近1,即说明该时频点的特征是有用的,会传到下一层;反之如果该时频点上的值接近0,则说明该时频点是噪声或包含无用的信息,不会被传到下一层。
技巧(Trick)
1. Batch Normalization用来稳定并加速训练。
2. 在每个mini-batch中,均衡了样本数据,缓解了数据不均衡问题。
3. 系统融合。
对于第二个弱监督的声学事件检测子任务,我们同样沿用上面的框图,不过在RNN后面的部分稍微做点改变:
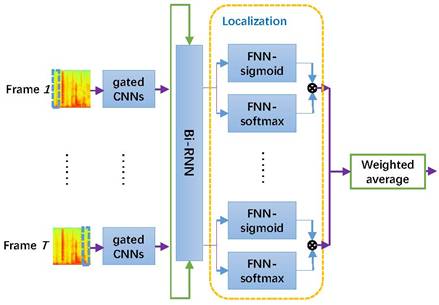
上图是对第一幅图的帧上展开,原先的前向神经网络(FNN)模块,增加一个FNN-softmax模块,称为localization矢量,用以辅助推断当前帧的所属类标签。该方法的有意思的地方在于,我们最终还是用弱标签(句子级标签)训练,用中间变量(每一帧上的分类结果,图中虚线框内)作为声学事件检测结果。此成果曾经由本团队发表在Icassp2017和Interspeech2017上。
GitHub源代码:https://github.com/yongxuUSTC/dcase2017_task4_cvssp
语音识别,目前干净环境下的语音识别准确度已经很高,但在很低信噪比情况下,或多个人讲话的情况下,识别率会大幅下降,这是因为目前的识别器把非语音的都统一归为一类:噪声,实际上现实中的噪声可能比语音还要复杂,如果也能对各种噪声类型建模,将有助于语音识别的改进。
附:技术应用领域
1)智能家居:想象一下,我们白天在公司上班,家中无人,如果能检测到家中发生的异常声学事件,比如:贼破门而入,狗叫,火警,冬天水管爆裂等,那我们就第一时间知道家中险情,此为smarthome。
2)无人驾驶:目前几乎所有的无人驾驶技术都是基于图像,并没有有效利用音频,举一个例子,十米开外拐弯的地方,有一个救护车在叫,摄像头是拍不到的,但麦克风却能听见,如果能检测到救护车的叫声,就可以提前做减速让道的动作。再如周围的车突发鸣笛或行人突发尖叫等等。此为smartcar。
3)声学场景分析:在声源分离领域,有一个重要的概念computational auditory scene analysis (CASA),此概念的一个重要目标,就是将机器人置身于某个声学场景,比如街道的十字路口,他能全盘了解自己所处声学环境,知道各个声源的位置,知道有哪些声源。
Team介绍:
徐勇博士(同等贡献者):现任英国萨里大学博后,中科大博士,美国佐治亚理工学院联合培养博士,两篇IEEE高被引杂志论文作者。基于DNN的语音增强的提出者。论文总引用率600+。DCASE2017 challenge比赛第一名。
孔秋强(同等贡献者):现PhD就读于英国萨里大学,本科硕士毕业于华南理工大学。DCASE2017 challenge比赛第一名。
王文武教授:IEEE高级会员,IEEE TRANSACTIONS ON SIGNAL PROCESSIN副主编,英国萨里大学副教授,Publication Co-Chair of ICASSP 2019
Mark D. Plumbley教授:IEEE和IET Fellow,英国萨里大学教授,英国玛丽皇后大学教授,Tutorial session chair of Icassp2019

AI专家问答平台


