

深度神经网络(DNNs)使计算机能够在许多不同的应用中脱颖而出,如图像分类、语音识别和机器人控制。为了加快DNN的训练和服务,并行计算被广泛采用。向外扩展时,系统效率是一个大问题。在分布式机器学习中,高通信开销和有限的设备上内存是导致系统效率低下的两个主要原因。
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2022/EECS-2022-83.html
本文研究了在分布式机器学习工作负载下,在数据和模型并行性方面减轻通信瓶颈并实现更好的设备上内存利用的可能方法。
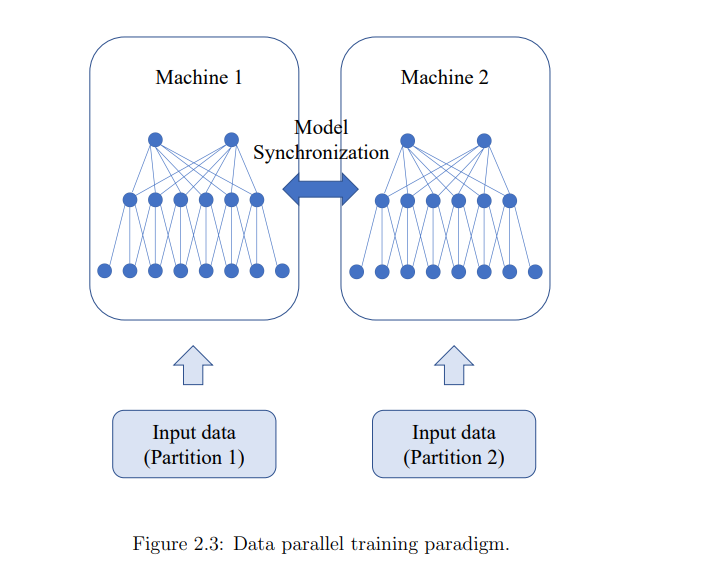
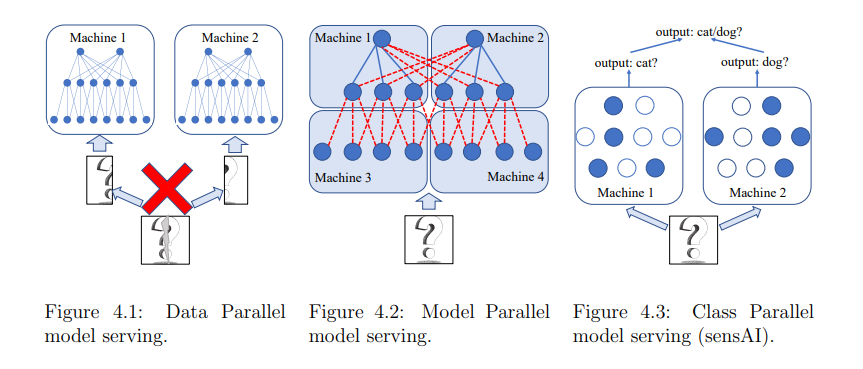
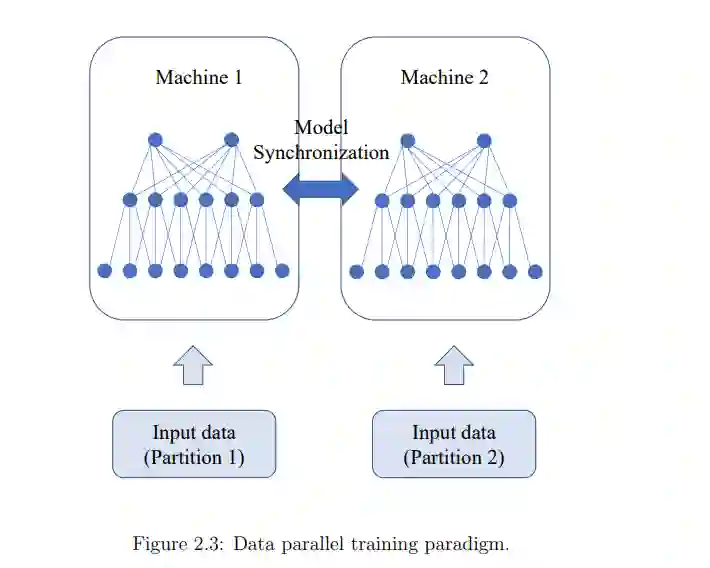
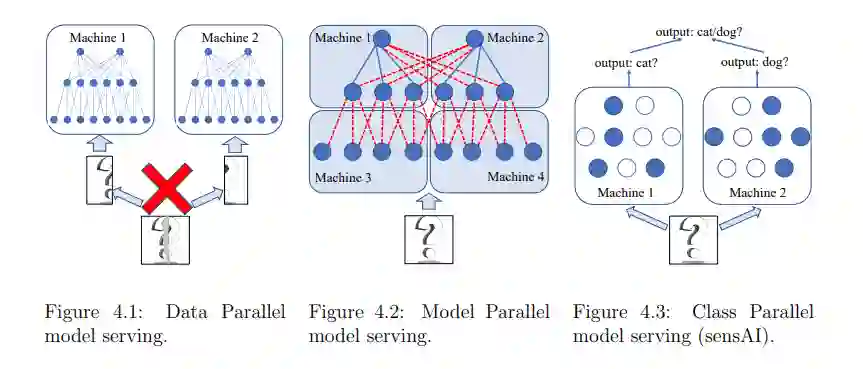
在通信方面,我们的Blink项目缓解了数据并行训练中的通信瓶颈。通过打包生成树而不是形成环,Blink可以在任意网络环境中实现更高的灵活性,并提供近乎最佳的网络吞吐量。为了消除模型并行训练和推理过程中的通信问题,我们从系统层上升到应用层。我们的sensAI项目将多任务模型解耦到断开的子网中,其中每个子网负责单个任务或原始任务集的子集的决策制定。
为了更好地利用设备上的内存,我们的小波项目有意增加任务启动延迟,在加速器上的不同训练任务波之间交错使用内存峰值。通过将多个训练波集中在同一个加速器上,它提高了计算和设备上的内存利用率。



成为VIP会员查看完整内容




相关内容

Arxiv
34+阅读 · 2021年6月2日


相关VIP内容
相关资讯
相关论文
Arxiv
34+阅读 · 2021年6月2日