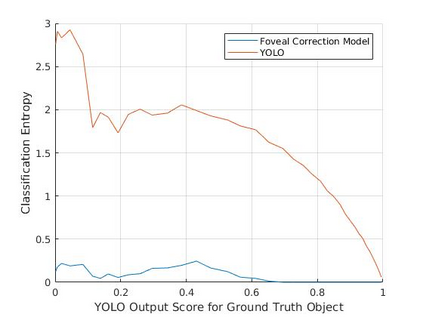
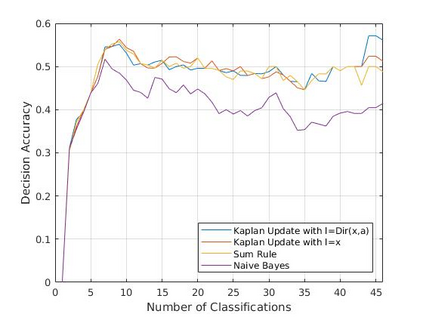
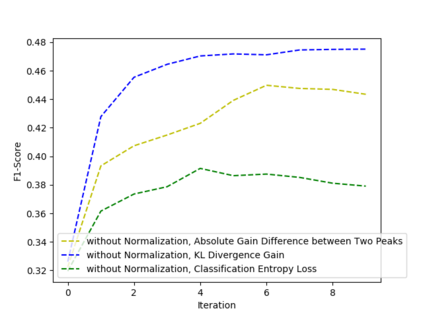
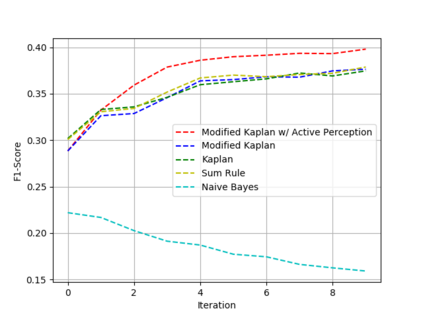
Active perception and foveal vision are the foundations of the human visual system. While foveal vision reduces the amount of information to process during a gaze fixation, active perception will change the gaze direction to the most promising parts of the visual field. We propose a methodology to emulate how humans and robots with foveal cameras would explore a scene, identifying the objects present in their surroundings with in least number of gaze shifts. Our approach is based on three key methods. First, we take an off-the-shelf deep object detector, pre-trained on a large dataset of regular images, and calibrate the classification outputs to the case of foveated images. Second, a body-centered semantic map, encoding the objects classifications and corresponding uncertainties, is sequentially updated with the calibrated detections, considering several data fusion techniques. Third, the next best gaze fixation point is determined based on information-theoretic metrics that aim at minimizing the overall expected uncertainty of the semantic map. When compared to the random selection of next gaze shifts, the proposed method achieves an increase in detection F1-score of 2-3 percentage points for the same number of gaze shifts and reduces to one third the number of required gaze shifts to attain similar performance.
翻译:人类视觉系统的基础就是主动感知和潜伏视觉。 侧面视觉可以减少在凝视固定期间处理的信息量, 主动感知可以将视视方向改变为视觉场中最有希望的部分。 我们提出一种方法, 来模仿人类和机器人如何使用鹅形照相机探索场景, 辨别周围的物体, 以最小的视线变化次数来辨别物体。 我们的方法基于三种关键方法。 首先, 我们取一个现成的深物体探测器, 预先训练一个大型的常规图像数据集, 校准分类输出到变异图像。 其次, 以身体为中心的语义图, 编码对象分类和相应的不确定因素, 与校准的检测结果相继更新, 并参考若干数据融合技术。 第三, 下一个最佳的凝视定点是根据信息理论测量来确定, 目的是尽可能减少预期的语义地图总体不确定性。 与随机选择的正常变形图像相比, 拟议的方法可以增加检测F1核心的输出输出结果, 并按2-3个百分点进行类似变换。