

大语言模型(LLMs)的最新进展显著提升了其执行复杂推理任务的能力,实现了从快速直觉思维(系统1)到缓慢深度推理(系统2)的跨越。 尽管系统2推理能提高任务准确性,但其“慢思考”特性以及低效或不必要的推理行为往往导致巨大的计算成本。相比之下,系统1推理计算效率更高,但性能表现欠佳。因此,如何在性能(收益)与计算成本(预算)之间取得平衡至关重要,这也催生了“推理经济性”的概念。 本综述对LLMs训练后阶段和测试时推理阶段的推理经济性进行了全面分析,涵盖: 1. 推理低效的成因; 1. 不同推理模式的行为分析; 1. 实现推理经济性的潜在解决方案。
通过提供可落地的见解并指出开放挑战,我们旨在为优化LLMs推理经济性的策略提供启示,从而推动这一新兴领域的深入研究。此外,我们开放了一个公共资源库,持续追踪这一快速发展领域的最新进展。
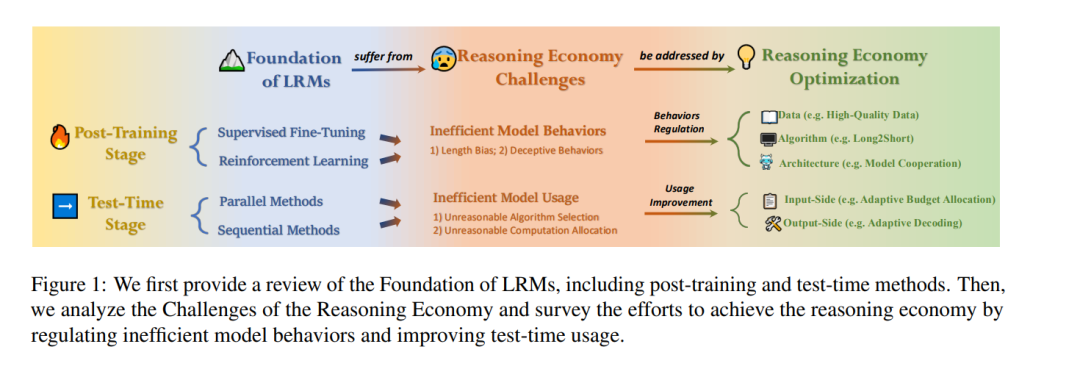
**1 引言
大语言模型(LLMs)在各类语言理解与生成任务中展现出卓越性能,尤其是伴随思维链(Chain-of-Thought, CoT)提示(Wei et al., 2022)技术的出现,该技术要求模型通过显式的分步推理生成最终答案。尽管LLMs在多数场景中表现优异,但其依赖快速直觉思维的机制在面对复杂推理挑战(如高阶数学(AIME, 2025; Zhong et al., 2023)与编程任务)时往往力有不逮。为此,近期研究试图通过慢速深度思考(Wang et al., 2025a)进一步提升LLMs的推理能力,例如OpenAI的o1(OpenAI, 2024)、DeepSeek的R1(DeepSeek-AI et al., 2025)与QwQ(QwQ, 2025)等模型,从而催生了大推理模型(Large Reasoning Models, LRMs)的兴起与推理阶段的新扩展定律(Snell et al., 2024)。 然而,这一进步代价高昂。此类LRMs需耗费显著更长的思考时间以生成冗长的CoT推理链,导致巨大的推理开销。但并非所有任务均需如此深度的思考——任务复杂度各异,若对所有问题采用“一刀切”策略,将造成计算与时间资源的浪费。更甚者,长推理链中的大量标记(tokens)往往对最终答案无实质贡献。研究发现,LRMs常将过量资源(Wu et al., 2025; Cuadron et al., 2025)浪费于无效思考(如“过度思考”),却未为真正困难的问题分配足够算力(如“思考不足”)(Snell et al., 2024; Wang et al., 2025e)。 能力与效率的失衡引出了一个核心挑战——实现推理经济性(Reasoning Economy),即通过优化标记使用(预算)、减少冗余步骤、动态调整算力分配,达成全局最优解。这不仅可提升LRMs的效率,还能像人类一样“智能”地停止或深入思考(Aggarwal et al., 2023; Kimi Team et al., 2025),充分释放模型潜力。随着推理经济性日益重要,亟需系统性地理解LRMs的推理行为、揭示高效化面临的挑战,并明确解决方案。 本综述首次对LRMs的推理经济性进行全面系统的梳理。具体而言,我们首先建立LRMs的理论基础(§2),解析训练后方法(§2.1)(如监督微调与强化学习)如何塑造推理行为,以及测试时策略(§2.2)(如并行与序列化推理)如何影响模型表现。基于此,我们深入分析推理经济性的挑战(§3),将其归类为模型自身的低效行为(§3.1)或测试时的低效使用(§3.2)。最后,我们从两方面探讨优化推理经济性的解决方案: 1. 训练后行为调控(§4):从数据、算法乃至模型架构源头修正不良推理模式; 1. 测试时动态计算适配(§5)。 此外,我们讨论了开放挑战并展望未来研究方向(§6)。通过提供清晰的结构化路线图,本研究旨在为推动更可持续的LRMs发展提供可落地的指导。
