

摘要实现人类水平智能需要优化从快速、直觉的系统1到更慢速、更审慎的系统2推理的过渡。系统1擅长快速、启发式决策,而系统2则依赖逻辑推理以实现更准确的判断并减少偏见。基础大语言模型(LLMs)在快速决策方面表现出色,但由于尚未完全具备真正的系统2思维所特有的逐步分析能力,其在复杂推理方面仍显不足。最近,诸如OpenAI的o1/o3和DeepSeek的R1等推理大语言模型在数学和编程等领域展现了专家级的表现,高度模拟了系统2的审慎推理,并展示了类人的认知能力。本文首先简要回顾了基础大语言模型的进展以及系统2技术的早期发展,探讨了它们的结合如何为推理大语言模型铺平道路。接着,我们讨论了如何构建推理大语言模型,分析了其特点、实现高级推理的核心方法以及各类推理大语言模型的演变。此外,我们还概述了推理基准测试,并对代表性推理大语言模型的性能进行了深入比较。最后,我们探讨了推动推理大语言模型发展的潜在方向,并维护了一个实时GitHub仓库以跟踪最新进展。我们希望本文能为这一快速发展的领域提供有价值的参考,激发创新并推动进步。
https://arxiv.org/abs/2502.17419 关键词:慢思考、大语言模型、类人推理、人工智能决策、通用人工智能 1 引言
“不要教授,激励。” —Hyung Won Chung, OpenAI 实现人类级别的智能需要精炼从系统1到系统2推理的过渡[1]–[5]。双系统理论表明,人类认知通过两种模式运作:系统1,它快速、自动、直觉,能够以最小的努力做出快速决策;系统2,它较慢、更具分析性和深思熟虑[6],[7]。尽管系统1在处理常规任务时效率较高,但它容易受到认知偏差的影响,特别是在复杂或不确定的情境中,导致判断错误。相比之下,系统2依赖于逻辑推理和系统化思维,能够做出更加准确和理性的决策[8]–[11]。通过减轻系统1的偏差,系统2提供了一种更为精细的问题解决方法[12]–[15]。 基础大语言模型(LLMs)的发展标志着人工智能(AI)领域的一个重大里程碑。像GPT-4o[16]和DeepSeekv3[17]等模型,在文本生成、语言翻译和各种感知任务方面展示了令人印象深刻的能力[18]–[28]。这些模型经过广泛数据集的训练,并利用先进的算法,能够理解并生成类人回应。然而,尽管这些基础LLM取得了令人瞩目的成就,它们的运作方式类似于系统1推理,依赖于快速、启发式的决策过程。虽然它们在提供快速回应时表现出色,但在需要深度逻辑分析和复杂推理任务中的精准度时往往表现不佳。这个局限性在涉及复杂问题解决、逻辑分析或微妙理解的情境中尤为明显,因为这些模型尚未达到人类的认知能力。 相比之下,推理型LLM代表了语言模型演变的重要进展。像OpenAI的o1/o3[29],[30]和DeepSeek的R1[31]等模型,旨在模拟与系统2思维相关的较慢、更深思熟虑的推理过程。与基础LLM不同,推理型LLM配备了逐步处理信息的机制,使其能够做出更为准确和理性的决策。这种从快速直觉型处理到更有条理的推理驱动型模型的转变,使推理型LLM能够处理复杂任务,如高级数学[32]–[37]、逻辑推理[38]–[44]和多模态推理[45]–[47],并表现出类人级的认知能力。因此,推理型LLM被越来越多地认为能够实现深度逻辑思维,处理那些曾被认为超出AI能力范围的任务。推理型LLM的最新发展时间线如图1所示。
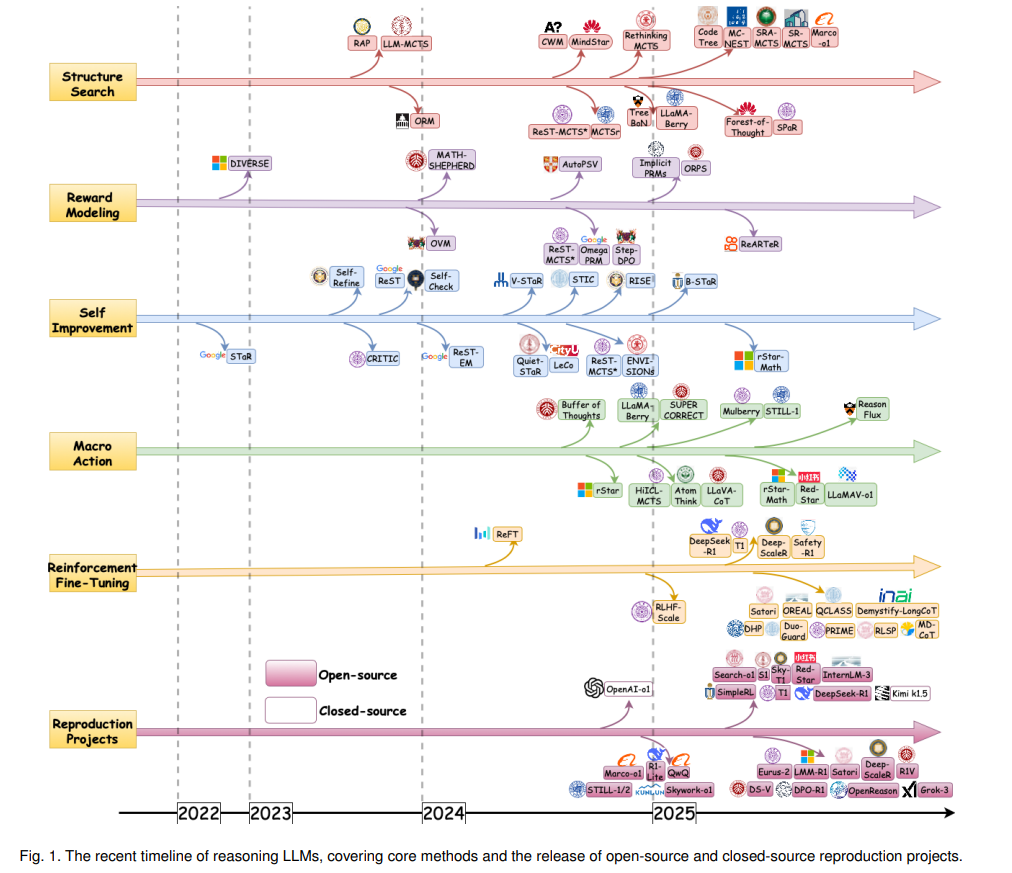
1.1 综述结构
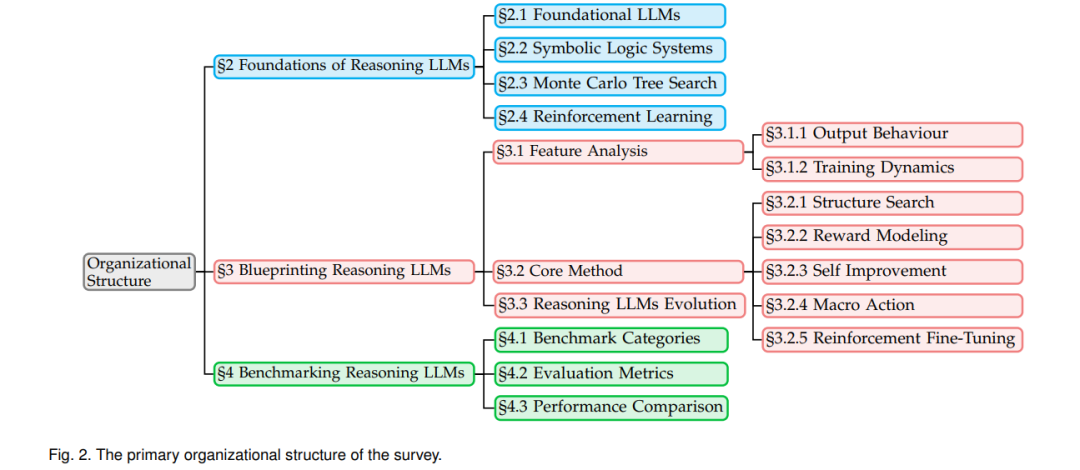
本综述提供了关于推理型LLM发展中的关键概念、方法和挑战的全面概述。如图2所示,本综述结构如下:
- 第2节简要回顾了基础LLM的进展(第2.1节),以及系统2关键技术的早期发展,包括符号逻辑系统(第2.2节)、蒙特卡洛树搜索(MCTS)(第2.3节)和强化学习(RL)(第2.4节),重点介绍了它们的结合如何为推理型LLM铺平道路。
- 第3节介绍了推理型LLM,并概述了其构建过程。具体而言,第3.1节从输出行为(第3.1.1节)和训练动态(第3.1.2节)两个角度呈现推理型LLM的特点,强调它们与基础LLM的区别。第3.2节识别了实现高级推理能力所需的核心方法,重点介绍五个方面:结构搜索(第3.2.1节)、奖励建模(第3.2.2节)、自我改进(第3.2.3节)、宏观动作(第3.2.4节)和强化微调(第3.2.5节)。每个部分深入探讨了这些方法的具体特点,并介绍了代表性推理型LLM。第3.3节追溯了推理型LLM的发展阶段。
- 第4节评估了代表性的推理型LLM。具体而言,第4.1节回顾了当前主流推理基准,涵盖了文本和多模态基准,涉及各种任务类型。第4.2节概述了当前的评估指标,第4.3节基于这些基准分析并比较了主流推理型LLM与基础LLM的性能。
- 第5节强调了现有推理型LLM的局限性,并概述了这些模型的若干有前景的未来发展方向。
- 最后,在第6节中总结了本文,并提供了一个实时跟踪GitHub仓库,供用户关注该领域的最新进展。我们希望本综述能够作为一个宝贵的资源,促进这一快速发展的领域的创新和进步。
1.2 综述的贡献
近年来,已经进行了一些特定技术方法的分析和复制[48]–[55],然而,缺乏系统的分析和组织。研究[56]仅专注于测试过程中慢思维的方法。与此同时,研究[57]–[59]主要集中在训练或实现推理型LLM,通常从强化学习的角度进行探讨。 我们的综述与现有文献的不同之处及贡献在于:
- 我们没有专注于单一技术方法,而是提供了推理型LLM的关键概念、方法和挑战的全面概述。
- 我们总结了早期系统2的关键进展,并阐述了它们如何与基础LLM结合,为推理型LLM铺路——这是之前文献中常被忽视的关键方面。
- 我们提供了更为彻底和全面的核心方法总结,这些方法对于构建推理型LLM至关重要,包括但不限于强化学习(RL)。
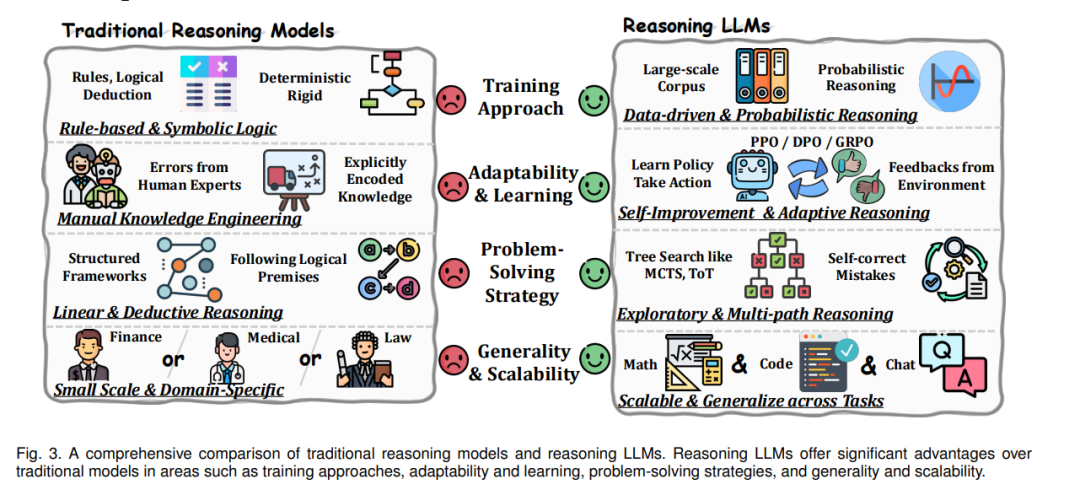
3. 推理大语言模型的构建
在本节中,我们首先从输出行为和训练动态两个角度分析了推理大语言模型的特征。然后,我们详细介绍了实现其高级推理能力的核心方法。最后,我们总结了推理大语言模型的演变。3.1 推理大语言模型的特征分析3.1.1 输出行为视角探索与规划结构:最近的实证研究表明,推理大语言模型在其输出结构中表现出强烈的探索行为,特别是在与WizardMath和DeepSeekMath等主要依赖传统链式思维(CoT)推理方法的模型相比时。这种探索行为体现在新假设的制定和替代解决路径的追求上。验证与检查结构:对OpenAI的o1和o3模型的分析表明,它们的推理框架结合了长期战略规划的宏观行动和包括“等待”、“暂停”、“替代”和“让我们暂停”等微观行动。这些微观行动促进了细致的验证和迭代检查过程,确保任务执行的精确性。更长的推理长度与时间:最近的研究表明,推理大语言模型通常生成超过2000个标记的输出以解决复杂的编程和数学问题。然而,这种延长的输出长度有时会导致过度思考,模型在问题上花费过多时间而不一定能改进解决方案。3.1.2 训练动态视角惊人的数据效率:与专注于扩展指令集的传统方法不同,研究表明,构建专注于困难样本的慢思维链式思维(Slow-thinking CoT)数据集在医学和数学等领域具有更好的泛化能力。稀疏训练方法:与传统观点相反,开发有效的推理大语言模型并不需要大量的数据集或密集的奖励信号。例如,STILL2仅使用5000个蒸馏样本就展示了令人印象深刻的性能,而Sky-T1仅使用17000个长链式思维样本就实现了与QwQ相当的性能。参数特征:通过长链式思维方法训练的大语言模型在不同层中表现出相对均匀的梯度范数。相比之下,快速思维(如简化的链式思维方法)在早期层中产生较大的梯度幅度,并且在不同层中的梯度范数存在显著差异。 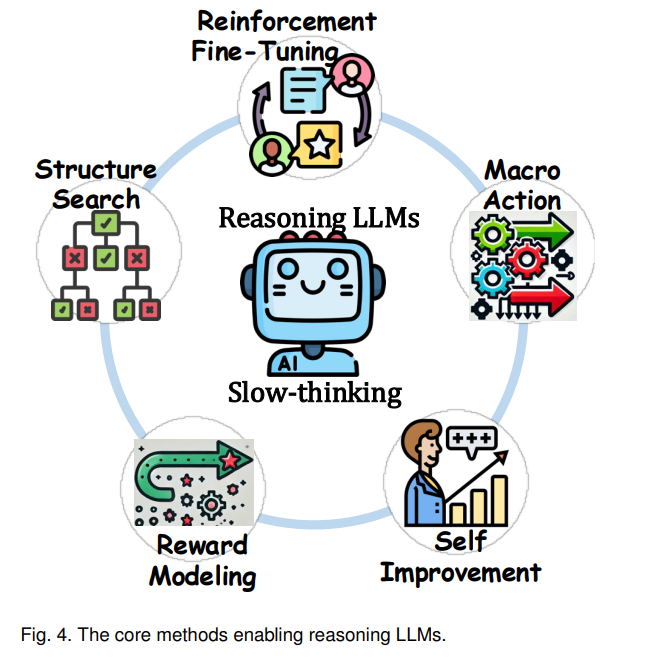
4. 推理大语言模型的基准测试
开发一个强大的基准对于记录推理大语言模型能力的进展并确定未来进展的有前景的研究方向至关重要。在这里,我们从类别、评估指标和性能比较三个方面回顾了基准,同时提供了我们的反思和见解。4.1 基准类别我们按任务类型对推理基准进行分类,可以大致分为数学、代码、科学、代理、医学和多模态推理。这些基准的详细统计数据如表VI所示。4.1.1 基准介绍数学问题:我们记录了当前流行的竞赛级数学基准,以展示推理大语言模型的能力,包括AIME 2024、MATH-500、AMC 2023和Olympiad Bench。代码问题:代码问题需要扎实的基础和高逻辑思维来评估推理大语言模型的推理能力,如Codeforces、SWEbench和LiveCodeBench。科学问题:科学基准,如GPQA Diamond和MMLU-Pro,涉及化学、生物学和物理学的多领域推理,需要广泛的知识积累和综合推理。代理推理:现实任务通常涉及复杂的规划和工具使用,导致了代理推理基准的创建,如WebShop和WebArena。医学推理:医学本质上涉及复杂的推理,涵盖从诊断决策到治疗计划的任务。JAMA Clinical Challenge、Medbullets和MedQA等基准提供了模仿医生疾病诊断的模型测量。多模态推理:多模态推理,如MMMU和MathVista基准,需要结合文本和图像的跨模态思维。4.1.2 总结大语言模型领域近年来发展迅速,基准性能不断提高。简单的推理基准,如GSM8K、MATH-500和ScienceQA,已经接近性能饱和。最近对推理大语言模型的研究表明,为长推理链设计的模型在这些基准上并不显著优于为短链设计的模型。这突显了建立新基准的迫切需要,以更有效地评估推理大语言模型的推理能力。此外,当前的基准主要集中在硬推理任务上。软推理基准缺乏明确定义的正确答案,提供了更细致的评估,更好地捕捉了类人推理的复杂性和微妙性。4.2 评估指标根据任务类型、技术方案和推理范式,引入了各种评估指标来衡量推理大语言模型在处理复杂推理任务中的表现,确保生成解决方案的质量和连贯性得到有效衡量。
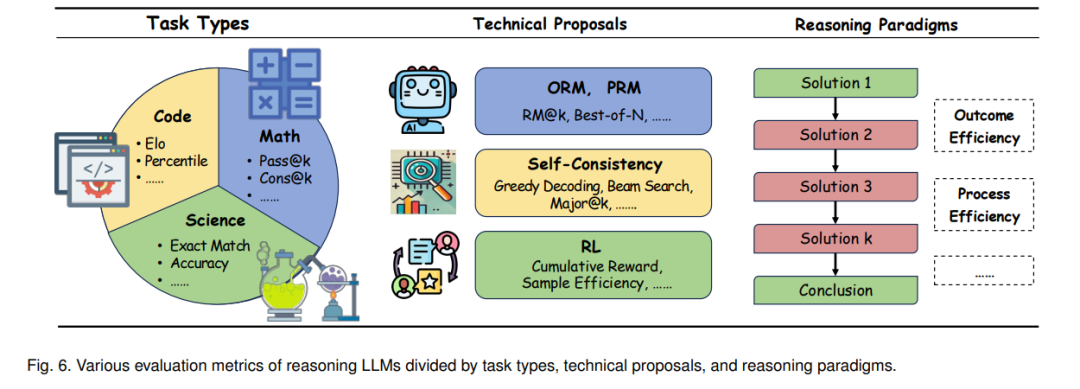
4.2.1
任务类型在基准类别方面,数学推理通常使用两个主要指标:Pass@k和Cons@k。Pass@k指标评估模型在k次尝试内生成正确解决方案的能力,衡量在有限尝试次数内成功的可能性。另一方面,Cons@k评估模型是否一致地生成正确或逻辑连贯的解决方案,突出其推理能力的稳定性和可靠性。对于代码任务,关键指标是Elo和Percentile,两者都衡量生成正确代码的相对技能。在科学任务中,评估通常使用Exact Match(EM)和Accuracy来评估填空题和选择题。
4.2.2 技术方案基于技术路线,使用ORM或PRM的方案通常利用RM@k和Best-of-N两个评估指标。RM@k衡量奖励模型是否能够根据奖励分数在k个候选答案中将好的答案排名更高,Best-of-N从N个生成的推理轨迹中选择得分最高的解决方案。自我一致性方法使用Greedy Decoding、Beam Search和Major@k进行评估。4.2.3 推理范式对于推理大语言模型中的多轮解决方案生成,最近提出了Outcome Efficiency和Process Efficiency来评估长思维的具体效率。Outcome Efficiency指标经验性地评估后续解决方案对准确性改进的贡献,Process Efficiency指标经验性地评估后续解决方案对解决方案多样性的贡献。4.2.4 总结大多数现有的评估指标都是根据最终答案来判断的。鉴于大推理计算消耗,开发一个综合考虑推理过程各个方面的全面评估框架势在必行。当前流行的评估框架,如LMMs-Eval、OpenCompass和PRMBench,缺乏效率,其指标未能充分考虑到推理过程的计算和时间效率。为了解决这些不足,我们强烈建议探索更高效的代理任务作为潜在解决方案。4.3 性能比较在本节中,我们比较了不同推理大语言模型及其对应基础大语言模型在纯文本基准(如数学和代码问题)以及多模态基准上的性能。4.3.1 纯文本基准上的性能如表VII所示,推理大语言模型如DeepSeek-R1和OpenAI的o1/o3在广泛的数学、编码和其他一般任务中表现出色。这些模型在AIME 2024、MATH-500和LiveCodeBench等多个纯文本基准上取得了高分,展示了其强大的文本推理能力。相比之下,基础大语言模型如GPT-4o、Claude-3.5-Sonnet和DeepSeek-V3在数学和编码任务(如AIME 2024和Codeforces)中表现较差。4.3.2 多模态基准上的性能如表VIII所示,推理大语言模型在多模态任务中继续表现出色。OpenAI的o1在视觉任务中表现强劲,在MMMU上取得了77.3%的最高分,并在MathVista上比其对应的基础大语言模型GPT-4o高出7.2%。然而,与纯文本任务相比,多模态任务的性能提升不那么显著。4.3.3 总结总的来说,推理大语言模型在纯文本和多模态基准上都表现出色,特别是在数学和编码任务中,它们大幅超越了基础大语言模型。尽管多模态任务的改进不如纯文本任务显著,但推理大语言模型仍然超越了其对应模型,突显了其在处理图像和文本数据方面的潜力。这些结果强调了推理大语言模型在广泛推理任务中的多功能性和有效性,具有在多模态推理技术方面进一步发展的潜力。5. 挑战与未来方向尽管推理大语言模型取得了快速进展,但仍存在一些挑战,限制了它们的通用性和实际应用。本节概述了这些挑战,并强调了解决这些挑战的潜在研究方向。5.1 高效的推理大语言模型虽然推理大语言模型通过扩展推理在解决复杂问题方面表现出色,但它们在大规模架构中依赖长自回归推理带来了显著的效率挑战。例如,Codeforces等平台上的许多问题需要超过10000个标记的推理,导致高延迟。正如[102]所指出的,即使推理大语言模型早期识别出正确的解决方案,它通常也会花费大量时间验证其推理。未来的研究应集中在两个关键领域:(1)整合外部推理工具以实现早期停止和验证机制,从而提高长推理链的效率;(2)探索在不牺牲性能的情况下在小型大语言模型(SLMs)中实现慢思维推理能力的策略。5.2 协同慢思维与快思维系统推理型LLM面临的一大挑战是失去快速思维能力,这导致在简单任务中需要不必要的深度推理,造成效率低下。与人类能够流畅地在快思维(系统1)和慢思维(系统2)之间切换不同,当前的推理型LLM在保持这种平衡方面存在困难。虽然推理型LLM确保了深思熟虑和全面的推理,但快思维系统依赖于先前的知识以提供快速回应。尽管有如系统1-2切换器[95]、推测解码[258]–[260]和互动持续学习[261]等努力,整合两种思维模式仍然是一个挑战。这通常导致在领域特定任务中的低效以及在更复杂情境下未能充分利用系统的优势。未来的研究应聚焦于开发自适应切换机制、联合训练框架和共进化策略,以调和快思维系统的效率与推理型LLM的精确度。实现这种平衡对于推动这一领域的发展并创建更加多功能的AI系统至关重要。5.3 推理型LLM在科学中的应用推理型LLM在科学研究中扮演着至关重要的角色[262],它们能够进行深度、结构化的分析,超越了基于启发式的快思维模型。它们的价值在需要复杂推理的领域,尤其是在医学和数学领域中尤为明显。在医学中,特别是在鉴别诊断和治疗规划方面,推理型LLM(例如推理时间缩放)增强了AI的逐步推理能力,提高了诊断准确性,而传统的缩放方法往往力不从心[52]。在数学中,像FunSearch[263]这样的方式结合了慢思维原则,推动了超越以往发现的进展,展示了AI与人类协作的潜力。在这些领域之外,推理型LLM还能够通过改进模型构建和假设检验,推动物理学、工程学和计算生物学的进步。投资推理型LLM的研究不仅架起了AI的计算能力与类人分析深度之间的桥梁,还为更可靠、可解释且突破性的科学发现铺平了道路。5.4 神经与符号系统的深度融合尽管推理型LLM取得了显著进展,但它们的透明度和可解释性的限制仍然制约了它们在更复杂现实世界推理任务中的表现。对大规模数据模式的依赖和缺乏清晰的推理路径,使得处理复杂或模糊问题变得具有挑战性。早期的符号逻辑系统,尽管适应性较差,但提供了更好的可解释性和更清晰的推理步骤,在这类问题中表现得更可靠。未来一个有前景的方向是神经与符号系统的深度融合。谷歌的AlphaGeometry[264]和AlphaGeometry2[265]将推理型LLM与符号引擎相结合,在国际数学奥林匹克(IMO)中取得了突破性进展。特别是,AlphaGeometry2利用基于Gemini的模型[249],[266],[267]和更高效的符号引擎,通过减少规则集并改进关键概念处理,提升了性能。该系统现在覆盖了更广泛的几何概念,包括轨迹定理和线性方程。新的搜索算法和知识共享机制加速了这一过程。该系统解决了84%的IMO几何问题(2000-2024),超过了金牌得主的平均成绩。相比之下,像OpenAI-o1[29]这样的推理型LLM未能解决任何问题。神经与符号系统的融合提供了一种平衡的方法,提高了适应性和可解释性,对于超越数学几何问题的复杂现实世界推理任务具有巨大潜力。5.5 多语言推理型LLM当前的推理型LLM在英语和中文等高资源语言中表现良好,展示了在翻译和各种推理任务中的强大能力[93],[101]。这些模型在大规模数据和多样语言资源可用的环境中表现突出。然而,它们在低资源语言中的表现仍然有限[268],面临数据稀缺、稳定性、安全性和整体性能等挑战。这些问题阻碍了推理型LLM在缺乏大量语言数据集和资源的语言中的有效性。未来的研究应优先解决低资源语言中数据稀缺和文化偏见带来的挑战。创新方法如跨推理型LLM的参数共享和领域特定知识的增量注入,可能有助于缓解这些挑战,从而加速慢思维能力在更广泛语言中的适应。这不仅能够提升推理型LLM在这些语言中的效果,还能够确保更公平地访问先进的AI技术。5.6 多模态推理型LLM将慢思维推理能力从基于文本的领域扩展到多模态上下文仍然是一个重大挑战,特别是在需要精细感知的任务中[96]。虽然像Virgo[269]这样的方式已经尝试将基于文本的慢思维推理转化为多模态LLM,但它们在需要详细视觉理解的任务,如MathVision[241]中的表现提升有限。关键的研究方向包括开发层次化推理型LLM,以实现精细的跨模态理解和生成,针对音频、视频和3D数据等模态的独特特性进行定制。5.7 安全推理型LLM推理型LLM如OpenAI-o1[29]和DeepSeek-R1[31]的快速发展导致了超智能模型的崛起,这些模型能够进行持续的自我进化。然而,这一进展也带来了安全性和控制方面的挑战。强化学习(RL)作为一种关键训练方法,引入了如奖励黑客、泛化失败和语言混合等风险,这可能导致有害的结果。确保这些系统(如DeepSeek-R1)的安全性变得迫在眉睫。虽然强化学习增强了推理能力,但其不可控的性质引发了如何安全引导这些模型的担忧。SFT在一定程度上解决了一些问题,但并不是完整的解决方案。需要结合RL和SFT的混合方法,以减少有害输出,同时保持模型的有效性[270]。随着这些模型超越人类认知能力,确保它们的安全、负责任和透明使用变得至关重要。这需要持续的研究,开发控制和引导它们行为的方法,从而在AI能力与伦理决策之间找到平衡。6 结论本文提供了推理型LLM研究的全面综述。我们首先回顾了基础LLM的进展以及系统2关键技术的早期发展,包括符号逻辑、蒙特卡洛树搜索(MCTS)和强化学习(RL),探讨了这些技术如何与基础LLM结合,为推理型LLM铺平道路。然后,我们详细分析了最新推理型LLM的特征,考察了使其具备高级推理能力的核心方法,并突出介绍了代表性模型。通过对主流推理基准和性能比较的回顾,我们为该领域的现状提供了有价值的见解。展望未来,我们识别了有前景的研究方向,并通过我们的实时GitHub仓库持续跟踪最新进展。本综述旨在激发创新,并推动推理型LLM这一快速发展的领域的进步。

